加壳脱壳- UPX源码学习和简单修改
推荐 原创UPX源码学习和简单修改
之前一直学习如何脱壳,接触到的第一种壳就是UPX。经过一段脱壳训练后,逐渐对UPX的压缩流程有了兴趣。本文是笔者对UPX源码的学习记录,包括代码学习过程和源码简单修改,希望对大家有所帮助。
分析环境:
UPX版本: 3.96 (https://github.com/upx/upx/releases/download/v3.96/upx-3.96-src.tar.xz)
linux系统: centOS 7 - Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
kali: Linux kali 5.9.0-kali1-amd64 #1 SMP Debian 5.9.1-1kali2 (2020-10-29) x86_64 GNU/Linux
010 Editor版本: v10.0 (64 bit)
源码分析
为了方便调试,笔者只分析了x86-64位ELF文件的加壳流程代码,本文所用程序见结尾文件 demo。代码跟踪过程主要参考文章,大家有兴趣可详细阅读。这里只介绍大体流程。
加壳流程
UPX的核心加壳代码是 upx-3.96/src/p_unix.cpp 文件的 pack 函数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
void PackUnix::pack(OutputFile
*
fo)
{
Filter
ft(ph.level);
ft.addvalue
=
0
;
b_len
=
0
;
progid
=
0
;
/
/
set
options
blocksize
=
opt
-
>o_unix.blocksize;
if
(blocksize <
=
0
)
blocksize
=
BLOCKSIZE;
if
((off_t)blocksize > file_size)
blocksize
=
file_size;
/
/
init compression buffers
ibuf.alloc(blocksize);
obuf.allocForCompression(blocksize);
fi
-
>seek(
0
, SEEK_SET);
pack1(fo, ft);
/
/
generate Elf header, etc.
p_info hbuf;
set_te32(&hbuf.p_progid, progid);
set_te32(&hbuf.p_filesize, file_size);
set_te32(&hbuf.p_blocksize, blocksize);
fo
-
>write(&hbuf, sizeof(hbuf));
/
/
append the compressed body
if
(pack2(fo, ft)) {
/
/
write block end marker (uncompressed size
0
)
b_info hdr; memset(&hdr,
0
, sizeof(hdr));
set_le32(&hdr.sz_cpr, UPX_MAGIC_LE32);
fo
-
>write(&hdr, sizeof(hdr));
}
pack3(fo, ft);
/
/
append loader
pack4(fo, ft);
/
/
append PackHeader
and
overlay_offset; update Elf header
/
/
finally
check the compression ratio
if
(!checkFinalCompressionRatio(fo))
throwNotCompressible();
}
|
该函数调用了4个关键函数,分别为pack1、pack2、pack3和pack4,代表了加壳的四个步骤。
