kafka-Kafka(消息队列)--简介
推荐 原创1、kafka:
是一个高吞吐的分布式消息系统,与Hdfs比较相似,但是与hdfs的区别是在于hdfs是存储的是历史的、海量的数据,然而kafka存储的是实时的、最新的数据。
2、消息队列:
指的是在Kafka中的数据队列。可以存放数据在峰值的时候的数据,因为在数据峰值的时候,此时的数据量比较大,对于消费者没有办法及时的消费,为了防止反压的现象,此时的数据就可以在消息队列中等待。
生产者:生产者负责产生数据
消费者:消费者负责消费数据
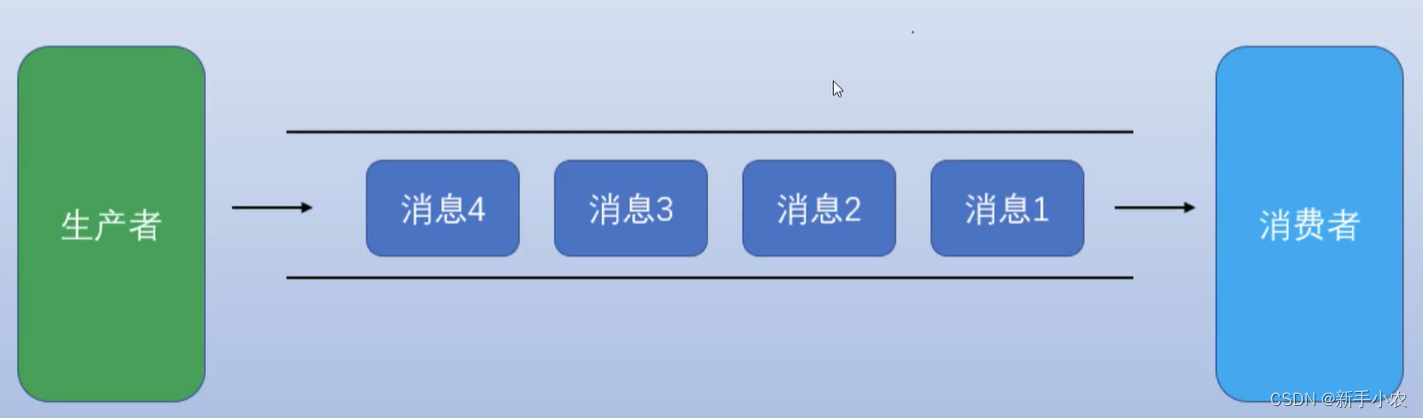
3、消息队列的一般的应用场景:系统之间的解耦合、峰值压力缓冲、异步通信
峰值压力缓冲的应用在Flink中:
当数据某一时刻的产生的速度要是大于Flink的处理的速度,可以通过提高并行度来增加数据处理的速度,但是Flink是7*24小时的工作机制,就会导致资源的浪费,此时可以通过kafka来做峰值压力缓冲,就是在Flink高峰期的时候,将没办法及时处理的数据缓存在队列中,减轻Flink的压力。
4、Kafka的特点:
1、消息系统的模型:生存者消费者模型,FIFO模型
2、高性能:单节点支持上千个客户端
3、持久性:消息直接持久化在磁盘上且性能比较好
4、分布式:数据副本冗余,流量负载均衡,可扩展
5、很灵活:消息长时间持久化+client维护消费状态
5、kafka性能比较好的原因:
1、kafka写磁盘是顺序写的
2、采用了sendFile的0拷贝的技术,提高速度
3、还采用了批量写入,一批一批的写入数据,64k为一个单位。
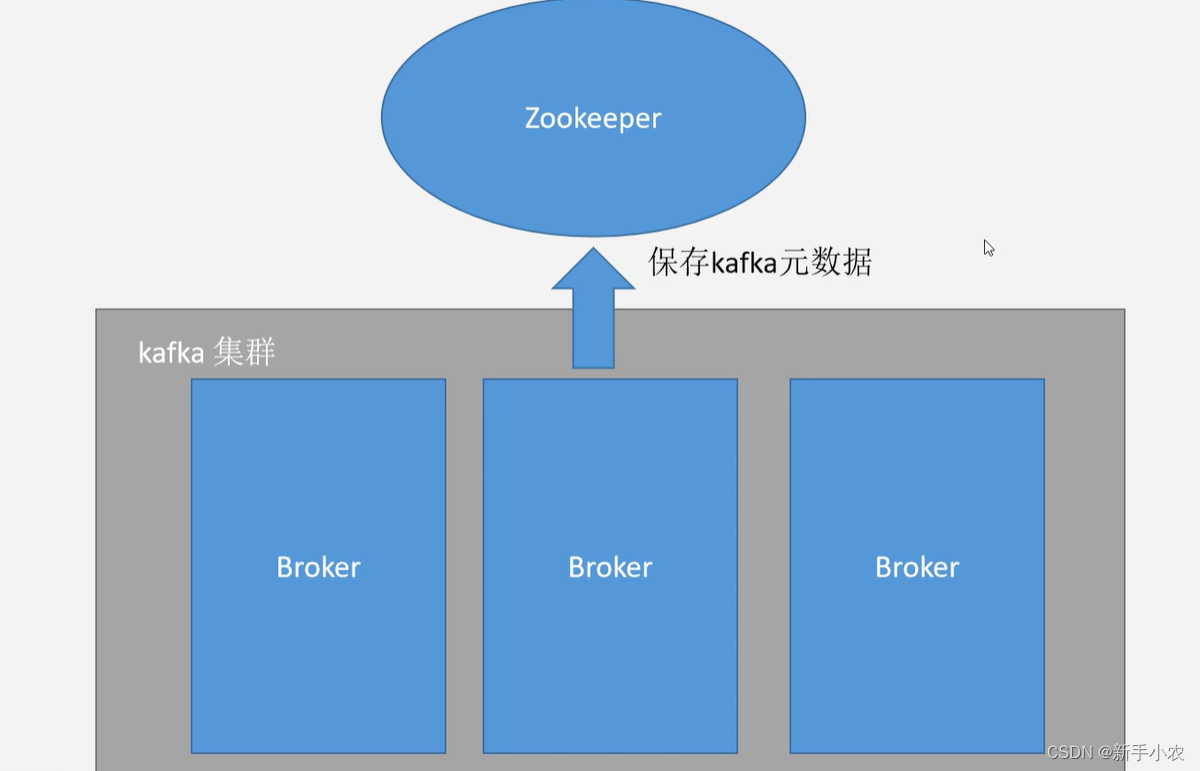
6、kafka集群:
1、组件:
1、broker:使用存放数据的,也是多节点的
2、Zookeeper:负责存储kafka的元数据
更多【kafka-Kafka(消息队列)--简介】相关视频教程:www.yxfzedu.com
