论文阅读-大模型相关论文笔记
推荐 原创Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
用于知识密集型NLP任务的检索增强生成
Facebook 2020
PDF
CODE
(论文代码链接已失效,以上是最新链接)
引言
大模型有幻觉问题(hallucinations),检索增强生成(retrieval-augmented generation, RAG)可以解决它。
方法
输入为x,外部检索资源为z,生成目标序列y。
模型有两块:一个检索器 p η ( z ∣ x ) p_\eta(z|x) pη(z∣x), η \eta η为参数,给定一个查询q,根据文本返回top-K个分布;一个生成器 p θ ( y i ∣ x , z , y 1 : i − 1 ) p_\theta(y_i|x,z,y_{1:i-1}) pθ(yi∣x,z,y1:i−1),参数为 θ \theta θ,它基于过去i-1个tokens y 1 : i − 1 y_{1:i-1} y1:i−1、原始输入x和检索器信息z,产生一个当前的token。
为了端到端的训练检索器和生成器,我们将检索文档作为一个隐变量。我们提出了两个模型,他们以不同的方式边缘化隐变量,从而在文本上产生分布。在我们的方法里,第一步,RAG-Sequence,这个模型使用相同的文本预测每一个目标token;第二步,RAG-Token,基于不同的文件预测每一个目标token。
模型
- RAG-Sequence模型
p R A G − S e q u e n c e ( y ∣ x ) ≈ ∑ z ∈ t o p − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) p θ ( y ∣ x , z ) = ∑ z ∈ t o p − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) ∏ i N p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Sequence}(y|x)≈\sum_{z∈top-k(p(·|x))}p_\eta(z|x)p_\theta(y|x,z)=\sum_{z∈top-k(p(·|x))}p_\eta(z|x)\prod^N_ip_\theta(y_i|x,z,y_{1:i-1}) pRAG−Sequence(y∣x)≈z∈top−k(p(⋅∣x))∑pη(z∣x)pθ(y∣x,z)=z∈top−k(p(⋅∣x))∑pη(z∣x)i∏Npθ(yi∣x,z,y1:i−1) - RAG-Token模型
p R A G − T o k e n ( y ∣ x ) ≈ ∏ i N ∑ z ∈ t o p − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{RAG-Token}(y|x)≈\prod^N_i\sum_{z∈top-k(p(·|x))}p_\eta(z|x)p_\theta(y_i|x,z,y_{1:i-1}) pRAG−Token(y∣x)≈i∏Nz∈top−k(p(⋅∣x))∑pη(z∣x)pθ(yi∣x,z,y1:i−1)
检索器:DPR
DPR(Dense Passage Retriever),密集信息检索器
检索器 p η ( z ∣ x ) p_\eta(z|x) pη(z∣x)基于DPR。DPR是一个双向编码器架构:
p η ( z ∣ x ) ∝ e x p ( d ( z ) T q ( x ) ) d ( z ) = B E R T d ( z ) , q ( x ) = B E R T q ( x ) p_\eta(z|x)∝exp(d(z)^Tq(x)) ~~~ d(z)=BERT_d(z), q(x)=BERT_q(x) pη(z∣x)∝exp(d(z)Tq(x)) d(z)=BERTd(z),q(x)=BERTq(x)
其中,d(z)是使用BERT编码得到的密集表示,q(x)是问题通过BERT编码得到的表示。计算top-k( p η ( ⋅ ∣ x ) p_\eta(·|x) pη(⋅∣x))是一个MIPS(Maximum Inner Product Search)问题,可以在亚线性时间内解决。我们使用一个基于DPR的预训练双向编码器来初始化我们的检索器并建立索引,将其视为非参数记忆(non-parametric memory)。