pack1 函数功能是,写入新文件的elf头,写入程序头表,写入1个初始化的l_info结构。
pack2 函数功能是,对所有类型为PT_LOAD的段进行压缩存储。
其中,在对第一个类型为PT_LOAD的段(该块一般包含原文件的文件头和程序头表)进行压缩时,会将该段分为两个部分分别压缩写入。这两部分为:一、原文件的elf头和程序头表;二、该段数据的其他部分。
例如,demo文件中第一个PT_LOAD段如下
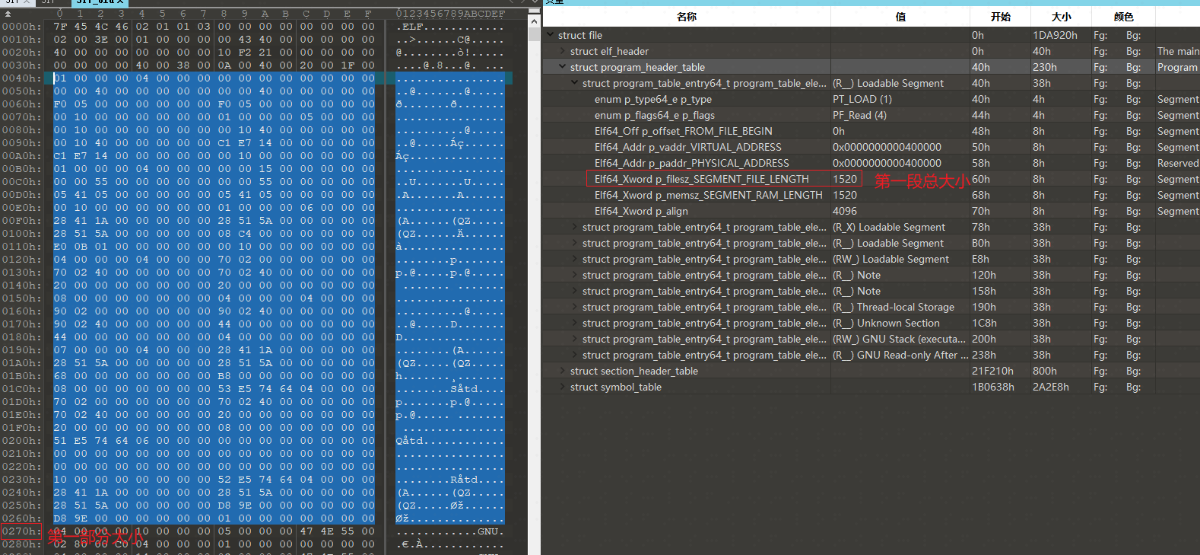
第一段文件偏移为0,大小为0x5F0。从图中可以看到文件头+程序头表的大小为0x270,这就是需要压缩的第一块数据。第二块数据就是文件偏移为0x270,大小为0x380。
pack3 函数的功能是,写入loader,压缩原文件中除PT_LOAD段之外的其余数据并写入,修正程序头表内容
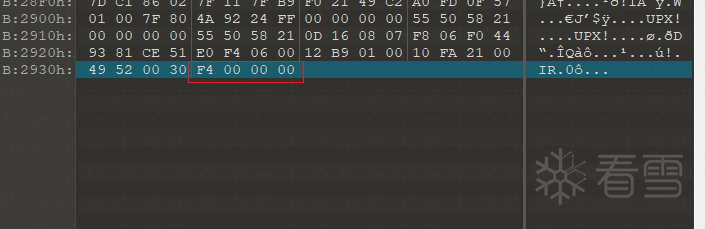
pack4 函数的功能是,写入PackHeader和overlay_offset。这里overlay_offset值为p_info字段的文件偏移。本demo中为0xf4。
文件格式
经过UPX处理后,压缩后的文件格式如下。
new eheader(64 bytes) (文件头)
+ new pheader(56 bytes) * 3 (程序头表)
+ l_info(12 bytes)
+ p_info(12 bytes)
+ b_info(12 bytes) + compressed block (原程序文件头和程序头表)
+ b_info(12 bytes) + compressed block (第一个类型为PT_LOAD的段中除原程序文件头和程序头表的部分)
+ b_info(12 bytes) + compressed block (第二个类型为PT_LOAD的段)
+ ......
+ fpad8 (8字节对齐)
+ int(4 bytes) (第一个b_info的文件偏移)
+ int(4 bytes) (当前位置的文件偏移,也就是之前所有数据总长度)
+ loader (加载器,也就是脱壳代码)
+ b_info(12 bytes) + compressed block (第一个PT_LOAD和第二个PT_LOAD中间的数据)
+ b_info(12 bytes) + compressed block (第二个PT_LOAD和第三个PT_LOAD中间的数据)
+ ......
+ b_info(12 bytes) + compressed block (最后一个PT_LOAD到文件末尾之间的数据)
+ 00 00 00 00 55 50 58 21 00 00 00 00 (b_info)
+ fpad4 (4字节对齐)
+ PackHeader(32 bytes)
+ int(4 bytes) (p_info的文件偏移)
其中,b_info、l_info和p_info是三个结构体。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
/
/
在每个压缩块之前,存放压缩前和压缩后的数据大小
struct b_info {
/
/
12
-
byte header before each compressed block
uint32_t sz_unc;
/
/
uncompressed_size
uint32_t sz_cpr;
/
/
compressed_size
unsigned char b_method;
/
/
compression algorithm
unsigned char b_ftid;
/
/
filter
id
unsigned char b_cto8;
/
/
filter
parameter
unsigned char b_unused;
};
/
/
存放校验数据和
"UPX!"
