Android安全-Base64 编码原理 && 实现
推荐 原创在本章,我们将开启新的篇章去介绍加解密算法。在众多的商用APP中,混杂着多种算法去实现接口的参数的加密,以及各种位置的鉴权操作。即使厂商把一系列算法做了混合的使用,我们也不用去惧怕,接下来的几章中,笔者将会带领大家把这些常用的加解密算法各个击破。
万变不离其宗,不管算法如何去改变,只是形式上的改变,我们掌握其核心,让算法对我们来说不再陌生。更着笔者,让我们一起把算法打下来。
6.1 算法基本介绍
6.1.1 逆向场景中的加解密算法
在安全工程中,主要有如下几个逆向场景:
- CTF 挑战赛
- 爬虫
- 安全防护
这里,我们着重讲解爬虫和安全防护,当前主流业务都是围绕这两个方面展开,它们就好像矛与盾的关系。
在爬虫方面,随着更多爬虫工作者的加入,很多APP的服务器被爬到宕机,以及APP内部的公民个人信息会被不法分子非法抓取。为了对抗这些操作,APP内部的防护也越来越强,最主要的表现形式就是算法的加持。那爬虫工作者想要继续爬取数据,那么破解算法并还原,就成为了必备技能。
在安全防护端:要对抗爬虫和非法入侵的危险,在APP的业务代码开发完成后,就要对APP的核心业务逻辑上加入算法去保护相关的接口。
6.1.2 算法的简单分类
这里,笔者对目前市面上主流的算法做了简单的分类:
- 常用编码
Base16、Base32、Base64
哈希算法(散列算法)
- MD5
- SHA-1
- SHA-2 (SHA-224、SHA-256、SHA-384、SHA-512)
对称加解密算法
- DES
- 3DES
- AES
接下来,将会对这些算法各个击破,从原理出来,带领大家去把它们用Android中实现一遍。所谓,正向的高度决定着逆向的高度。
6.2 Base 64 基本介绍
6.2.1 Base 64 简介
首先,我们先介绍算法的好伴侣Base64。其中64,表示的就是使用64个常见的可打印字符来表示二进制数据的一个table,它们分别是A-Z、a-z、+、/,表的形式如图6-1所示:
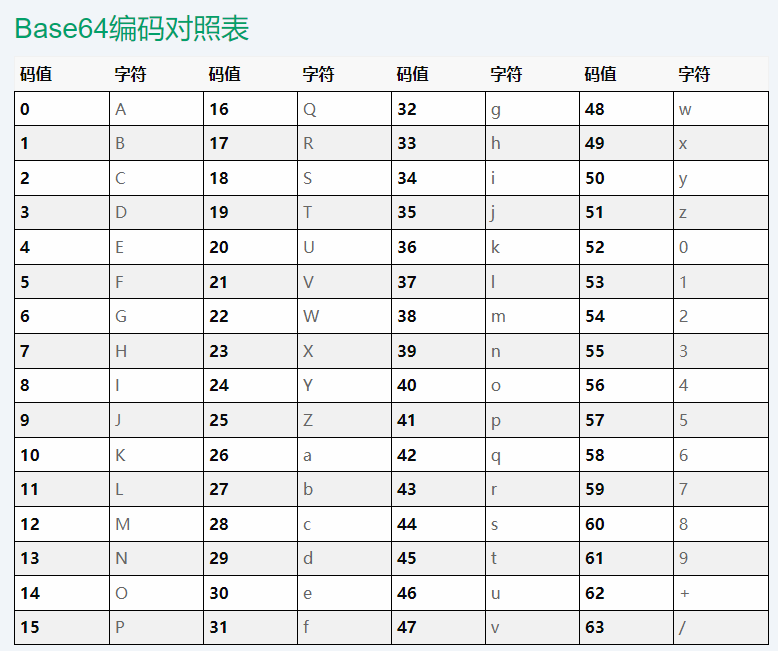
图6-1 Base64 码表
64对应的及计算方式如下:
2^6 = 64
