Android安全-大众DP BR X8跳转清理 && a5分析
推荐 原创【Android安全-大众DP BR X8跳转清理 && a5分析】此文章归类为:Android安全。
大众DP BR跳转清理 && a5分析
之前的帖子清理了jumpout,本文尝试静态分析和利用frida来分析mtgsig参数。
分析过程
定位算法的步骤这里就省略了,直接从一个hook结果开始分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | mtgsig = { "a0": "3.0", "a1": "4069cb78-e02b-45f6-9f0a-b34ddccf389c", "a3": 24, "a4": 1736155982, "a5": "AHepznjTBvV7rHiYm8hD1+169lwTCD+PNAA6LuQx6hGIgKX2FHR3ADYlwF38q/j8dk6sKm+PO57A3AKiYH4RX1FE7Cyy8UkEwWceQURrxfHX2O7LqWtfwYCsTtE0kUoXW4aGxaAiAagM2KtS81ff/NZUgIYvdaLeiljIXbHGV+6QtbotS6/ClGky4cd1RHy7GZsJ8ubecJjv4QKLxAq4cHgsro4z9Iboi4gYCi+dTStYrEWEPRAhk9VPX3oQHeqlpRrqxGQxCbGUWjjEi/CNjuuF7W8xEnTNq0zOY/YO", "a6": 0, "a7": "jSAxPWen3i2zs6omj1rD+uRsiQhiPxEE1CA+76YkCHDQqmp25ELpd3PUR0uWoNZ0eAc0RLxbkZrYsmQwKjqe27lZZ8o95TEOOSQLRo8bHYA=", "a8": "742b25deffb779f5ed08910789926e676ca5f078d42b28d5c7dd370c", "a9": "dd051dd5C+3hWx/JTxImXsb+pQWQL/bklyGy4z5sN8nq7p/2yW7SAN9GsygMJe3E3IzoY912YiZ0iCnsGiPPRB6lrUP2uehxqbJlpkuyNQwe7Eh5WcvUlzYW39m7Rh5PNTZhoAUnM7NBMbYqz+WK2hslAUX8mSaQJyebUz8jOxMc7RAdK7SOXFxNX+Mcs/RN2nED0lzB4ZF/I8CFMZHjE5cBAKpeXsQaYalSlK9D50zxK/0sjdlc/knfNcMFq5hFfYz8UDPP4OCeHI/U5YcgrsbgxDH41Qs6bmBF+5YoHT+pKsxc3uc=", "a10": "5,155,1.1.1", "x0": 1, "a2": "673fb25da2fb9e3cb2eff5b39b152559"} |
从上面结果可以看出一些很长的猜测很关键的字段base64字符串,所以直接利用ida的插件搜索算法特征。
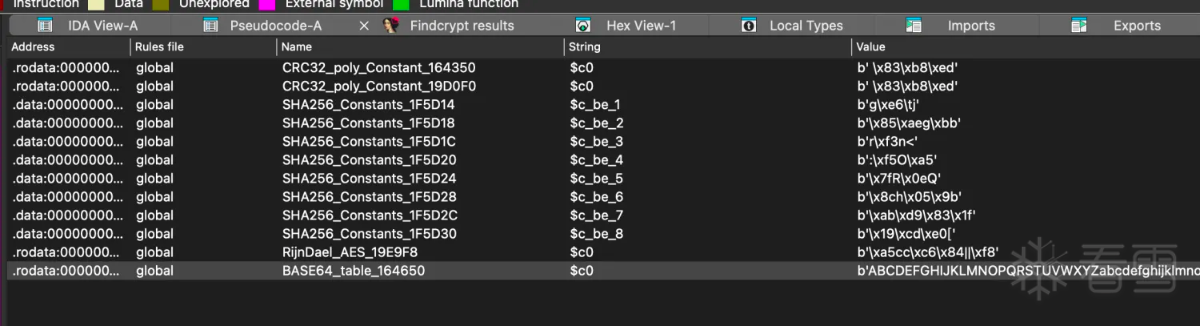
利用上面特征可以定位到函数sub_4cf88, 利用frida hook验证参数中的字段是否出现在此函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | // hook java 入口函数function hook_main3() { var Arrays = Java.use("java.util.Arrays"); var ShellBridge = Java.use("com.meituan.android.common.mtguard.ShellBridge"); ShellBridge.main3.implementation = function (i, objArr) { console.log("hook ShellBridge.main3"); var ret = this.main3(i, objArr); console.log(objArr.length); console.log(objArr[0]); // var arr = Arrays.asList(objArr); // for (var i; i < arr.size(); i++) { // var item = arr.get(i); // console.log(item); // } console.log(`ShellBridge.main3args: ${i}\n${objArr}\nret: ${ret}\n`); return ret; }}function hook_dlopen() { Interceptor.attach(Module.findExportByName(null, "android_dlopen_ext"), { onEnter: function (args) { var path_ptr = args[0]; if (path_ptr != undefined && path_ptr != null) { var path = ptr(path_ptr).readCString(); console.log("[LOAD] " + path); if (path.indexOf("libmtguard.so") != -1) { this.canHook = true; } } }, onLeave: function (retval) { if (this.canHook) { // 这里添加hook native的函数 hook_4cf88(); // base64 1 hook_68958(); // rc4 init hook_68968(); // rc4 enc hook_683ec(); // rc4 key related hook_34844(); // rc4 input } } })}// hook base64相关算法function hook_4cf88() { var base = Module.findBaseAddress("libmtguard.so"); console.log(`libmtguard.so base: ${base}`); Interceptor.attach(base.add(0x4cf88), { onEnter: function (args) { console.log("call 0x4cf88"); console.log(`sub_4cf88 args: ${args[0]}, ${args[1]}, ${args[2]}`); console.log(hexdump(args[0])); // 尝试打印native堆栈 console.log(`sub_4cf88 native stack: ${Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join('\n') + '\n'}`); }, onLeave: function (retval) { console.log(`sub_4cf88 ret: ${retval}\n`) } })} |