魔数
struct l_info
/
/
12
-
byte trailer
in
header
for
loader (offset
116
)
{
uint32_t l_checksum;
uint32_t l_magic;
uint16_t l_lsize;
uint8_t l_version;
uint8_t l_format;
};
/
/
全文只有一个该结构体,存储的是原文件的大小
struct p_info
/
/
12
-
byte packed program header follows stub loader
{
uint32_t p_progid;
uint32_t p_filesize;
uint32_t p_blocksize;
};
|
loader
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
void
PackLinuxElf::addStubEntrySections(
Filter
const
*
)
{
addLoader(
"ELFMAINX"
, NULL);
if
(hasLoaderSection(
"ELFMAINXu"
)) {
/
/
brk() trouble
if
static
addLoader(
"ELFMAINXu"
, NULL);
}
/
/
addLoader(getDecompressorSections(), NULL);
addLoader(
( M_IS_NRV2E(ph.method) ?
"NRV_HEAD,NRV2E,NRV_TAIL"
: M_IS_NRV2D(ph.method) ?
"NRV_HEAD,NRV2D,NRV_TAIL"
: M_IS_NRV2B(ph.method) ?
"NRV_HEAD,NRV2B,NRV_TAIL"
: M_IS_LZMA(ph.method) ?
"LZMA_ELF00,LZMA_DEC20,LZMA_DEC30"
: NULL), NULL);
if
(hasLoaderSection(
"CFLUSH"
))
addLoader(
"CFLUSH"
);
addLoader(
"ELFMAINY,IDENTSTR"
, NULL);
if
(hasLoaderSection(
"ELFMAINZe"
)) {
/
/
ppc64 big
-
endian only
addLoader(
"ELFMAINZe"
, NULL);
}
addLoader(
"+40,ELFMAINZ"
, NULL);
if
(hasLoaderSection(
"ANDMAJNZ"
)) {
/
/
Android trouble with args to DT_INIT
if
(opt
-
>o_unix.android_shlib) {
addLoader(
"ANDMAJNZ"
, NULL);
/
/
constant PAGE_SIZE
}
else
{
addLoader(
"ELFMAJNZ"
, NULL);
/
/
PAGE_SIZE
from
AT_PAGESZ
}
addLoader(
"ELFMAKNZ"
, NULL);
}
if
(hasLoaderSection(
"ELFMAINZu"
)) {
addLoader(
"ELFMAINZu"
, NULL);
}
addLoader(
"FOLDEXEC"
, NULL);
}
|
除了"FOLDEXEC",其余section的汇编代码在upx-3.96/src/stub/src/amd64-linux.elf-entry.S文件中,编译后的二进制数据在文件upx-3.96/src/stub/amd64-linux.elf-entry.h中。loader直接使用*.h文件中的二进制数据。
最终,demo文件压缩后loader的结构如下
|
1
2
3
4
5
6
7
8
9
|
ELFMAINX
NRV_HEAD
NRV2E
NRV_TAIL
ELFMAINY
IDENTSTR
+
40
(
4
字节对齐)
ELFMAINZ
FOLDEXEC
|
FOLDEXEC
FOLDEXEC节存放的是压缩后的数据,源数据是编译后的二进制数据,存放在upx-3.96/src/stub/amd64-linux.elf-fold.h文件中。
编译前的代码分为两部分,一部分是upx-3.96/src/stub/src/amd64-linux.elf-fold.S文件中的汇编代码,一部分是upx-3.96/src/stub/src/amd64-linux.elf-main.c文件中的C代码。该文件核心是upx_main()函数,此函数返回值为解压后程序(原程序)的入口点.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
/
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
/
/
upx_main
-
called by our entry code
/
/
/
/
This function
is
optimized
for
size.