ascii一个字符,是用8个bit来表示,而Base64就是使用6个bit来表示一个字符。3个字节,即24个bit,对应的就是4个Base64的字符单元,所以它们就是用3个字节来表示4个可打印的字符来表示。
6.2.2 Base 64 使用场景
Base64最早是应用于邮件传输协议中,在邮件传输协议中只支持ascii字符的传输。因此,如果想要传递二进制文件,如图片或者视频数据,显然是不可能实现的。那么想要传递,就要把图片或者视频数据转化成ascii字符进行传输。一直以来,最主流的编码就是ascii编码,为了适用于广泛的的编码规格。
然而,ascii的128~255之间的值是不可见字符。而在网络上做数据交换的时候,中间要经过多个路由器,由于不同的设备,厂商的设定对字符的解码格式也是各不相同,那么这些不可见字符,就有可能被错误的处理。这就很不利于传输。
不可见字符就是一切的关键,在很多算法中,算法对数据进行加密后,那么每个单元中的,就有可能存在不可见的字符,那么我们想要对其进行稳定的传输,就一定要使用Base64。
6.3 Base 64 原理详解
6.3.1 Base 64 编码原理
在前面6.2.1简介中简单的介绍了Base64的简单计算方式,但是,对大家来说不太直观。接下来使用图的方式给大家介绍。
在Base64编码时,每3个字节为一组,共有8bit*3=24bit的数据。那么Base64是使用6bit表示一个字节,那么24/6=4个字符。划分前后它们的表现形式如图6-2所示:
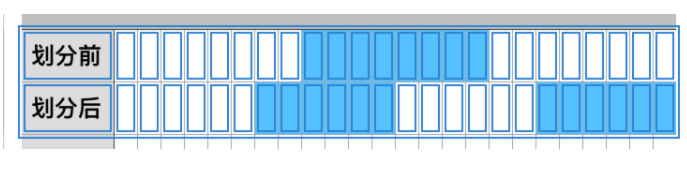
图6-2 划分前后比对
如果这样仍然不直观,我们举个例子,我们对cat进行编码:它的ascii编码,二进制表示,对应的Base64编码表的索引,Base64编码后的内容如图6-3所示:
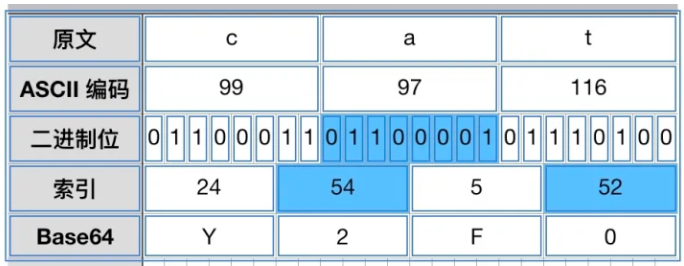
图6-3 Base64编码案例
二进制位编码计算如图6-4所示:
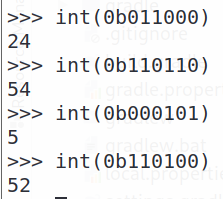
图6-4 Base64编码计算方式
24bit的二进制数据顺次6bit一组进行10进制转换,然后再码表中根据索引得到相应的Base64字符。
最终,cat通过Base64编码变成了Y2F0。如果待转换的字符不是3的整数倍的时候该怎么处理呢?