生成器:BART
生成器可以使用任何编码器-解码器。我们使用的是BART-large。
训练
求最小似然log-likelihood、Adam
解码
- RAG-Toke
p θ ′ ( y i ∣ x , y 1 : i − 1 ) = ∑ z ∈ t o p − k ( p ( ⋅ ∣ x ) ) p η ( z i ∣ x ) p θ ( y i ∣ x , z i , y 1 : i − 1 ) p^{'}_\theta(y_i|x,y_{1:i-1})=\sum_{z∈top-k(p(·|x))}p_\eta(z_i|x)p_\theta(y_i|x,z_i,y_{1:i-1}) pθ′(yi∣x,y1:i−1)=z∈top−k(p(⋅∣x))∑pη(zi∣x)pθ(yi∣x,zi,y1:i−1)
将 p θ ′ ( y i ∣ x , y 1 : i − 1 ) p^{'}_\theta(y_i|x,y_{1:i-1}) pθ′(yi∣x,y1:i−1)送入标准beam解码器中。 - RAG-Sequence
Thorough Decoding
Fast Decoding
FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: 具有IO感知的快速和有效存储精确注意力
2022年6月24日
PDF
CODE
摘要
自注意力的时间和空间复杂度在序列长度上是二次关系,近似注意力机制尝试在模型质量和复杂度计算中折中来解决该问题,但是经常不能实现wall-clock加速。本文认为,需要一种规范,可以根据GPU读写水平使注意力IO感知。为此,本文提出FLASHATTENTION,一种IO感知的精确注意力机制,它使用tiling技术来减少GPU HBM(high bandwidth memory)和GPU芯片内SRAM的存储读写次数。FLASHATTENTION相比标准注意力机制要减少这方面开销。
引言
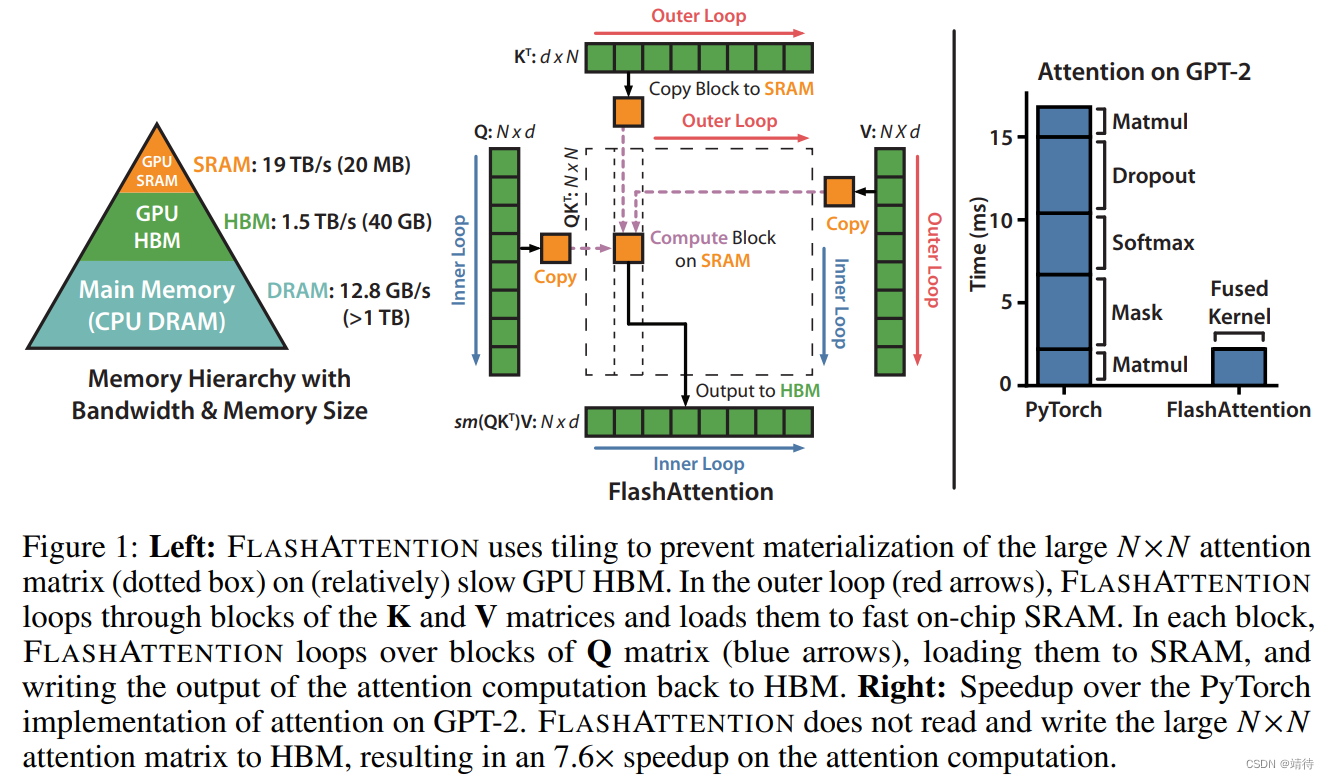
现代GPU的计算速度比存储速度快,在Transformer里的许多操作都受限于存储接入。现在的公共Python接口,比如PyTorch和Tensorflow对于内存接入没有精细化管理。本文提出FLASHATTENTION,一种计算注意力时减少内存接入操作的新注意力算法。它的目标是减少在HBM中读写的注意力矩阵。这需要
(1)在不访问整体输入的情况下计算softmax reduction;
(2)反向传播时不存大量中间过程的注意力矩阵。
本文提出两种方法解决上面的问题。
(1)我们重新构建了注意力计算模块,将输入分块,在输入块中形成多个通道,因此递增地执行softmax reduction(也就是tiling);
(2)从前向传播到反向传播中快速重新计算片上注意力,我们存储了其中的softmax标准化因素,这比从HBM读取中间注意力矩阵的标准方法要快。
在CUDA使用FLASHATTENTION去实现精细化存储控制以及在GPU内核中融合所有的注意力操作。即使因为重计算会增加FLOP(Floating Point Operations),相对于标准注意力而言,我们的算法依然更快、需要更少的内存,在序列长度上是线性的,这是因为HBM的接入大量减少。
FLASHATTENTION在HBM上的复杂度是O(N2d2M^{-1}),其中d是头head的维度,M是SRAM的规模,标准注意力的复杂度是 Ω ( N d + N 2 ) Ω(Nd+N^2) Ω(Nd+N2)。
本文贡献点:
- 更快的模型训练速度
- 更高的模型质量
- 比现有基线注意力都要快
背景
硬件性能
重点描述GPU。
- GPU存储等级
HBM、SRAM - 执行模型
GPU有很多线程去执行一个操作(称为核)。每个核从HBM登记加载输入,SRAM计算,再将输出写入HBM。 - 性能特点
- 计算密集型Compute-bound
- 存储密集型Memory-bound
- 内核融合