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
/
void
*
upx_main(
/
/
returns entry address
struct b_info const
*
const bi,
/
/
1st
block header
size_t const sz_compressed,
/
/
total length
Elf64_Ehdr
*
const ehdr,
/
/
temp char[sz_ehdr]
for
decompressing
Elf64_auxv_t
*
const av,
f_expand
*
const f_exp,
f_unfilter
*
const f_unf
#if defined(__x86_64) //{
, Elf64_Addr elfaddr
/
/
In: &Elf64_Ehdr
for
stub
#elif defined(__powerpc64__) //}{
, Elf64_Addr
*
p_reloc
/
/
In: &Elf64_Ehdr
for
stub; Out:
'slide'
for
PT_INTERP
, size_t const PAGE_MASK
#elif defined(__aarch64__) //}{
, Elf64_Addr elfaddr
, size_t const PAGE_MASK
#endif //}
)
{
......
}
|
010模板
在阅读UPX源码过程中,经常需要对压缩后的文件格式进行分析,以验证自己的猜想。因为笔者经常使用010作为二进制分析工具,遂决定自己写一个010模板。这里是对标准的 ELF.bt(V2.5.5)进行了修改。
首先,将上节所述的三个关键结构体加入到模板中,为了增加可读性,在个别字段添加属性值。添加的结构体代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
typedef uint uint32_t;
typedef ushort uint16_t;
typedef uchar uint8_t;
struct b_info
/
/
12
-
byte header before each compressed block
{
uint32_t sz_unc<
format
=
hex
, comment
=
"Uncompressed size"
>;
/
/
uncompressed_size
uint32_t sz_cpr<
format
=
hex
, comment
=
"Compressed size"
>;
/
/
compressed_size
unsigned char b_method<comment
=
"Compression algorithm"
>;
/
/
compression algorithm
unsigned char b_ftid;
/
/
filter
id
unsigned char b_cto8;
/
/
filter
parameter
unsigned char b_unused;
};
struct l_info
/
/
12
-
byte trailer
in
header
for
loader (offset
116
)
{
uint32_t l_checksum;
uint32_t l_magic<
format
=
hex
, comment
=
"UPX!"
>;
uint16_t l_lsize;
uint8_t l_version;
uint8_t l_format;
};
struct p_info
/
/
12
-
byte packed program header follows stub loader
{
uint32_t p_progid;
uint32_t p_filesize;
uint32_t p_blocksize;
};
typedef struct
{
b_info bheader;
char data[bheader.sz_cpr];
}cblock;
typedef struct
{
uint32 offset_b_info;
uint32 data_size;
}endheader;
|
然后,将原来模板中file结构体中对section的解析代码去掉,因为UPX压缩后的文件没有相关字段。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
/
/
需要删除的代码
/
/
Find the header name location
869
行
local quad section_name_off
=
file
.elf_header.e_shoff_SECTION_HEADER_OFFSET_IN_FILE
+
(
file
.elf_header.e_shentsize_SECTION_HEADER_ENTRY_SIZE
*
file
.elf_header.e_shtrndx_STRING_TABLE_INDEX);
/
/
Find the header name block
if
(
file
.elf_header.e_ident.ei_class_2
=
=
ELFCLASS32) {
......
}
else
{
......
}
local
int
sec_tbl_cur_elem;
/
/
Find the section headers
if
(
file
.elf_header.e_shnum_NUMBER_OF_SECTION_HEADER_ENTRIES >
0
) {
......
}
local
int
sym_sect;
local
int
sym_name_sect;
/
/
Find the symbol section
sym_sect
=
FindNamedSection(
".symtab"
);
if
(sym_sect >
=
0
) {
......
}
/
/
Find the dynamic symbol section
sym_sect
=
FindNamedSection(
".dynsym"
);
if
(sym_sect >
=
0
) {
......