- 剩余一个字符
在只剩下一个字符的情况下,如图6-5所示:
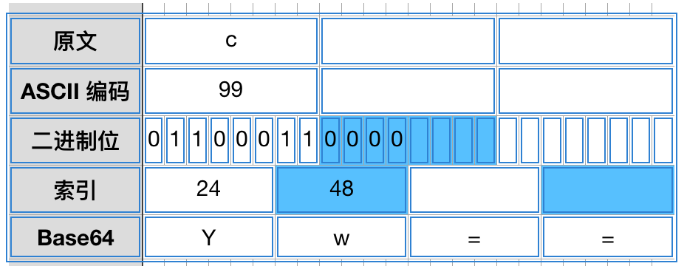
图6-5 只剩下一个字符
在图中,只有一个字符c,它的二进制表现形式为
|
1
|
01100011
|
要进行bit拆分
|
1
|
011000
11
|
但是11不够6个bit,那么就要进行补0的操作,这时候要补充4个0。补充完成后,Base64编码只有两个字节为了满足4个字节,要用"="来补充。最终的编码后的字符就是YW==。我们也可以用在先的网站验证一下。验证结果如图6-6所示:
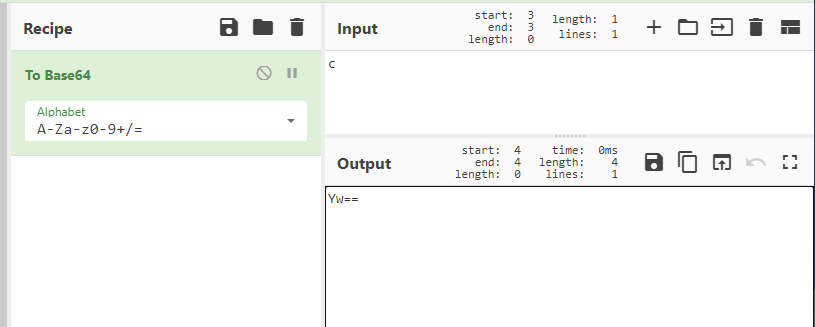
图6-6 只剩下一个字符结果验证
- 剩余两个字符
如果只剩下两个字符,它的编码转换如图6-7所示:
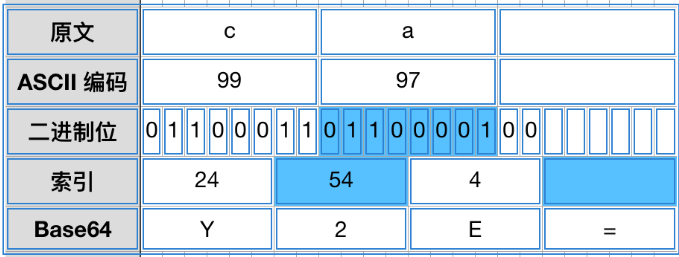
图6-7 只剩下两个字符
两个字符c的二进制表示如下所示:
|
1
|
01100011
01100001
|
进行Base64拆分后,如下所示:
|
1
|
011000
110110
0001
|
这时候最后一个可表示的字符少2个bit去表示,这时候补0即可。补充完0后需要,还少一个Base64字符表示。同样,用"="号表示即可。使用在线网站验证截图如图6-8所示:
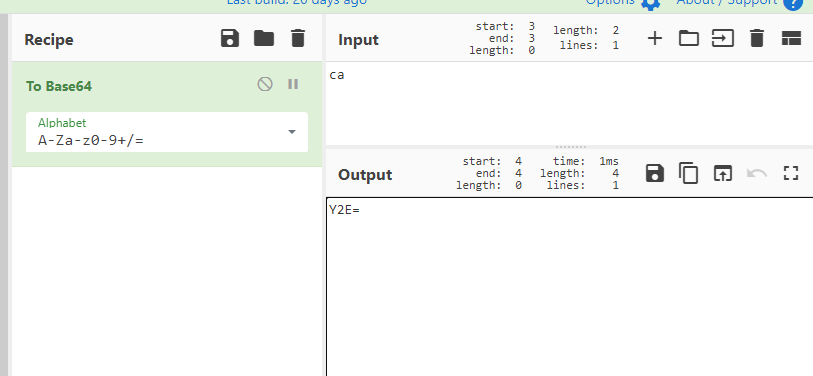
图6-8 只剩下两个字符验证结果
6.3.2 Base64 解码原理
Base64的解码是编码的逆过程,当然在这个过程,引入了一个解码表,配合着去解码。接下来我们就看看怎么去解码。
首先,先介绍下解码表,解码表如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
{
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
62
,
255
,
255
,
255
,
63
,
52
,
53
,
54
,
55
,
56
,
57
,
58
,
59
,
60
,
61
,
255
,
255
,
255
,
254
,
255
,
255
,
255
,
0
,
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
,
10
,
11
,
12
,
13
,
14
,
15
,
16
,
17
,
18
,
19
,
20
,
21
,
22
,
23
,
24
,
25
,
255
,
255
,
255
,
255
,
255
,
255
,
26
,
27
,
28
,
29
,
30
,
31
,
32
,
33
,
34
,
35
,
36
,
37
,
38
,
39
,
40
,
41
,
42
,
43
,
44
,
45
,
46
,
47
,
48
,
49
,
50
,
51
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
};
|
解码表共有256个值,计算方式如下所示:
|
1
|
2
^
8
=
256
|
这是因为ascii的码值是用8bit来表示,而Base64编码后的值,我们仍把它看作是ascii。
用上面编码好的案例给大家讲解。cat编码后的结果是Y2F0。
它们的进制表示如下所示:
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| Base64 字符 | Y | 2 | F | 0 |
| ascii 码值 | 89 | 50 | 70 | 48 |
那么,我们就看下它们是怎么对应的,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
>>> lst
=
[
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
62
,
255
,
255
,
255
,
63
,
52
,
53
,
54
,
55
,
56
,
57
,
58
,
59
,
60
,
61
,
255
,
255
,
255
,
254
,
255
,
255
,
255
,
0
,
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
,
10
,
11
,
12
,
13
,
14
,
15
,
16
,
17
,
18
,
19
,
20
,
21
,
22
,
23
,
24
,
25
,
255
,
255
,
255
,
255
,
255
,
255
,
26
,
27
,
28
,
29
,
30
,
31
,
32
,
33
,
34
,
35
,
36
,
37
,
38
,
39
,
40
,
41
,
42
,
43
,
44
,
45
,
46
,
47
,
48
,
49
,
50
,
51
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