最常见的加速存储密集操作的就是内核融合。如果多个操作同时应用在相同的输入时,可以从HBM一次性加载输入。编译器会自动融合许多elementwise操作。然而,根据模型训练的上下文,中间过程的值为了反向传播仍然需要写入HBM,这降低了原生内核融合的效率。
标准注意力
输入序列 Q , K , V ∈ R N × d Q,K,V∈\mathbb{R}^{N×d} Q,K,V∈RN×d,其中N是序列长度,d是头head维度。我们想要计算注意力输出 O ∈ R N × d O∈\mathbb{R}^{N×d} O∈RN×d。
S = Q K T ∈ R N × N , P = s o f t m a x ( S ) ∈ R N × N , O = P V ∈ R N × d S=QK^T∈\mathbb{R}^{N×N}, P=softmax(S)∈\mathbb{R}^{N×N}, O=PV∈\mathbb{R}^{N×d} S=QKT∈RN×N,P=softmax(S)∈RN×N,O=PV∈RN×d
softmax按行(row-wise)使用。
标准注意力将S和P扔给HBM,这花费了 O ( N 2 ) O(N^2) O(N2)存储。一般来说,N>>d,比如GPT2里N=1024,d=64。大部分操作是存储密集型(比如softmax),大量的存储读写造成wall-clock时间变慢。
其它操作更加加剧了这个问题,比如加在注意力矩阵的elementwise操作、加在S上的遮罩或者加在P上的dropout。为此,有很多融合几种elementwise操作的方法尝试,比如一些文献用softmax融合遮罩。

FLASHATTENTION
两种方法:tiling和recomputation
主要思路:将输入的Q、K、V分块,将它们从慢的HBM放到快的SRAM中,计算了注意力输出后再返回到各自块里。在每个快的输出相加之前,通过标准化进行缩放,最终得到结果。
- Tiling
- Recomputation
我们的目标之一是不要存储反向传播中间过程值 O ( N 2 ) O(N^2) O(N2)。反向传播需要矩阵 S , P ∈ R N × N S,P∈\mathbb{R}^{N×N} S,P∈RN×N来计算Q、K、V的梯度。

LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
大模型的低秩适配器
微软 2021年
Low-Rank Adaptation, LORA
PDF
CODE
冻结预训练模型的参数,在Transformer架构每一层注入一个可训练的低秩分解矩阵(rank decomposition matrices),大幅减少了下游任务的训练参数。
对比GPT-3 175B Adam微调,LoRA可以减少10000倍训练参数、3倍GPU存储。
对比RoBERTa, DeBERTa, GPT-2, GPT-3,训练参数虽少,模型微调质量更好,更高的训练吞吐量,而且不像适配器,没有额外的推理延迟。
引言
微调会更新预训练模型的全部参数,下游任务的新模型和原模型参数一样多。许多研究者通过只更新部分参数或学习新任务的额外模块进行迁移,这样可以只保存和加载一小部分任务相关的参数即可,部署时提高了效率。但是现有方法通过延伸模型深度或者减少模型可用的序列长度会导致推理延迟。而且这些策略达不到微调的基线效果,在效率和模型质量上做了折中。
问题陈述
给定一个预训练自回归语言模型 P Φ ( y ∣ x ) P_{\Phi}(y|x) PΦ(y∣x), Φ \Phi Φ为参数。将该模型用于下游任务。全量微调的话,模型将用预训练的权重 Φ 0 \Phi_0 Φ0作为初始化参数,并使用下方梯度计算公式来最大化目标以更新到 Φ 0 + △ Φ \Phi_0 + △\Phi Φ0+△Φ:
m a x Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ l o g ( P Φ ( y t ∣ x , y < t ) ) \underset{\Phi}{max}\sum_{(x,y)∈Z}\sum^{|y|}_{t=1}log(P_{\Phi}(y_t|x,y_{<t})) Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))