}
|
最后,在file结构体中program_header_table结构体生成之后,添加l_info结构之后的数据解析代码。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
/
/
需要添加的代码
869
行
FSeek(
file
.elf_header.e_phoff_PROGRAM_HEADER_OFFSET_IN_FILE
+
file
.elf_header.e_phentsize_PROGRAM_HEADER_ENTRY_SIZE_IN_FILE
*
file
.elf_header.e_phnum_NUMBER_OF_PROGRAM_HEADER_ENTRIES);
l_info linfone;
p_info pinfone<comment
=
"Original file size"
>;
/
/
Compressed block of PT_LOAD
local uint64 now_offsize;
now_offsize
=
file
.elf_header.e_phoff_PROGRAM_HEADER_OFFSET_IN_FILE
+
file
.elf_header.e_phentsize_PROGRAM_HEADER_ENTRY_SIZE_IN_FILE
*
file
.elf_header.e_phnum_NUMBER_OF_PROGRAM_HEADER_ENTRIES
+
24
;
local uint64 tmp_offsize
=
0
;
local uint64 tmp
=
0
;
struct
{
while
(true)
{
tmp_offsize
=
now_offsize
+
(
7u
& (
0
-
now_offsize));
tmp
=
ReadInt64(tmp_offsize);
if
(((tmp&
0xffffffff
)
=
=
0x100
) && (((tmp>>
32
)&
0xffffffff
)
=
=
(tmp_offsize
+
4
)))
{
break
;
}
else
{
FSeek(now_offsize);
cblock a;
now_offsize
=
now_offsize
+
a.bheader.sz_cpr
+
12
;
}
}
} cpr_load<comment
=
"Compressed block of PT_LOAD"
>;
FSeek(tmp_offsize);
endheader headerEND;
local uint64 sizeloader
=
program_header_table.program_table_element[
0
].p_filesz_SEGMENT_FILE_LENGTH
-
tmp_offsize
-
8
;
uchar loader[sizeloader];
/
/
Compressed block of GAPS
FSeek(program_header_table.program_table_element[
0
].p_filesz_SEGMENT_FILE_LENGTH);
now_offsize
=
program_header_table.program_table_element[
0
].p_filesz_SEGMENT_FILE_LENGTH;
tmp_offsize
=
0
;
tmp
=
0
;
struct
{
while
(true)
{
tmp_offsize
=
now_offsize;
tmp
=
ReadInt64(tmp_offsize);
if
(((tmp &
0xffffffff
)
=
=
0
) && (((tmp >>
32
) &
0xffffffff
)
=
=
(
0x21585055
)))
{
break
;
}
else
{
FSeek(now_offsize);
cblock b;
now_offsize
=
now_offsize
+
b.bheader.sz_cpr
+
12
;
}
}
} cpr_gaps<comment
=
"Compressed block of GAPS"
>;
b_info check_upx<comment
=