]
>>>
len
(lst)
256
>>> lst[
89
]
24
>>> lst[
50
]
54
>>> lst[
70
]
5
>>> lst[
48
]
52
|
取出来的值正好是Base64码表中的索引值,然后我们把索引值转换成二进制,然后再依次还原就是原始的数据了。
6.4 Base 64 Java 层实现
Java层的实现,直接调用系统库的API即可,没有任何难度。对抗的难度提升一般在Native,这里简单演示下使用方法。
|
1
2
3
4
5
6
|
String
str
=
"qwertyuiopasdfghjklzxcvbnm0123456789~!@#$%^&*()_+`¥……——+|《》?,./城市 姓名"
;
byte[] byteStr
=
str
.getBytes(
"utf-8"
);
String encode_DEFAULT
=
Base64.encodeToString(byteStr,Base64.DEFAULT);
String encode_NO_PADDING
=
Base64.encodeToString(byteStr,Base64.NO_PADDING);
String encode_NO_WRAP
=
Base64.encodeToString(byteStr,Base64.NO_WRAP);
String encodeURL_SAFE
=
Base64.encodeToString(byteStr,Base64.URL_SAFE);
|
6.5 Base 64 使用 C++ 在 Native 层实现
6.5.1 Base 64 编码实现
Native层使用C++来实现,新的android studio 默认语言就是C++。我们先直接看下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
void base64_encode(const char
*
data,char
*
out){
/
/
长度计算
int
data_len
=
strlen(data);
if
(data_len
=
=
0
){
out[
0
]
=
'\0'
;
return
;
}
int
index
=
0
;
char c
=
'\0'
;
char last_c
=
'\0'
;
for
(
int
i
=
0
;i<data_len;i
+
+
){
c
=
data[i];
switch (i
%
3
) {
case
0
:
out[index
+
+
]
=
base64en[(c>>
2
) &
0x3f
];
break
;
case
1
:
out[index
+
+
]
=
base64en[(last_c &
0x3
) <<
4
| ((c >>
4
) &
0xf
)];
break
;
case
2
:
out[index
+
+
]
=
base64en[((last_c &
0xf
)) <<
2
| ((c >>
6
) &
0x3
)];
out[index
+
+
]
=
base64en[c &
0x3f
];
break
;
}
last_c
=
c;
}
if
(data_len
%
3
=
=
1
){
out[index
+
+
]
=
base64en[(c &
0x3
) <<
4
];
out[index
+
+
]
=
'='
;
out[index
+
+
]
=
'='
;
}
if
(data_len
%
3
=
=
2
){
out[index
+
+
]
=
base64en[(c &
0xf
) <<
2
];
out[index
+
+
]
=
'='
;
}
}
|
笔者给大家写的是简化版本的,不过也能使用。真正要应用于业务代码上的需要做各种容错。
在上述代码中,我们首先做的是待编码字符串的长度计算。使用c记录当前字符,使用last_c记录上一个记录的字符。在计算之前要对3进行取模操作,3个为一组进行编码。
- 对第一个字符进行处理
|
1
|
out[index
+
+
]
=
base64en[(c>>
2
) &
0x3f
];
|
右移两位,并取六位,0x3f表现形式如下:
|
1
2
|
0x3f
0011
1111
|
共有6个1,就是取六位的含义。
- 第二个编码取值
第一个字符还有两位没有处理,所以用last_c表示上一个字符,取出低位2个bit,同时左移四位,为后面拼接的bit腾出来位置。并取第二个字符的前4个bit,代码如下所示:
|
1
|
out[index
+
+
]
=
base64en[(last_c &
0x3
) <<
4
| ((c >>
4
) &
0xf
)];
|
- 第三个编码处理
第二个字符的后4bit还没有使用,我们取出来,并取第三个字符的前2bit
|
1
|
out[index
+
+
]
=
base64en[((last_c &
0xf
)) <<
2
| ((c >>
6
) &
0x3
)];