通过验证分析看到a5参数调用了此函数,所以分析a5:
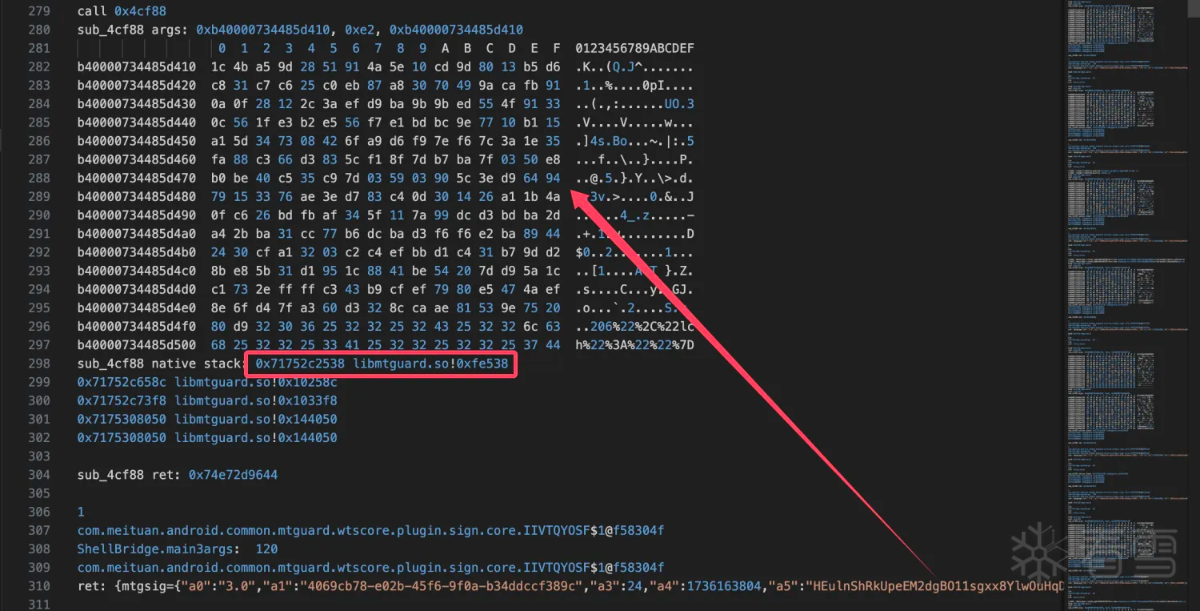
利用堆栈轻松找到调用base64的位置0xfe538:
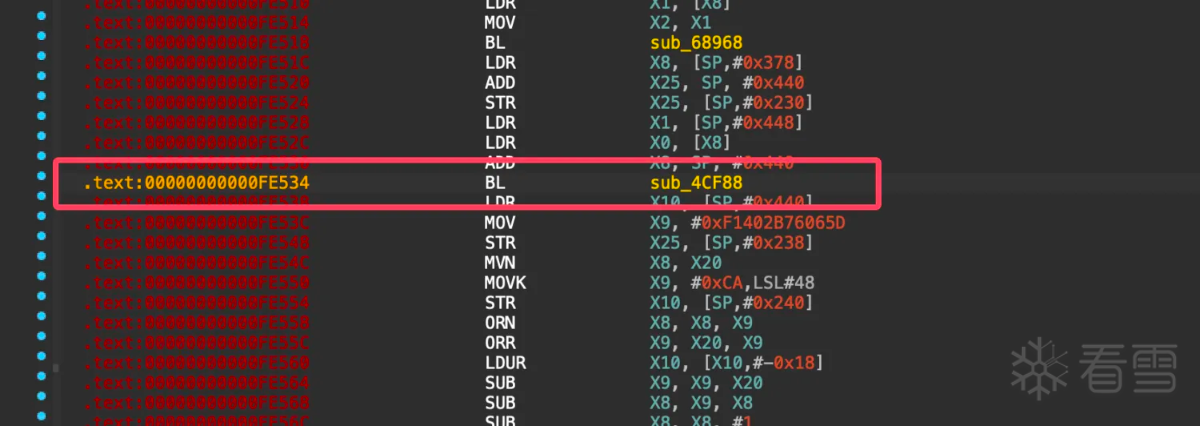
从上图可以看出确实调用了base64函数,但是此位置无法使用f5生成伪C代码,从这里向前翻查找最近的函数序言或者可能函数,查看为什么后面无法被f5,找到函数0xfdaa4如下图所示:
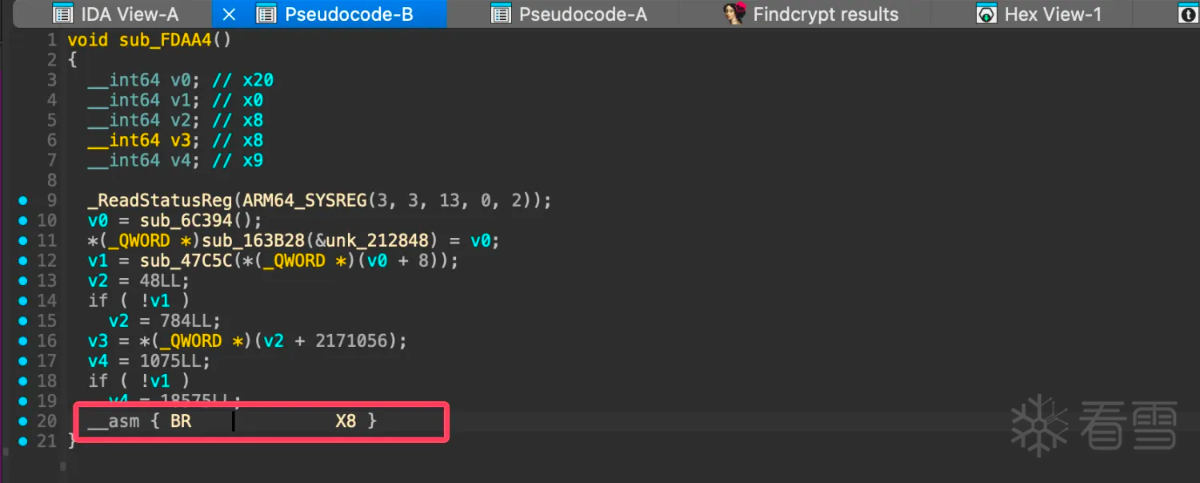
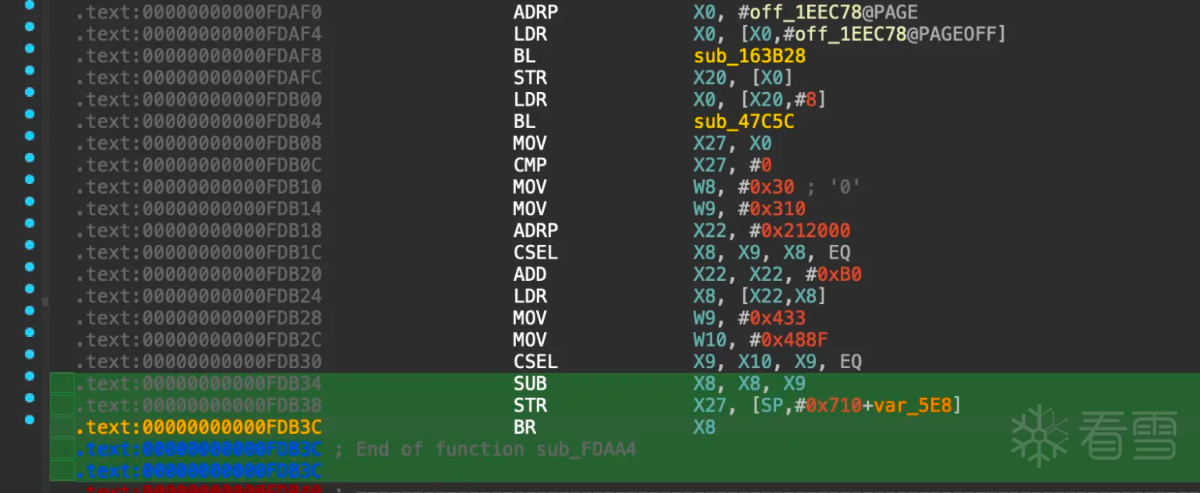
是一个BR X8的跳转,ida无法计算x8的值所以没有办法继续向下分析。
br x8跳转分析
仔细分析跳转位置的汇编指令,分析跳转的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | .text:00000000000FDB0C CMP X27, #0赋值,和后面的条件选择分支有关.text:00000000000FDB10 MOV W8, #0x30 ; '0'.text:00000000000FDB14 MOV W9, #0x310x22 赋值.text:00000000000FDB18 ADRP X22, #0x212000条件选择分支,和读取跳转表寻址相关.text:00000000000FDB1C CSEL X8, X9, X8, EQ和读取内存寻址相关,x22看着像是跳转表地址.text:00000000000FDB20 ADD X22, X22, #0xB0读取内存,和跳转相关.text:00000000000FDB24 LDR X8, [X22,X8]赋值,和条件选择语句不同条件相关.text:00000000000FDB28 MOV W9, #0x433.text:00000000000FDB2C MOV W10, #0x488F条件选择语句,和计算跳转地址相关.text:00000000000FDB30 CSEL X9, X10, X9, EQ计算 x8 = x8 - x9 和跳转寄存器相关.text:00000000000FDB34 SUB X8, X8, X9保存x27寄存器的值和跳转指令没有什么关系.text:00000000000FDB38 STR X27, [SP,#0x710+var_5E8]下面是跳转指令.text:00000000000FDB3C BR X8 |
简单阅读上面的指令,这个br逻辑可以利用现有的信息计算,看着很像是基于跳转表的跳转。用unicron模拟测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | # -*- coding: utf-8 -*-from loguru import loggerfrom capstone import Cs, CS_ARCH_ARM64, CS_MODE_ARMfrom keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIANfrom unicorn.arm64_const import UC_ARM64_REG_SP, UC_ARM64_REG_X27, UC_ARM64_REG_X8from unicorn import Uc, UC_ARCH_ARM64, UC_MODE_ARM, UC_HOOK_CODE, UC_HOOK_MEM_READ_UNMAPPED, UC_HOOK_MEM_READ# unicorn虚拟机初始化mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)# 内存区域初始化BASE_ADDR = 0x40000000BASE_SIZE = 4 * 1024 * 1024 # 4MBmu.mem_map(BASE_ADDR, BASE_SIZE)# 堆栈初始化STACK_ADDR = 0x10000000STACK_SIZE = 0x00100000mu.mem_map(STACK_ADDR, STACK_SIZE)logger.debug(f"Memory map {hex(STACK_ADDR)} - {hex(STACK_ADDR + STACK_SIZE)}")mu.reg_write(UC_ARM64_REG_SP, STACK_ADDR + STACK_SIZE)# 模拟执行汇编指令ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)assembly_code = ';'.join([ 'CMP X27, #0', 'MOV W8, #0x30', 'MOV W9, #0x310', 'ADRP X22, #0x212000', 'CSEL X8, X9, X8, EQ', 'ADD X22, X22, #0xB0', 'LDR X8, [X22,X8]', 'MOV W9, #0x433', 'MOV W10, #0x488F', 'CSEL X9, X10, X9, EQ', 'SUB X8, X8, X9', # 'STR X27, [SP,#0x128]',])# 指令转字节encoding, count = ks.asm(assembly_code.strip())logger.debug(f"Assembly code {bytes(encoding).hex()}, bytes count {count}")# 将代码写入内存mu.mem_write(BASE_ADDR, bytes(encoding))# hook 指令def hook_code(uc: Uc, address: int, size: int, user_data): # 尝试读取指令 inst = uc.mem_read(address, size) # capstone 反汇编尝试 md = Cs(CS_ARCH_ARM64, CS_MODE_ARM) for i in md.disasm(inst, address): logger.debug(f">>> {hex(i.address)}:\t{i.mnemonic}\t{i.op_str}") # 修改读取内存的值 # if address == 0x4000001c: # logger.debug(f"change x8 value") # uc.reg_write(UC_ARM64_REG_X8, 