"Block end marker (uncompressed size 0, compressed size 559435861)"
>;
tmp_offsize
=
tmp_offsize
+
12
;
tmp_offsize
=
tmp_offsize
+
(
3u
& (
0
-
tmp_offsize));
FSeek(tmp_offsize);
uchar PackHeader[
32
]<comment
=
"PackHeader"
>;
uint32 size_p_info<
format
=
hex
, comment
=
"Offset of p_info"
>;
|
最终效果如下,红框中是我们添加的新结构。
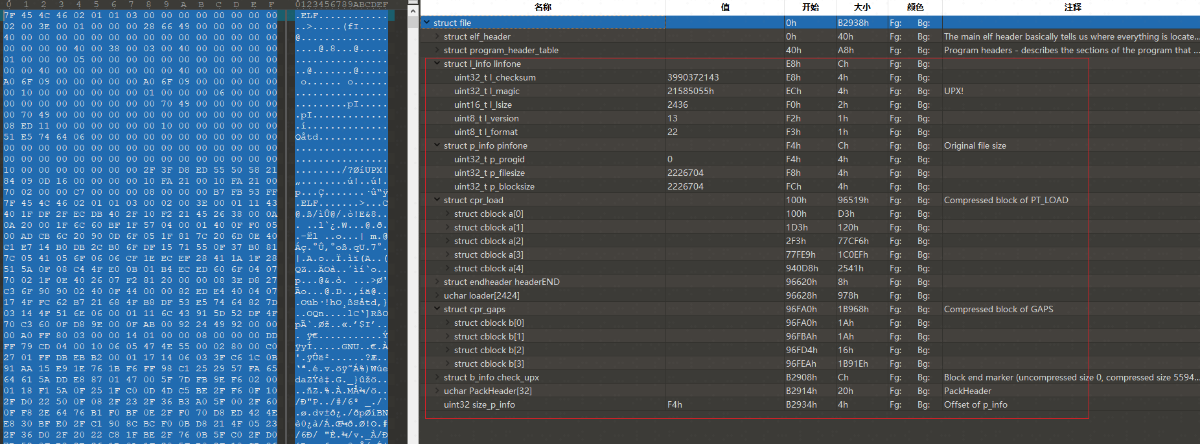
修改完成的模板见结尾文件 upx.bt。因为文件格式问题,该模板只适用于 demo 文件压缩后的文件。大家有其他需求可以在此基础上自己修改。
源码修改
之前做病毒分析时,碰到了一个无法使用标准UPX程序解压的程序。后来通过搜寻资料和学习,了解到有多种方式可实现该效果。基本思路是修改替换程序中的特征字符,常见的修改方法如下:
- UPX两个区段名称修改
- PE中DOS头修改
- 三个UPX特征码修改(参考EXEINFO等壳识别工具中的特征匹配规则)
- UPX相关字符串去除或修改
据此,笔者萌生直接对源码进行修改的想法,所以有以下两个简单尝试。
- 入口点字段修改
- 压缩数据修改
入口点字段修改
本次尝试主要是修改源程序的入口点位置,使常规的UPX解压程序后无法快速找到正确的入口点位置。
代码修改
存储入口点之前,处理该值,这里异或一个常量0xdeafdeaf。文件upx-3.96/src/p_unix.cpp添加如下代码
12345678334intl=fi->readx(hdr_ibuf, hdr_u_len);335/*****************************************/336//add2022-11-2920:02337//edit2022-12-1210:19338unsigned char*ttt=(unsigned char*)hdr_ibuf;339Elf64_Ehdr*tmp=(Elf64_Ehdr*)ttt;340tmp->e_entry=(tmp->e_entry ^0xdeafdeaf);341/*****************************************/解压得到入口点之后,处理该值,也是异或常量0xdeafdeaf。这里有两种方式,实现的功能一样。
- 文件upx-3.96/src/stub/src/amd64-linux.elf-fold.S添加汇编代码
xor $3736067759,%eax123456789movq%rbp,%arg5# &decompress: f_expandcall upx_main# Out: %rax= entry/*entry=upx_main(b_info*arg1, total_size arg2, Elf64_Ehdr*arg3,Elf32_Auxv_t*arg4, f_decompr arg5, f_unf arg6,Elf64_Addr elfaddr )*/xor $3736067759,%eax//add2022-12-12addq $1*NBPW+OVERHEAD,%rsp# toss elfaddr, toomovq%rax,4*NBPW(%rsp)# entrypop%rbx# fd - 文件upx-3.96/src/stub/amd64-linux.elf-fold.h修改二进制数据,修改三处代码
123
#define STUB_AMD64_LINUX_ELF_FOLD_SIZE 2251->#define STUB_AMD64_LINUX_ELF_FOLD_SIZE 2256123unsigned char stub_amd64_linux_elf_fold[2251]={->unsigned char stub_amd64_linux_elf_fold[2256]={123/*0x01d0*/137,232,232,172,5,0,0,72,129,196,8,8,0,0,72,137,->/*0x01d0*/137,232,232,177,5,0,0,53,175,222,175,222,72,129,196,8,8,0,0,72,137,xor eax, 3736067759 -> 35 AF DE AF DE -> 53,175,222,175,222