相关文章推荐
- metersphere-社区分享|杭银消费金融基于MeterSphere开展接口自动化测试 - 其他
- uni-app-【uniapp】签名组件,兼容vue2vue3 - 其他
- 编程技术-【自然语言处理】基于python的问答系统实现 - 其他
- 编程技术-Bean作用域 - 其他
- lua-Unreal UnLua + Lua Protobuf - 其他
- python-【Python自学笔记】Flask调教方法Internel Server Error - 其他
- oracle-node插件MongoDB(二)——MongoDB的基本命令 - 其他
- 智能手机-手机怎么打包?三个方法随心选! - 其他
- 智能手机-香港金融科技周VERTU CSO Sophie谈Web3.0的下一个风口 手机虚拟货币移动支付 - 其他
- 搜索引擎-外贸网站优化常用流程和一些常识 - 其他
- 电脑-PHP分类信息网站源码系统 电脑+手机+微信端三合一 带完整前后端部署教程 - 其他
- 智能手机-手机是否能登陆国际腾讯云服务器? - 其他
- 智能手机-GD32单片机远程升级下载,手机在线升级下载程序,GD32在线固件下载升级,手机下载程序固件方法 - 其他
- 华为-漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案 - 其他
- 架构-LoRaWAN物联网架构 - 其他
- clickhouse-【总结卡】clickhouse数据库常用高级函数 - 其他
- java-深入理解ClickHouse跳数索引 - 其他
- 小程序-小程序发成绩 - 其他
- 运维-墨者学院 Ruby On Rails漏洞复现第一题(CVE-2018-3760) - 其他
- fpga开发-「Verilog学习笔记」多功能数据处理器 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com