0xff68b)mu.hook_add(UC_HOOK_CODE, hook_code)# hook 读取内存def hook_mem_read(uc: Uc, access: int, address: int, size: int, value, user_data): uc.mem_write(address, int.to_bytes(1046155, 8, byteorder='little')) data = uc.mem_read(address, size) logger.debug(f">>> Tracing memory read at {hex(address)}, size: {hex(size)}, data: {data.hex()}") mu.hook_add(UC_HOOK_MEM_READ, hook_mem_read)# 启动前修改部分寄存器的值mu.reg_write(UC_ARM64_REG_X27, 1)# 启动mu.emu_start(BASE_ADDR, BASE_ADDR + (4 * count)) # 这里只执行一句指令。x8_value = mu.reg_read(UC_ARM64_REG_X8)logger.debug(f"x8 value: {hex(x8_value)}") |
利用上面模拟可以看出,是从so文件中获取跳转表,并根据不同的条件计算出不同的地址。所以这部分可以恢复,起码可以部分恢复。接下来则是需要分析这种跳转模式在当前函数中有多少,然后识别出来手动计算分支清理出跳转地址。首先需要确定当前0xfdaa4函数的范围,可以利用函数的特征或者是其他手段确认,这里可以尝试利用跳转表x22的特性确认,x22的值一般在同一个函数内是不会变化的,所以直接从函数开始搜索和x22修改读取相关的汇编指令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # 1. 搜索跳转表寄存器X22范围def get_jump_table_addr(min_addr, max_addr): cur_addr = min_addr while True: next_ea = idc.next_head(cur_addr, max_addr) if next_ea == idc.BADADDR: break insn = idc.GetDisasm(next_ea) if "X22" in insn or "W22" in insn: tmp = insn.split() if tmp[0] in ["STP", "ADD", "ADRP", "ADRL", "SUB"]: print(f"{hex(next_ea)}: {insn}, function address: {hex(idc.get_func_attr(next_ea, idc.FUNCATTR_START))}") if tmp[0] == "LDR": print(f"[maybe] {hex(next_ea)}: {insn}") cur_addr = next_ea min_addr, max_addr = 0xfdaa4, idc.BADADDRget_jump_table_addr(min_addr, max_addr) |
结果就不展示了,利用上面函数的搜索脚本可以分析出相邻函数0x100cac, elf
文件一般函数和函数之间不会出现交叉,除非有内联函数或者是其他编译优化策略共用代码块,这里就当一般情况处理。函数范围已经确定,并且通过观察ldr读取跳转表指令可以分析出都是通过x22 + 偏移量的方式寻址,这里只有偏移量计算方式的不同:
1. 立即数
2. 寄存器
3. 寄存器移位操作,这里很单一,只有LSL#3
同时按照上面的寻址方式静态分析,可以看到还有一种其他跳转方式:

这种方式比较简单,直接读取基地址,然后加减偏移量,没有条件选择。
接下来则是通过搜索匹配这些跳转位置收集信息计算地址然后patch。
首先搜索BR Xd语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | # 2. 搜索大致范围内的间接跳转地址def pattern_search_all(start_ea, end_ea, pattern_str): image_base = idaapi.get_imagebase() pattern = ida_bytes.compiled_binpat_vec_t() err = ida_bytes.parse_binpat_str(pattern, image_base, pattern_str, 16) if err: print(f"Failed to parse pattern: {err}") return found_addrs = [] curr_addr = start_ea while True: curr_addr, _ = ida_bytes.bin_search(curr_addr, end_ea, pattern, ida_bytes.BIN_SEARCH_FORWARD) if curr_addr == idc.BADADDR: break found_addrs.append(curr_addr) curr_addr += 1 return found_addrs # 保存间接跳转地址,方便后面信息收集br_addrs = []# 目前范围内暂时只发现这两种间接跳转pattern_str_1 = "00 01 1F D6" # br x8pattern_str_2 = "20 01 1F D6" # br x9tmp = pattern_search_all(min_addr, max_addr, pattern_str_1)print(f"length of search result for x8: {len(tmp)}")br_addrs.extend(tmp)tmp = pattern_search_all(min_addr, max_addr, pattern_str_2)print(f"length of search result for x9: {len(tmp)}")br_addrs.extend(tmp) |
通过上面函数收集到跳转地址之后,需要利用特征收集关键信息,将之前的两种跳转分类成条件跳转case1和无条件跳转case2.case1关键信息特征为:
- br语句。
- sub或者是add计算跳转地址
- 第二个csel条件选择跳转地址偏移量
- 真,假条件结果赋值mov语句,注意这个mov可能出现在更前面,所以这个搜索范围可以扩大。
- ldr寻址,这里需要注意三种寻址方式即可。
- 第一个csel条件选择跳转表偏移量
- 真假,条件结果赋值mov语句。
case2关键信息特征为:
- br语句
- add或者sub计算跳转地址
- mov赋值跳转地址偏移量,要转换成signed_int32