验证
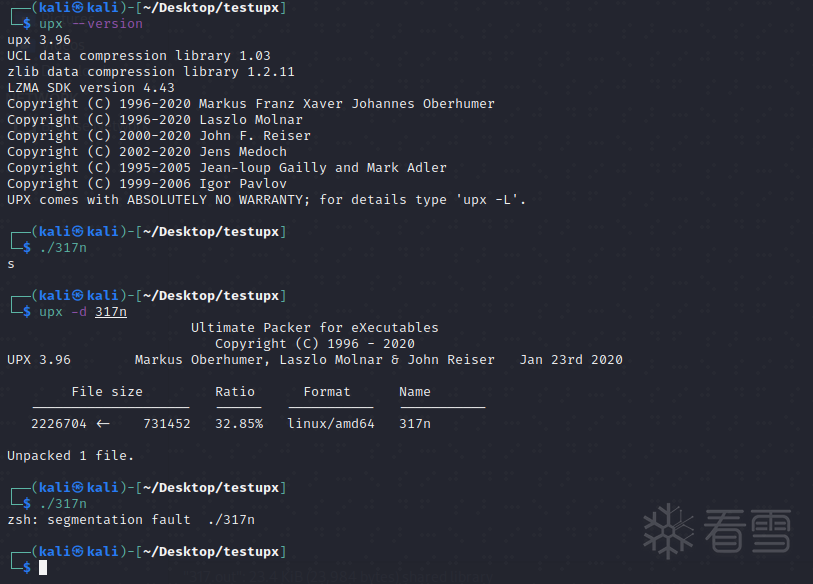
- 使用修改源码后的程序加壳,程序可正常执行。这里的UPX版本是3.96

- 在kali上执行加壳后的程序,可正常执行

- 使用kali上的UPX程序解压缩该程序(UPX版本为3.96),执行程序提示段错误
压缩数据修改
上面对于入口点的修改虽然成功了,但是压缩后的程序仍然可被解压。而且从原理来看,解压后是可以看到原程序代码执行逻辑的。所以笔者有了第二次代码修改。主要修改思路是,对压缩之前的数据进行处理,然后再进行压缩。这样标准UPX就无法解压我们自己压缩的程序,比只对入口点的修改效果更好。
代码修改
压缩前修改数据,我们做一个简单的异或处理,这里对所有的数据异或0xe9(十进制为233)
文件:upx-3.96/src/compress.cpp
upx_compress函数修改,核心部分123456789101112131415161718192096#if 197//debug98cresult->method=method;99cresult->level=level;100cresult->u_len=src_len;101cresult->c_len=0;102#endif103////////////////////////////////////////////////////////104const unsigned char*tmp=(const unsigned char*)src;105unsigned char*tmp0=(unsigned char*)malloc(src_len*sizeof(char));106unsigned char*tmp1=tmp0;107memcpy(tmp0, tmp, src_len);108size_t i=0;109for(i=0;i<src_len;i++)110{111(*tmp0)=(*tmp0)^0xe9;112tmp0=tmp0+1;113}114src=tmp1;115////////////////////////////////////////////////////////upx_decompress函数修改,此处修改主要是因为在文件upx-3.96/src/packer.cpp的Packer::compress函数中,会对压缩后的数据进行解压验证,需要保持压缩和解压函数逻辑对称。
12345678910111213190else{191throwInternalError("unknown decompression method");192}193////////////////////////////////////////////////////////194unsigned char*dst_tmp=dst;195size_t i=0;196for(i=0;i<(*dst_len);i++)197{198(*dst)=(*dst)^0xe9;199dst=dst+1;200}201dst=dst_tmp;202////////////////////////////////////////////////////////upx在加载loader是会对其进行压缩处理,而解压算法已写成汇编代码,修改起来比较麻烦。这里我就对loader数据多进行一次处理,以抵消upx-3.96/src/compress.cpp文件upx_compress函数中添加的异或处理。