|
- 第四个编码的处理
直接把剩余字符的低六位取出来即可。
|
1
|
out[index
+
+
]
=
base64en[c &
0x3f
];
|
- 待编码字符的后最后剩一位的情况
根据上述原理的描述,如果只剩下了一位。在这种情况下就要补充两个"="号。
|
1
2
3
4
5
|
if
(data_len
%
3
=
=
1
){
out[index
+
+
]
=
base64en[(c &
0x3
) <<
4
];
out[index
+
+
]
=
'='
;
out[index
+
+
]
=
'='
;
}
|
首先剩下的一位会在for循环中的case 0中,进行编码。但是它还剩下两bit的数据,这时候就需要在函数的最后进行判断,如果只剩下一位,把最后一位的低两位数据取出来并左移4位,在编码表中取索引对应的值。着只是两位base64编码的值,所以,还差两位不能补齐,所以需要补充两个"="号。
- 待编码字符的后最后剩两位的情况
如果剩下两位,那么就需要补充一个"="符号。
|
1
2
3
4
|
if
(data_len
%
3
=
=
2
){
out[index
+
+
]
=
base64en[(c &
0xf
) <<
2
];
out[index
+
+
]
=
'='
;
}
|
取出第二个字符的低4位的bit数据,并左移两位。最后补齐一个"="符号。
6.5.2 Base 64 解码实现
解码的代码如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void base64_decode(char
*
data,char
*
output){
int
data_len
=
strlen(data);
unsigned char c
=
'\0'
;
int
t
=
0
, y
=
0
, i
=
0
;
int
g
=
3
;
for
(
int
x
=
0
;x< data_len;x
+
+
){
c
=
base64_suffix_map[data[x]];
if
(c
=
=
255
) output[
0
]
=
'\0'
;
if
(c
=
=
253
)
continue
;
/
/
对应的值是换行或者回车
if
(c
=
=
254
) { c
=
0
; g
-
-
; }
/
/
对应的值是
'='
t
=
(t<<
6
) | c;
if
(
+
+
y
=
=
4
){
output[i
+
+
]
=
(t >>
16
) &
0xff
;
if
(g >
1
) output[i
+
+
]
=
(unsigned char)((t>>
8
)&
0xff
);
if
(g >
2
) output[i
+
+
]
=
(unsigned char)(t&
0xff
);
y
=
t
=
0
;
}
}
}
|
虽然它的代码结构很简单,但是理解起来还是比较困难的。如果c为255,直接返回数据空值,如果是253则对应的是换行或者是回车。如果是254则对应的是"="符号。
这里分三种情况去解析:
- 没有"="符号
没有等于符号,则t会一直累加,知道y为4才开始处理
|
1
2
3
4
5
6
7
8
9
10
11
|
t
=
0
第一轮
t
=
(t<<
6
) | c
=
> t
=
000000
|
24
(
011000
)
第二轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
54
(
110110
)
第三轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
5
(
000101
)
第四轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
52
(
110100
)
最终的数据:t
=
011000
110110
000101
110100
|
最终y=4的时候进行处理
|
1
2
3
4
5
6
7
|
(t >>
16
) &
0xff
=
>
011000
11
(对应着ascii字符c)
在这个过程中,g一直都是
3
(t>>
8
)&
0xff
=
>
0110
0001
(对应着ascii字符a)
t&
0xff
=
>
01
110100
(对应着ascii字符t)
|
- 有两个"="符号
|
1
2
3
4
5
6
7
8
9
10
11
|
t
=
0
第一轮
t
=
(t<<
6
) | c
=
> t
=
000000
|
24
(
011000
)
第二轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
54
(
110110
)
第三轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
5
(
000101
)
第四轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