- ldr,立即数做偏移量读取跳转表
通过上面总结的特征完成信息收集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 | # 3. 从间接跳转地址,收集和跳转相关的数据信息,为后面计算真正跳转地址做准备。def gather_critical_info(addr): # 情况1: 一次比较,两次条件选择的条件跳转分支 # 情况2: 没有比较直接计算的,直接跳转情况, # 这些都是发生在第一次过滤之后。 cur_addr = addr infos = [] has_csel = False has_csel_2 = False csel_2_addr = None # 从这里搜索为了防止第一个csel条件赋值出现在第二个csel语句之前 # 倒序分析并添加信息。 # 1. br x8 insn = idc.GetDisasm(cur_addr) jump_reg = insn.split()[1] print(f"process {hex(cur_addr)}, jump register: {jump_reg}") infos.append((cur_addr, insn)) # 2. add / sub x8 for _ in range(5): prev_ea = idc.prev_head(cur_addr) insn = idc.GetDisasm(prev_ea) tmp = insn.split() # print(tmp) if tmp[0] in ['SUB', 'ADD'] and jump_reg in tmp[1]: cur_addr = prev_ea # 记录偏移寄存器 offset_reg = tmp[3] print(f"{hex(cur_addr)}: {insn}, offset register: {offset_reg}") infos.append((cur_addr, insn)) break cur_addr = prev_ea # 3. csel / mov for _ in range(5): prev_ea = idc.prev_head(cur_addr) insn = idc.GetDisasm(prev_ea) tmp = insn.split() # print(tmp) if tmp[0] in ['MOV', 'CSEL'] and offset_reg in tmp[1]: # 是否需要在move上增加更多的判断。 cur_addr = prev_ea if tmp[0] == "CSEL": # 分类处理不同的情况 has_csel = True csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '') print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}") infos.append((prev_ea, insn)) break cur_addr = prev_ea # 4. ldr [x22, xxx] for _ in range(8): prev_ea = idc.prev_head(cur_addr) insn = idc.GetDisasm(prev_ea) tmp = insn.split() # print(tmp) # print(f"has_csel: {has_csel}") if has_csel: if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]): print(f"[csel] {hex(prev_ea)}: {insn}") infos.append((prev_ea, insn)) if tmp[0] == "LDR" and "X22" in tmp[2]: print(f"{hex(prev_ea)}: {insn}") infos.append((prev_ea, insn)) if not has_csel: print("case 2 finished") return infos, has_csel return # 第二个csel指令 if tmp[0] == "CSEL": csel_2_addr = cur_addr # 先记录地址,后面再搜索相关语句。 cur_addr = prev_ea cur_addr = cur_addr if csel_2_addr is None else csel_2_addr for _ in range(5): prev_ea = idc.prev_head(cur_addr) insn = idc.GetDisasm(prev_ea) tmp = insn.split() if tmp[0] == "CSEL": cur_addr = prev_ea csel_t, csel_f = tmp[2].replace(',', ''), tmp[3].replace(',', '') print(f"{hex(prev_ea)}: {insn}, csel true: {csel_t}, csel false: {csel_f}") infos.append((prev_ea, insn)) has_csel_2 = True if has_csel_2: if tmp[0] == 'MOV' and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]): print(f"[csel] {hex(prev_ea)}: {insn}") infos.append((prev_ea, insn)) cur_addr = prev_ea # 5. 最开始的csel 真假条件的值 for _ in range(5): prev_ea = idc.prev_head(cur_addr) insn = idc.GetDisasm(prev_ea) tmp = insn.split() print(tmp) if tmp[0] == "MOV" and (csel_t[1:] in tmp[1] or csel_f[1:] in tmp[1]): print(f"[csel] {hex(prev_ea)}: {insn}") infos.append((prev_ea, insn)) cur_addr = prev_ea return infos, has_csel critical_infos = []error_count = 0for addr in br_addrs: try: info, has_csel = gather_critical_info(addr) critical_infos.append({"address": addr, "info": info, "has_csel": has_csel}) except Exception as e: error_count += 1 print(f"[gather] {hex(addr)} critical info error: {e}")print(f"gather critical info error count: {error_count}") |