文件:upx-3.96/src/p_lx_elf.cpp1234567891011121314151222unsigned h_sz_cpr=h.sz_cpr;1223///////////////////////////////////////////////////////////////////////////1224//add2022-12-2913:581225unsigned char*tmp=(unsigned char*)malloc(h.sz_unc*sizeof(char));1226memcpy(tmp,uncLoader,h.sz_unc);1227unsigned char*tmp0=tmp;1228size_t i=0;1229for(i=0;i<h.sz_unc;i++)1230{1231(*tmp)=(*tmp)^0xe9;1232tmp=tmp+1;1233}1234////////////////////////////////////////////////////////////////////////////1235intr=upx_compress(tmp0, h.sz_unc, sizeof(h)+cprLoader, &h_sz_cpr,1236NULL, ph.method,10, NULL, NULL);//edit uncLoader-> tmp0因为原数据压缩前进行了处理,为保证执行时程序逻辑不变,需要对解压后的数据进行逆处理。下面就是对loader的源码进行修改。
文件:upx-3.96/src/stub/src/amd64-linux.elf-main.c1234567891011121314151617194intconst j=(*f_exp)((unsigned char*)xi->buf, h.sz_cpr,195(unsigned char*)xo->buf, &out_len,196#if defined(__x86_64) //{197*(int*)(void*)&h.b_method198#elif defined(__powerpc64__) || defined(__aarch64__) //}{199h.b_method200#endif //}201);202////////////////////////////////////////////////////////203unsigned char*tmp=(unsigned char*)xo->buf;204size_t i=0;205for(i=0; i < h.sz_unc; i++)206{207*tmp=(*tmp)^0xe9;208tmp=tmp+1;209}210////////////////////////////////////////////////////////
验证
- 编译后的程序版本为3.96
对demo文件进行压缩处理,可以看到处理后的文件大小,文件也可以正常执行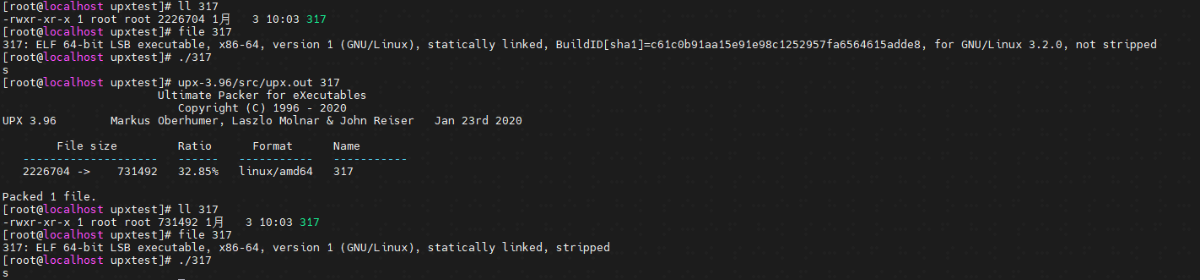
- 将该文件拷贝到kali中,也可以正常执行

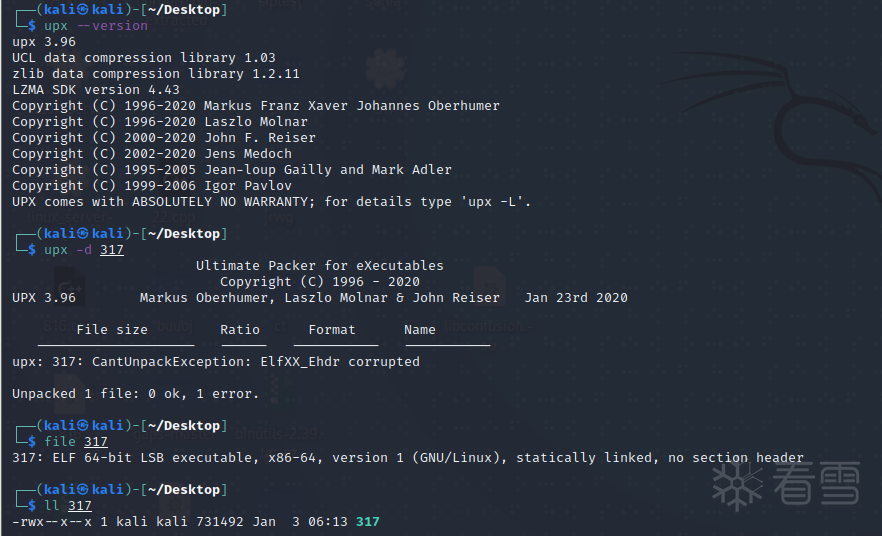
- 使用kali自带的UPX,版本3.96对压缩后的文件进行解压,提示解压失败。
总结
本文主要介绍了三个部分的内容:
- UPX源码简单介绍,包括加壳的流程和加壳后的文件格式。
- 根据第一部分介绍的文件格式,对标准ELF.bt文件进行修改,使其可以解析加壳后的文件。
- 介绍两种UPX源码简单修改方式:一是修改文件入口点,二是修改加壳的数据。
文章较短,如有不足,恳请指正,不胜感激。
https://www.cnblogs.com/ichunqiu/p/7245329.html
https://bbs.kanxue.com/thread-257797.htmtmnxue.com/thread-257797.htm
更多【 UPX源码学习和简单修改】相关视频教程:www.yxfzedu.com
相关文章推荐
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全CTF对抗IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全CTF对抗IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全CTF对抗IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全CTF对抗IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com