52
(
110100
)
最终的数据:t
=
011000
110110
000101
110100
|
最终y=4的时候进行处理
|
1
2
3
|
(t >>
16
) &
0xff
=
>
011000
11
(对应着ascii字符c)
在这个过程中,g一直都是
1
|
- 有一个"="符号
|
1
2
3
4
5
6
7
8
9
10
11
|
t
=
0
第一轮
t
=
(t<<
6
) | c
=
> t
=
000000
|
24
(
011000
)
第二轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
54
(
110110
)
第三轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
5
(
000101
)
第四轮
t
=
(t<<
6
) | c
=
> t
=
011000
|
52
(
110100
)
最终的数据:t
=
011000
110110
000101
110100
|
最终y=4的时候进行处理
|
1
2
3
4
5
|
(t >>
16
) &
0xff
=
>
011000
11
(对应着ascii字符c)
在这个过程中,g一直都是
2
(t>>
8
)&
0xff
=
>
0110
0001
(对应着ascii字符a)
|
这样,Base64的编码和解码的过程就讲解完了。如果大家仔细阅读并认真实操一遍,笔者相信,日后无论Base64码表如何变化,大家都能快速的解决它。
最终的完整代码如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
#include <jni.h>
#include <string>
#include <iostream>
#include <cstring>
#include "android/log.h"
#define TAG "DAT_TAG"
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO,TAG,__VA_ARGS__)
/
/
编码表
static const char base64en[]
=
{
'A'
,
'B'
,
'C'
,
'D'
,
'E'
,
'F'
,
'G'
,
'H'
,
'I'
,
'J'
,
'K'
,
'L'
,
'M'
,
'N'
,
'O'
,
'P'
,
'Q'
,
'R'
,
'S'
,
'T'
,
'U'
,
'V'
,
'W'
,
'X'
,
'Y'
,
'Z'
,
'a'
,
'b'
,
'c'
,
'd'
,
'e'
,
'f'
,
'g'
,
'h'
,
'i'
,
'j'
,
'k'
,
'l'
,
'm'
,
'n'
,
'o'
,
'p'
,
'q'
,
'r'
,
's'
,
't'
,
'u'
,
'v'
,
'w'
,
'x'
,
'y'
,
'z'
,
'0'
,
'1'
,
'2'
,
'3'
,
'4'
,
'5'
,
'6'
,
'7'
,
'8'
,
'9'
,
'+'
,
'/'
};
/
/
解码表
static const unsigned char base64_suffix_map[
256
]
=
{
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
253
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
62
,
255
,
255
,
255
,
63
,
52
,
53
,
54
,
55
,
56
,
57
,
58
,
59
,
60
,
61
,
255
,
255
,
255
,
254
,
255
,
255
,
255
,
0
,
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
,
10
,
11
,
12
,
13
,
14
,
15
,
16
,
17
,
18
,
19
,
20
,
21
,
22
,
23
,
24
,
25
,
255
,
255
,
255
,
255
,
255
,
255
,
26
,
27
,
28
,
29
,
30
,
31
,
32
,
33
,
34
,
35
,
36
,
37
,
38
,
39
,
40
,
41
,
42
,
43
,
44
,
45
,
46
,
47
,
48
,
49
,
50
,
51
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
,
255
};
void base64_encode(const char
*
data,char
*
out){
/
/
长度计算
int
data_len
=
strlen(data);
if
(data_len
=
=
0
){
out[
0
]
=
'\0'
;
return
;
}
int
index
=
0