通过上面函数收集到关键信息计算条件跳转地址和无条件跳转地址,并且给出patch位置。所以case1的patch思路是:
B 0xXXXXX无条件跳转替换br语句B.cond 0xXXXX替换br语句前的sub或add语句,其他语句保持不变
case2的patch思路:
B 0xXXXX直接替换br语句
利用前面的信息计算跳转地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 | # 4. 计算跳转地址x22_jump_table = 0x2120b0# 针对case2,直接跳转类型的处理def to_signed_int32(num): num &= 0xffffffff # 确保只保留 32 位 if num > 0x7fffffff: # 对于大于 2^31-1 的数 num -= 0x100000000 # 进行调整,转换为有符号表示 return num def get_real_addr_case2(info): jump_base, offset = 0, 0 patch_addr = 0 for addr, insn in reversed(info['info']): if insn.startswith("LDR"): imm_value = idc.get_operand_value(addr, 1) addr_offset = x22_jump_table + imm_value jump_base = ida_bytes.get_bytes(addr_offset, 8) jump_base = int.from_bytes(jump_base, byteorder='little') elif insn.startswith("MOV"): offset = idc.get_operand_value(addr, 1) offset = to_signed_int32(offset) elif insn.startswith("ADD"): real_addr = jump_base + offset elif insn.startswith("SUB"): real_addr = jump_base - offset elif insn.startswith("BR"): patch_addr = addr continue else: print(f"unhandled case 2 {hex(addr)}: {insn}") return None return {"addr": patch_addr, "insn": f"B {hex(real_addr)}"} # case 2 条件跳转def get_real_branch_case1(info): load_base_csel = True # 获取跳转基地址偏移量 jump_base_values = {"XZR": 0} # 计算跳转基地址偏移量的不同条件值 offset_values = {} # 不同条件下偏移量的值 cond_str = "" lsl_shift = 1 jump_base_cond_values = {} # 真假条件基地址指针偏移值 offset_cond_values = {} # 真假条件偏移量值 offset_calculator = '' patch_cond_addr, patch_uncond_addr = 0, 0 for addr, insn in reversed(info['info']): if insn.startswith("MOV") and load_base_csel: # 第一个casl处理 imm_value = idc.get_operand_value(addr, 1) reg_name = insn.split()[1].replace('W', 'X').replace(',', '') jump_base_values[reg_name] = imm_value elif insn.startswith("CSEL") and load_base_csel: tmp = insn.split() cond_str = tmp[4].strip().replace(',', '') true_reg = tmp[2].replace('W', 'X').replace(',', '') false_reg = tmp[3].replace('W', 'X').replace(',', '') jump_base_cond_values['cond'] = cond_str jump_base_cond_values['true'] = jump_base_values[true_reg] jump_base_cond_values['false'] = jump_base_values[false_reg] load_base_csel = False elif insn.startswith("LDR"): if "LSL" in insn: lsl_shift = 8 print(f"ldr insn has lsl") continue elif insn.startswith("MOV") and not load_base_csel: # 处理第二个csel imm_value = idc.get_operand_value(addr, 1) reg_name = insn.split()[1].replace('W', 'X').replace(',', '') offset_values[reg_name] = imm_value elif insn.startswith("CSEL") and not load_base_csel: tmp = insn.split() cond_str = tmp[4].strip().replace(',', '') true_reg = tmp[2].replace('W', 'X').replace(',', '') false_reg = tmp[3].replace('W', 'X').replace(',', '') offset_cond_values['cond'] = cond_str offset_cond_values['true'] = offset_values[true_reg] offset_cond_values['false'] = offset_values[false_reg] elif insn.startswith("SUB"): offset_calculator = 'SUB' patch_cond_addr = addr elif insn.startswith('ADD'): offset_calculator = 'ADD' patch_cond_addr = addr elif insn.startswith('BR'): patch_uncond_addr = addr continue else: print(f"unhandled case 1 {hex(addr)}: {insn}") if jump_base_cond_values['cond'] == offset_cond_values['cond']: jump_base_true_addr = x22_jump_table + jump_base_cond_values['true'] * lsl_shift jump_base_true = ida_bytes.get_bytes(jump_base_true_addr, 8) jump_base_true = int.from_bytes(jump_base_true, byteorder='little') jump_base_false_addr = x22_jump_table + jump_base_cond_values['false'] * lsl_shift jump_base_false = ida_bytes.get_bytes(jump_base_false_addr, 8) jump_base_false = int.from_bytes(jump_base_false, byteorder='little') if offset_calculator == 'SUB': real_addr_true = jump_base_true - offset_cond_values['true'] real_addr_false = jump_base_false - offset_cond_values['false'] elif offset_calculator == 'ADD': real_addr_true = jump_base_true + offset_cond_values['true'] real_addr_false = jump_base_false + offset_cond_values['false'] return [ {"addr": patch_cond_addr, "insn": f"B.{offset_cond_values['cond']} {hex(real_addr_true)}"}, {"addr": patch_uncond_addr, "insn": f"B {hex(real_addr_false)}"} ] else: return None error_count = 0patch_list = []for info in critical_infos: try: if info['has_csel']: print("#" * 16) patch_info = get_real_branch_case1(info) print(f"[case 1] {hex(info['address'])}") print(patch_info) patch_list.extend(patch_info) else: print("#" * 16) patch_info = get_real_addr_case2(info) print(f"[case 2] {hex(info['address'])}") print(patch_info) patch_list.append(patch_info) except Exception as e: print(f"[error] process {hex(info['address'])} error: {e}") print(info) error_count += 1 print(f"calculate jump addr error count: {error_count}") |
上面的寄存器值从之前的unicorn模拟执行中可以找到,至此差不多就完全将逻辑替换完成了,只剩最后一步将语句patch进去
1 2 3 4 5 6 7 | # 5. keystone将汇编指令转字节并替换到so文件中ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)for info in patch_list: encoding, count = ks.asm(info['insn'], addr=info['addr']) asm_bytes = bytes(encoding) print(f"{hex(info['addr'])}: {asm_bytes.hex()}") ida_bytes.patch_bytes(info['addr'], asm_bytes) |
清理之后的结果
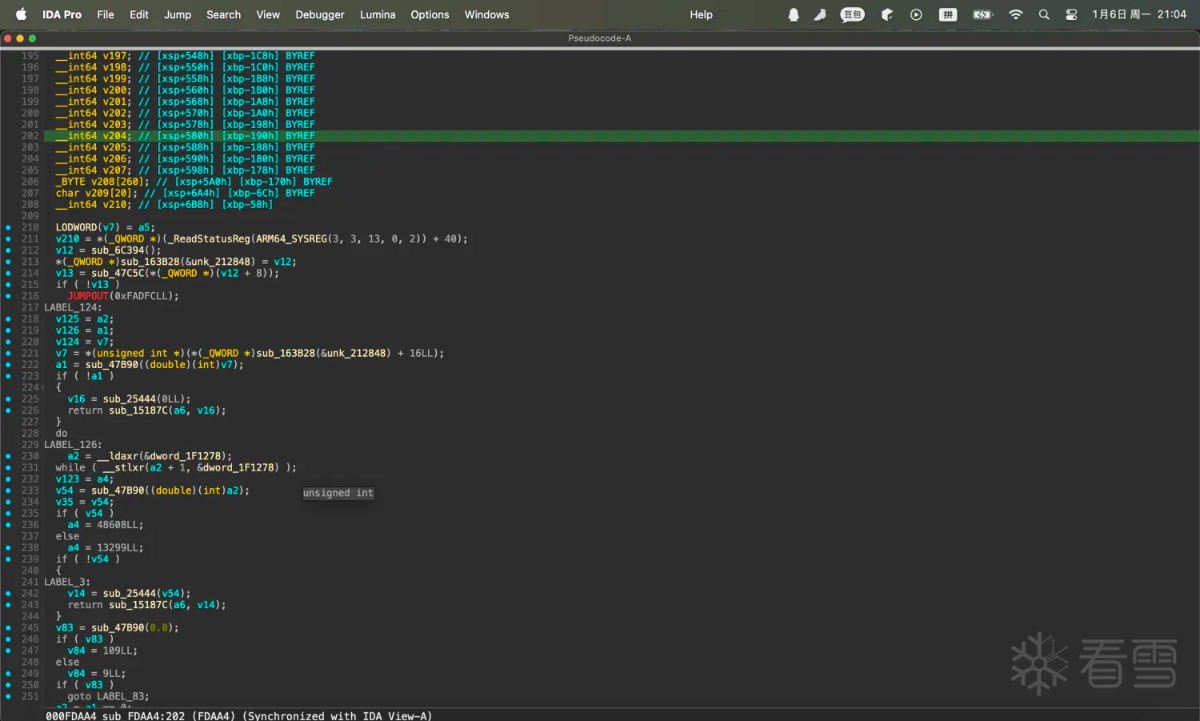
算法分析
清理完成之后这个函数大致就可以静态分析。回到最初调用base64函数的部分:
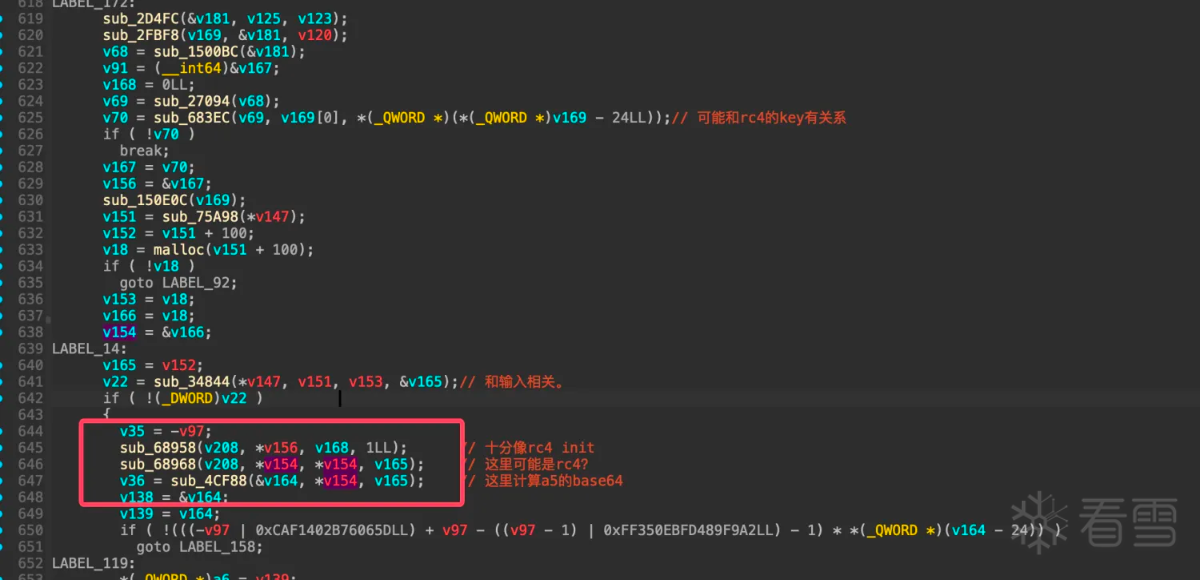
直接hook函数sub_4cf88和函数sub_68968因为两个函数都有统一个参数v154:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | // hook maybe rc4 encryptfunction hook_68968() { var base = Module.findBaseAddress("libmtguard.so"); Interceptor.attach(base.add(0x68968), { onEnter: function(args) { console.log("call sub_68968"); console.log(`[sub_68968] ${args[0]}, ${args[1]}, ${args[2]}, ${args[3]}`); console.log(`[sub_68968] args[0]: ${hexdump(args[0])}`); console.log(`[sub_68968] args[1]: ${hexdump(args[1], {length: 256})}`); this.arg1 = args[1]; }, onLeave: function(retval) { console.log(`[sub_68968] retval = ${hexdump(retval)}`); console.log(`[sub_68968] ret