;
char c
=
'\0'
;
char last_c
=
'\0'
;
for
(
int
i
=
0
;i<data_len;i
+
+
){
c
=
data[i];
switch (i
%
3
) {
case
0
:
out[index
+
+
]
=
base64en[(c>>
2
) &
0x3f
];
break
;
case
1
:
out[index
+
+
]
=
base64en[(last_c &
0x3
) <<
4
| ((c >>
4
) &
0xf
)];
break
;
case
2
:
out[index
+
+
]
=
base64en[((last_c &
0xf
)) <<
2
| ((c >>
6
) &
0x3
)];
out[index
+
+
]
=
base64en[c &
0x3f
];
break
;
}
last_c
=
c;
}
if
(data_len
%
3
=
=
1
){
out[index
+
+
]
=
base64en[(c &
0x3
) <<
4
];
out[index
+
+
]
=
'='
;
out[index
+
+
]
=
'='
;
}
if
(data_len
%
3
=
=
2
){
out[index
+
+
]
=
base64en[(c &
0xf
) <<
2
];
out[index
+
+
]
=
'='
;
}
}
void base64_decode(char
*
data,char
*
output){
int
data_len
=
strlen(data);
unsigned char c
=
'\0'
;
int
t
=
0
, y
=
0
, i
=
0
;
int
g
=
3
;
for
(
int
x
=
0
;x< data_len;x
+
+
){
c
=
base64_suffix_map[data[x]];
if
(c
=
=
255
) output[
0
]
=
'\0'
;
if
(c
=
=
253
)
continue
;
/
/
对应的值是换行或者回车
if
(c
=
=
254
) { c
=
0
; g
-
-
; }
/
/
对应的值是
'='
t
=
(t<<
6
) | c;
if
(
+
+
y
=
=
4
){
output[i
+
+
]
=
(t >>
16
) &
0xff
;
if
(g >
1
) output[i
+
+
]
=
(unsigned char)((t>>
8
)&
0xff
);
if
(g >
2
) output[i
+
+
]
=
(unsigned char)(t&
0xff
);
y
=
t
=
0
;
}
}
}
int
main() {
const char
*
text
=
"kanxue"
;
char out[
100
]
=
{
0
};
base64_encode(text,out);
LOGI(
"encode => %s\n"
,out);
char output[
100
]
=
{
0
};
base64_decode(out,output);
LOGI(
"decode => %s\n"
,output);
return
0
;
}
extern
"C"
JNIEXPORT jstring JNICALL
Java_com_roysue_r0appbase64_MainActivity_stringFromJNI(
JNIEnv
*
env,
jobject
/
*
this
*
/
) {
std::string hello
=
"Hello from C++"
;
main();
return
env
-
>NewStringUTF(hello.c_str());
}
|
6.6 本章小结
在本章中,笔者从Base64的来源以及使用场景入手,带领大家一步一步的了解Base64编码,并了解了Base64编码在算法中的使用。目前对Base64的商用就是魔改Base64编码表,无论Base64编码表如何变化,我们只要熟知其计算原理,不管它怎么变,我们都能准确的识别和复原。所以,笔者从原理出发,带领大家一步一步把具体的实现方法给大家讲述了出来。
更多【Base64 编码原理 && 实现】相关视频教程:www.yxfzedu.com
相关文章推荐
- 加壳脱壳- UPX源码学习和简单修改 - Android安全CTF对抗IOS安全
- 二进制漏洞-win越界写漏洞分析 CVE-2020-1054 - Android安全CTF对抗IOS安全
- Pwn-2022长城杯决赛pwn - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter服务端 - Android安全CTF对抗IOS安全
- Pwn-沙箱逃逸之google ctf 2019 Monochromatic writeup - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com