args1 = ${hexdump(this.arg1)}`); } })}// hook base64相关算法function hook_4cf88() { var base = Module.findBaseAddress("libmtguard.so"); console.log(`libmtguard.so base: ${base}`); Interceptor.attach(base.add(0x4cf88), { onEnter: function (args) { console.log("call 0x4cf88"); console.log(`sub_4cf88 args: ${args[0]}, ${args[1]}, ${args[2]}`); console.log(hexdump(args[0])); // 尝试打印native堆栈 console.log(`sub_4cf88 native stack: ${Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress).join('\n') + '\n'}`); }, onLeave: function (retval) { console.log(`sub_4cf88 ret: ${retval}\n`) } })} |
hook结果对比:
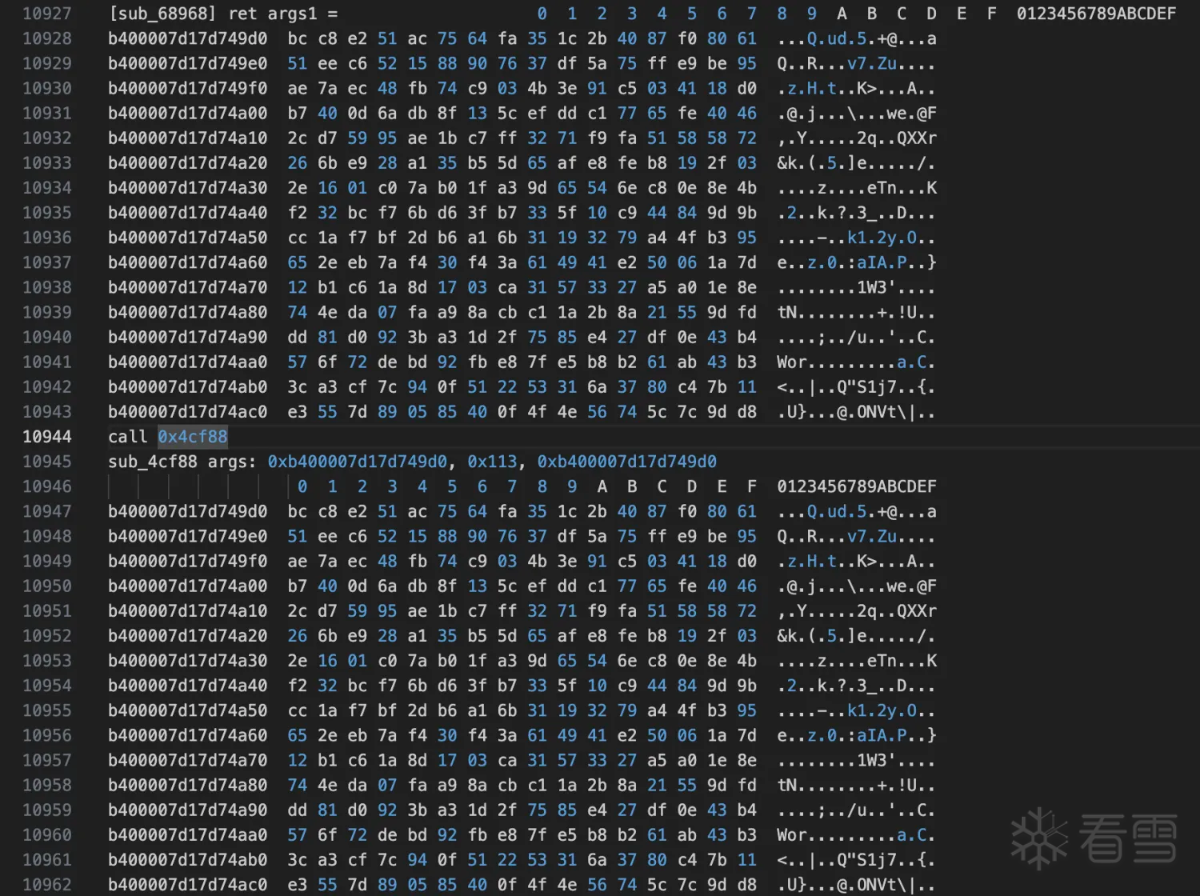
可以看出sub_68968的结果和base64函数的输入一致。进入函数sub_68968看到如下:

进入函数sub_10f0f8:
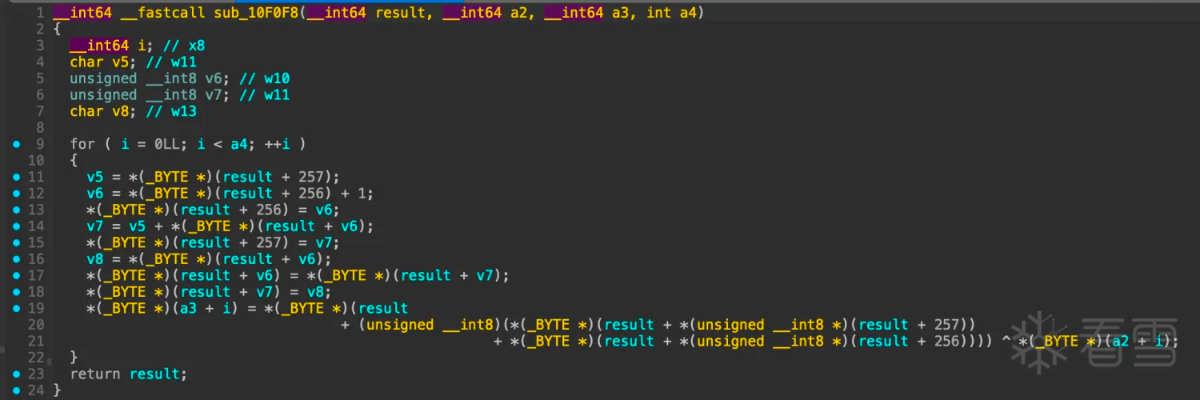
看着好像是rc4加密,搜索一份c语言rc4加密函数对比:
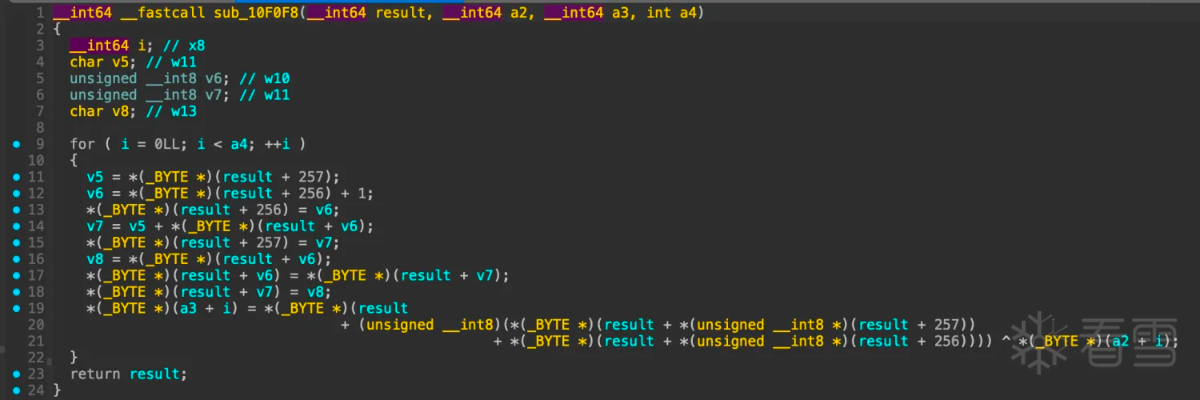

对比起来看真的很像,如果是rc4,那么result应该是sbox,接着看函数sub_68958,hook验证
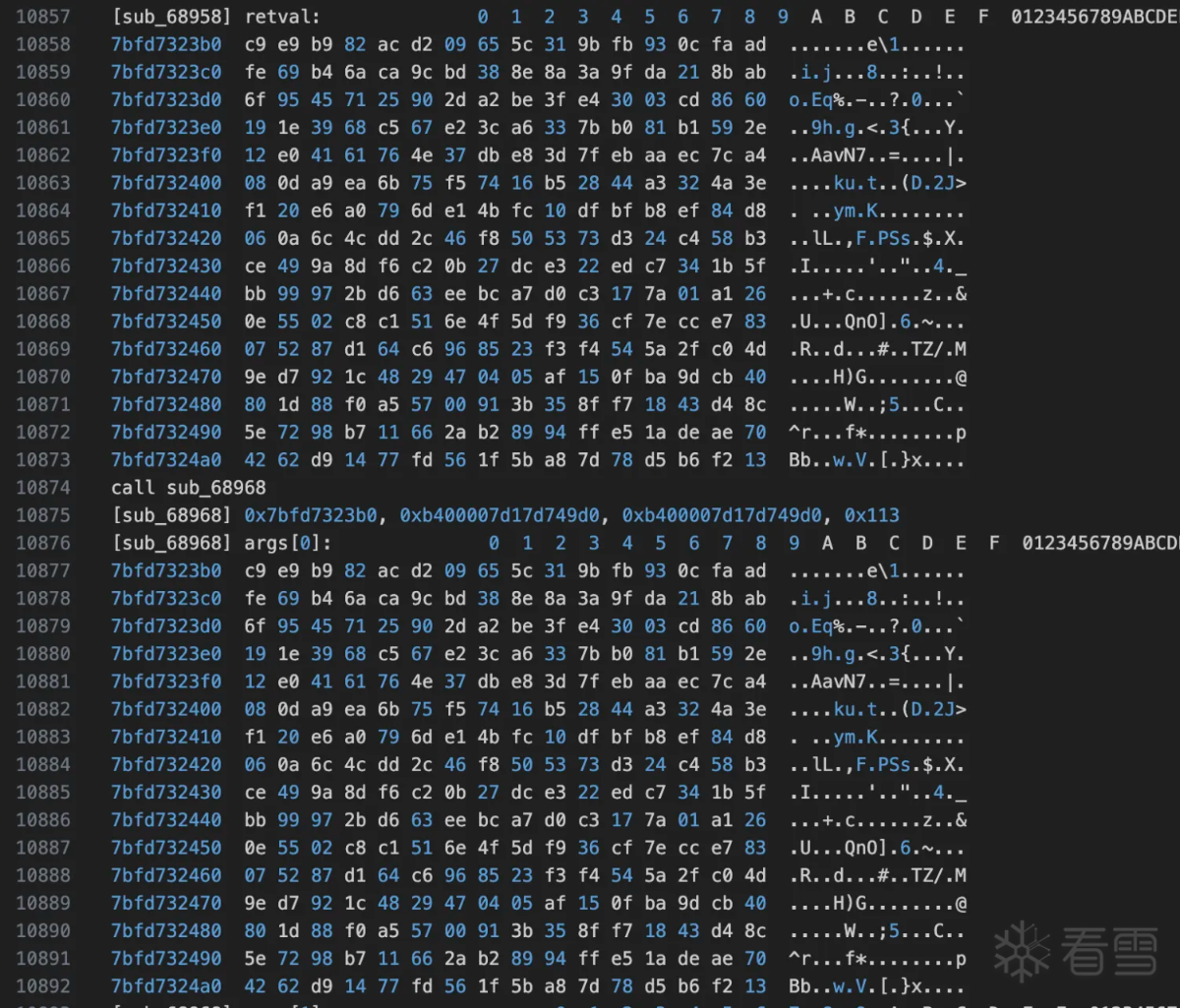
那么sub_68958极有可能是rc4 init函数:
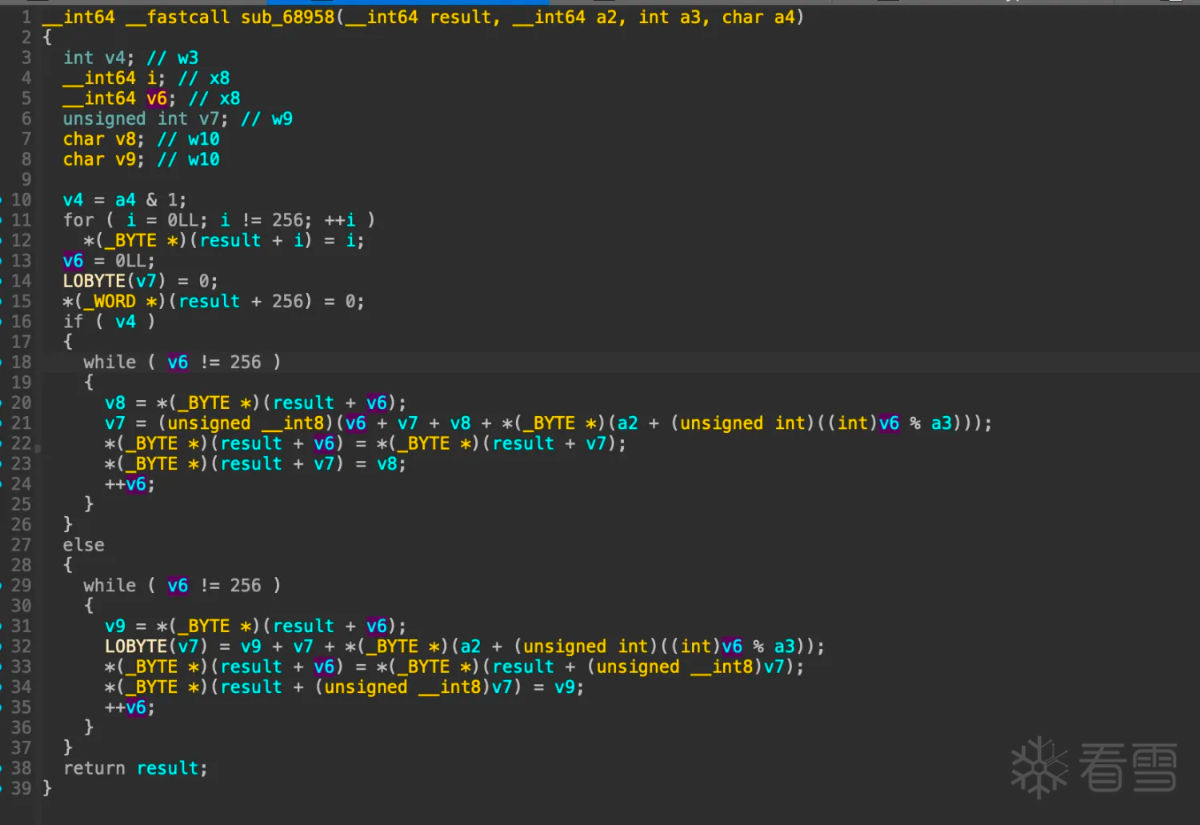
网上搜索rc4 init函数:

好像在rc4 init 过程中多加了一个下标i。先看看key是啥,然后写代码验证魔改位置, 从网上抄个python版本的rc4 init:
1 2 3 4 5 6 7 8 9 10 | def KSA(key): """ Key-Scheduling Algorithm (KSA) """ S = list(range(256)) j = 0 for i in range(256): # j = (j + S[i] + key[i % len(key)]) % 256 # 多增加一个下标 j = (i + j + S[i] + key[i % len(key)]) % 256 S[i], S[j] = S[j], S[i] return S |
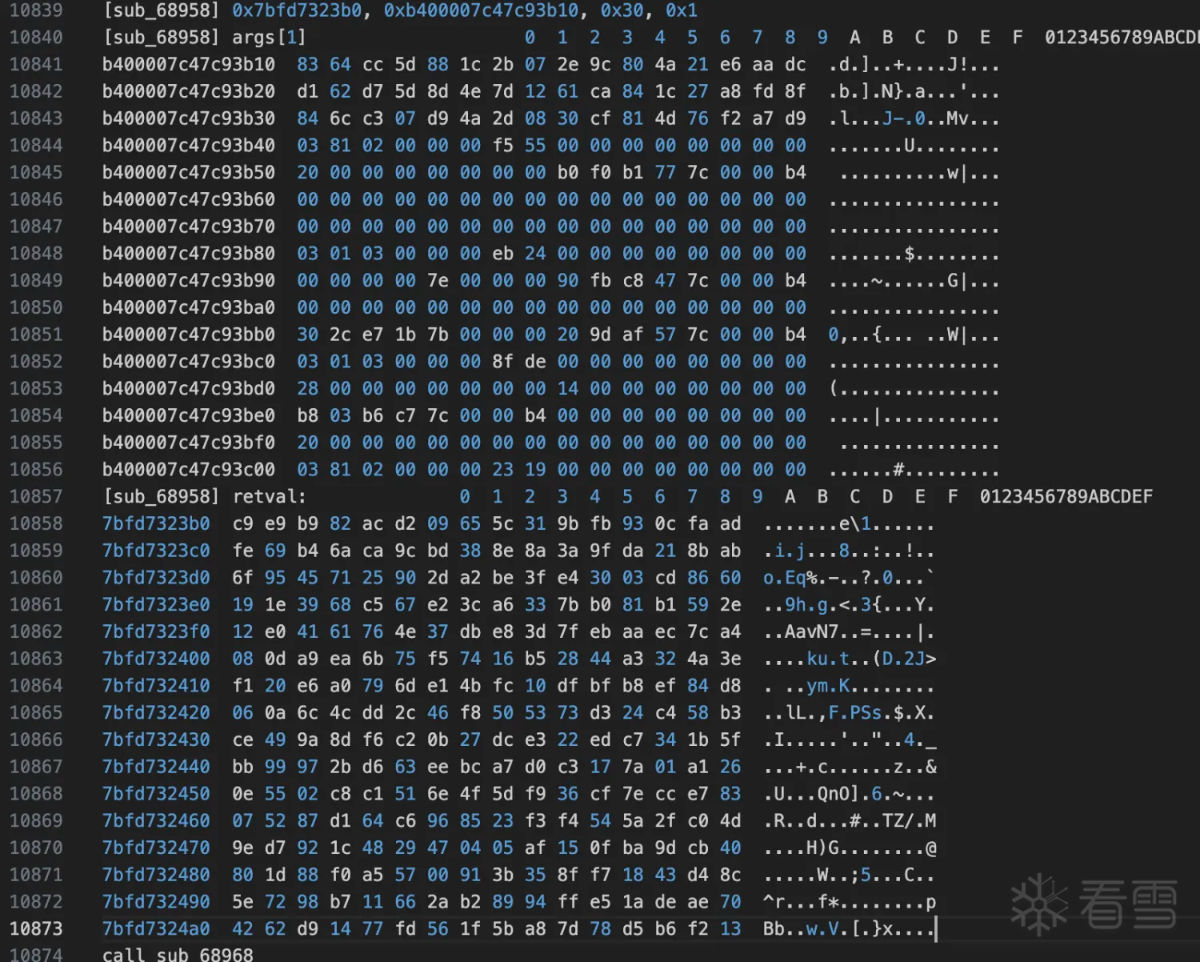
将上面的key带入到修改的rc4 init中:得到如下结果:

验证通过的确是修改了rc4 init函数中的部分。接着看rc4的输入数据然后统一验证。继续向上查看sub_34844函数是和输入相关的
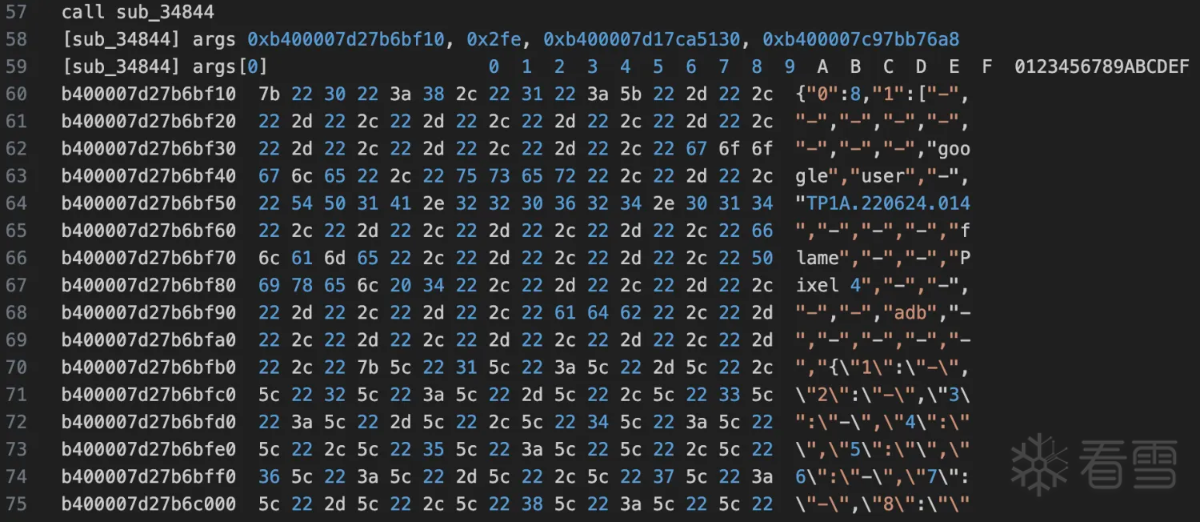
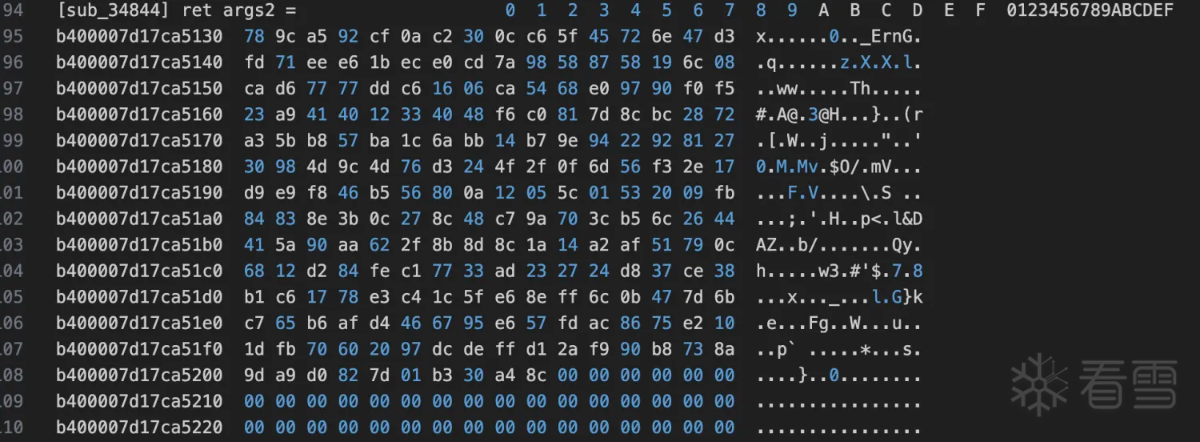
从上面可以看出是一个json字符串应该是一些设备信息相关的压缩后得到的,开头两个字节zlib的默认压缩方式。接着需要看rc4的key是什么,因为每次hook输入的key都是变化的。
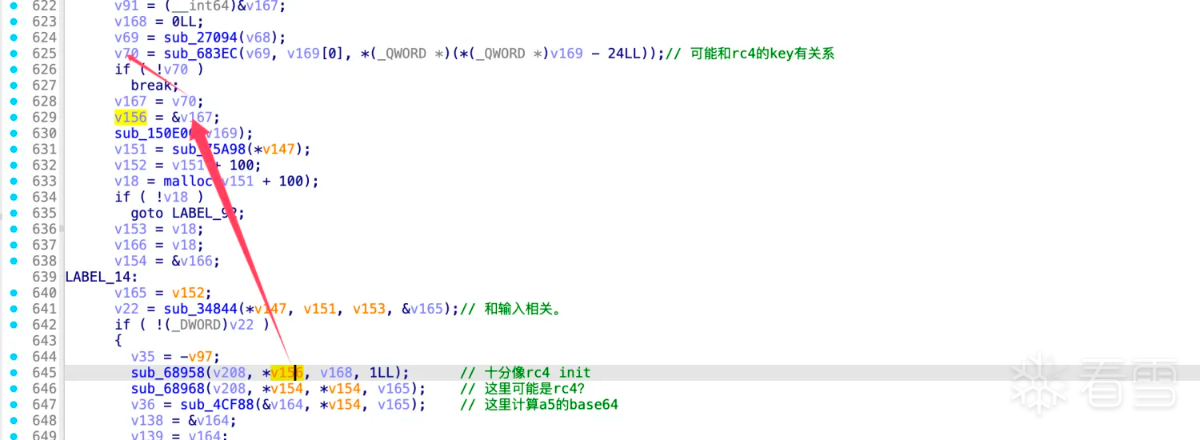
所以函数sub_683ec应该是计算rc4 key的,hook验证:
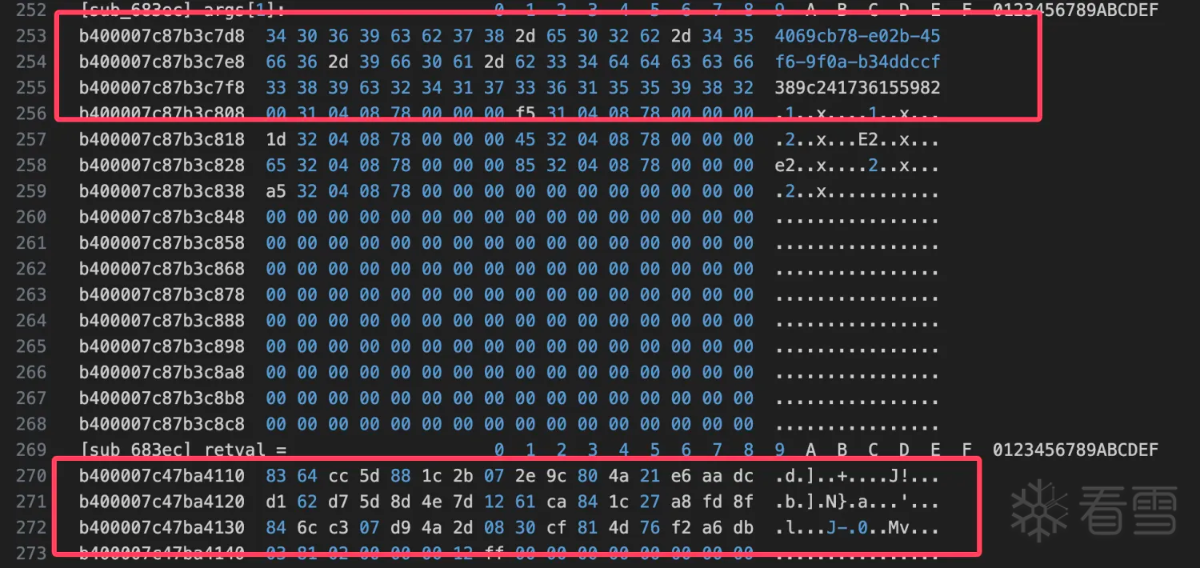

两个函数的数据对比没有问题确实如此。至此算法流程还是比较清晰的,下面用python简单验证一下hook日志中的数据。首先是rc4 算法key的生成:
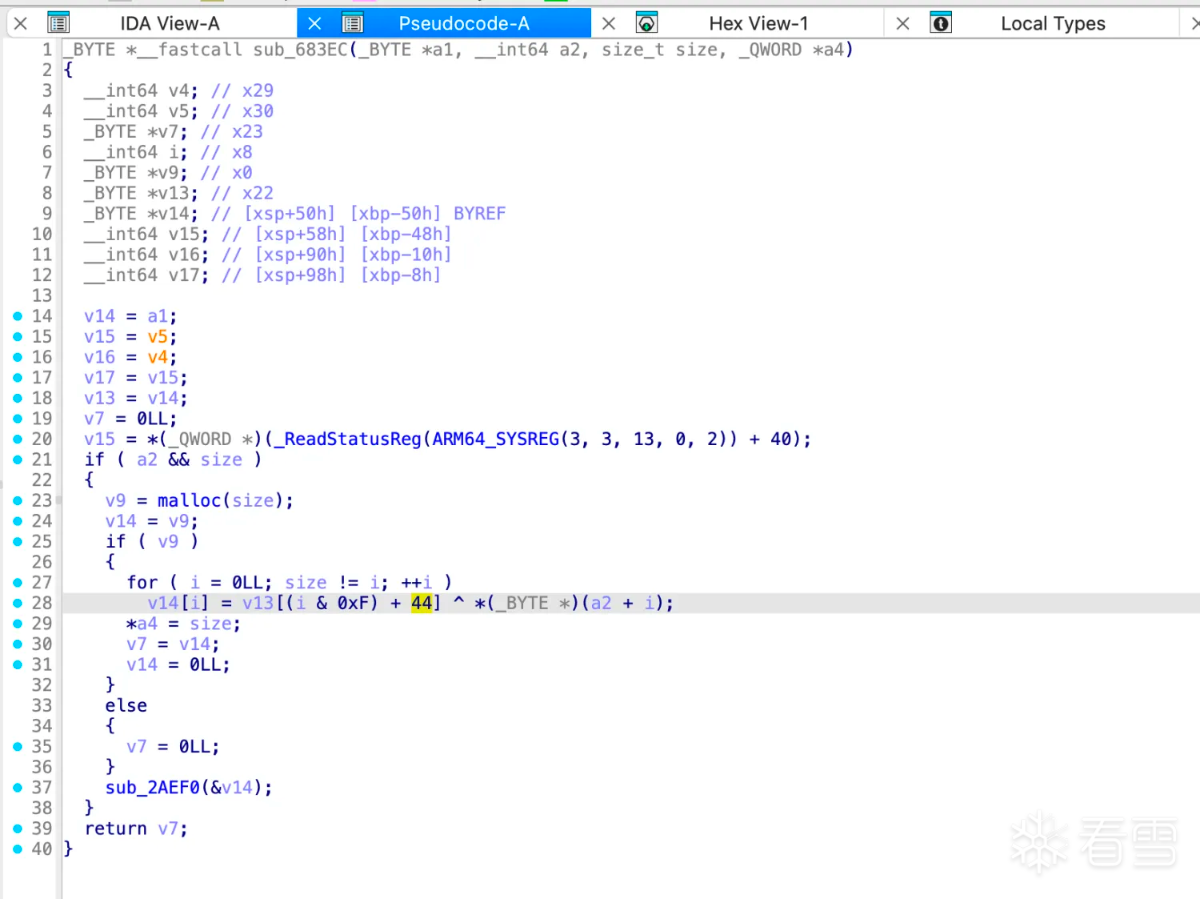
从上图看着是和v13异或得到,那么将输入和结果异或即可得到v13:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | key_str = "4069cb78-e02b-45f6-9f0a-b34ddccf389c241736155982"key_res = "8364cc5d881c2b072e9c804a21e6aadcd162d75d8d4e7d1261ca841c27a8fd8f846cc307d94a2d0830cf814d76f2a6db"v13 = []for a, b in zip(key_str.encode(), bytes.fromhex(key_res)): v13.append(a ^ b)print(bytes(v13).hex())v13_str = bytes(v13).hex()print(v13_str[:32])print(v13_str[32:64])# b754fa64eb7e1c3f03f9b07843cb9ee9b754fa64eb7e1c3f03f9b07843cb9ee9b754fa64eb7e1c3f03f9b07843cb9ee9# b754fa64eb7e1c3f03f9b07843cb9ee9# b754fa64eb7e1c3f03f9b07843cb9ee9 |
取多次hook结果验证这个在同一个机器上起码是不变的。
算法总结
a5 第一版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 | # -*- coding: utf-8 -*-import zlibimport jsonimport base64from itertools import cycle'''ret: { mtgsig = { "a0": "3.0", "a1": "4069cb78-e02b-45f6-9f0a-b34ddccf389c", "a3": 24, "a4": 1736155982, "a5": "AHepznjTBvV7rHiYm8hD1+169lwTCD+PNAA6LuQx6hGIgKX2FHR3ADYlwF38q/j8dk6sKm+PO57A3AKiYH4RX1FE7Cyy8UkEwWceQURrxfHX2O7LqWtfwYCsTtE0kUoXW4aGxaAiAagM2KtS81ff/NZUgIYvdaLeiljIXbHGV+6QtbotS6/ClGky4cd1RHy7GZsJ8ubecJjv4QKLxAq4cHgsro4z9Iboi4gYCi+dTStYrEWEPRAhk9VPX3oQHeqlpRrqxGQxCbGUWjjEi/CNjuuF7W8xEnTNq0zOY/YO", "a6": 0, "a7": "jSAxPWen3i2zs6omj1rD+uRsiQhiPxEE1CA+76YkCHDQqmp25ELpd3PUR0uWoNZ0eAc0RLxbkZrYsmQwKjqe27lZZ8o95TEOOSQLRo8bHYA=", "a8": "742b25deffb779f5ed08910789926e676ca5f078d42b28d5c7dd370c", "a9": "dd051dd5C+3hWx/JTxImXsb+pQWQL/bklyGy4z5sN8nq7p/2yW7SAN9GsygMJe3E3IzoY912YiZ0iCnsGiPPRB6lrUP2uehxqbJlpkuyNQwe7Eh5WcvUlzYW39m7Rh5PNTZhoAUnM7NBMbYqz+WK2hslAUX8mSaQJyebUz8jOxMc7RAdK7SOXFxNX+Mcs/RN2nED0lzB4ZF/I8CFMZHjE5cBAKpeXsQaYalSlK9D50zxK/0sjdlc/knfNcMFq5hFfYz8UDPP4OCeHI/U5YcgrsbgxDH41Qs6bmBF+5YoHT+pKsxc3uc=", "a10": "5,155,1.1.1", "x0": 1, "a2": "673fb25da2fb9e3cb2eff5b39b152559" }}'''# xor生成keyxor_value = bytes.fromhex("b754fa64eb7e1c3f03f9b07843cb9ee9")# a1 + a3 + a4rc4_key_in = "4069cb78-e02b-45f6-9f0a-b34ddccf389c241736155982"rc4_key = bytes([a ^ b for a, b in zip(rc4_key_in.encode(), cycle(xor_value))])print(rc4_key.hex())# 设备信息device_json = { 'b1': '{"1":"-","2":"-","3":"-","4":"","5":"","6":"-","7":"-","8":"","9":"","10":"-","11":"-","12":"1|26|100","13":"-","14":"-","15":"-","16":"-","33":{"0":0,"1":"-","2":"-","3":"-","4":"-","5":"-","6":"-","7":"-","8":"-","9":"-","10":"-","11":"-","12":"-","13":"-","14":"-","15":"-","16":"-","17":"-"}}', 'b2': 3, 'b3': 0, 'b4': 'com.dianping.v1', 'b5': '11.30.13', 'b6': '113013', 'b7': 1736155982, 'b8': 1736155982, 'b9': 1736155982, 'b10': '6.4.8', 'b11': '6.4.8', 'b12': '2', 'b13': 1, 'b17': 1, 'b18': 3, 'b19': ':', 'b16': '[0,0,0],[0,0,0],[0,0,0],0', 'b20': 0, 'b21': 0}device_json_str = json.dumps(device_json, separators=(',', ':'))rc4_in = zlib.compress(device_json_str.encode())print(rc4_in.hex())# rc4 加密def KSA(key): """ Key-Scheduling Algorithm (KSA) """ S = list(range(256)) j = 0 for i in range(256): j = (i + j + S[i] + key[i % len(key)]) % 256 S[i], S[j] = S[j], S[i] return S def PRGA(S): """ Pseudo-Random Generation Algorithm (PRGA) """ i, j = 0, 0 while True: i = (i + 1) % 256 j = (j + S[i]) % 256 S[i], S[j] = S[j], S[i] K = S[(S[i] + S[j]) % 256] yield K def RC4(key, text): """ RC4 encryption/decryption """ S = KSA(key) keystream = PRGA(S) res = [] for char in text: res.append(char ^ next(keystream)) return bytes(res)rc4_encrypted = RC4(rc4_key, rc4_in)print(rc4_encrypted.hex())# base64a5 = base64.b64encode(rc4_encrypted)print(a5.decode()) |
总结
- patch跳转语句如果在str寄存器之前则会导致不保存数据,这导致和之前执行结果不一致。
- 分支计算正确与否没有测试,而且也不保证拿着其他上下文插入到计算跳转地址中。
更多【Android安全-大众DP BR X8跳转清理 && a5分析】相关视频教程:www.yxfzedu.com
相关文章推荐
- CTF对抗-Realworld CTF 2023 ChatUWU 详解 - Android安全CTF对抗IOS安全
- Android安全-frida源码编译详解 - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:新建节并插入代码 - Android安全CTF对抗IOS安全
- 加壳脱壳- UPX源码学习和简单修改 - Android安全CTF对抗IOS安全
- 二进制漏洞-win越界写漏洞分析 CVE-2020-1054 - Android安全CTF对抗IOS安全
- Pwn-2022长城杯决赛pwn - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter服务端 - Android安全CTF对抗IOS安全
- Pwn-沙箱逃逸之google ctf 2019 Monochromatic writeup - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com