全量微调的一个短板就是,下游任务不同就要学习不同的参数 △ Φ △\Phi △Φ,它的维度 ∣ △ Φ ∣ |△\Phi| ∣△Φ∣和 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣相同。而预训练模型的参数是很大的,这样就对存储和部署要求很高。
本文采用了一个更有效的方法, △ Φ = △ Φ ( Θ ) △\Phi = △\Phi(\Theta) △Φ=△Φ(Θ)是通过一个远小于 ∣ △ Φ Θ ∣ |△\Phi_{\Theta}| ∣△ΦΘ∣的小尺寸参数 Θ \Theta Θ编码得到。找到 △ Φ △\Phi △Φ变为了在 Θ \Theta Θ上优化:
m a x Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ l o g ( P Φ ( y t ∣ x , y < t ) ) \underset{\Theta}{max}\sum_{(x,y)∈Z}\sum^{|y|}_{t=1}log(P_{\Phi}(y_t|x,y<t)) Θmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))
本文提出了一种低秩表示来编码 △ Φ △\Phi △Φ。对于GPT-3 175B, ∣ Θ ∣ |\Theta| ∣Θ∣的训练参数量是 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣的0.01%。
之前方法的缺点
- 适配器层引入了推理延迟
- 直接优化Prompt很难
比如prefix tuning
本文方法
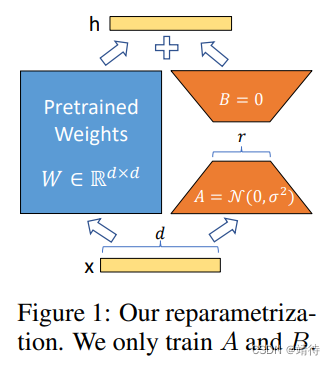
低秩参数更新矩阵
假定 W 0 ∈ R d × k W_0∈\mathbb{R}^{d×k} W0∈Rd×k。
W 0 + △ W = W 0 + B A W_0 + △W = W_0 + BA W0+△W=W0+BA,其中 B ∈ R d × r B∈\mathbb{R}^{d×r} B∈Rd×r, A ∈ R r × k A∈\mathbb{R}^{r×k} A∈Rr×k,这个r的秩远小于min(d, k)。
训练时,冻住 W 0 W_0 W0,不接收梯度更新,同时A和B包含可训练参数。
设 h = W 0 x h = W_0x h=W0x:
h = W 0 x + △ W x = W 0 x + B A x h = W_0x+△Wx = W_0x + BAx h=W0x+△Wx=W0x+BAx
当遇到不用的下游任务时,只需要替换BA就行,所以没有推理延迟。
将LoRA应用到Transformer
在Transformer架构中,在自注意力模块有四个权重矩阵( W q W_q Wq、 W k W_k Wk、 W v W_v Wv、 W o W_o Wo),在MLP模块有两个。本文将Transformer架构中的 W q W_q Wq(或者 W k W_k Wk, W v W_v Wv)设为一个 d m o d e l × d m o d e l d_{model}×d_{model} dmodel×dmodel的单矩阵。对于下游任务,只改变注意力权重,冻结MLP模块的。
Llama 2: Open Foundation and Fine-Tuned Chat Models
2023年7月 77页
GenAI, Meta
PDF
CODE
引言
本文发布了两个模型:
- LLAMA 2,它是LLAMA 1的升级版本,训练语料新增40%,模型上下文长度翻倍,采用了分组查询注意力。发布了7B, 13B, 70B,34B也训了但没发布
- LLAMA 2-CHAT,它是LLAMA 2用于用户对话的微调版本。发布了7B,13B,70B参数模型
提供了用户手册和代码样例
预训练
预训练数据:2 trillion
训练,与LLAMA 1相同之处:
- 标准transformer
- RMSNorm预归一化
- SwiGLU激活函数
- 旋转位置embedding RoPE
不同之处: - 增加上下文长度
- 分组查询注意力(GQA)
优化器:AdamW
分词器:与LLAMA 1相同,此表规模32k tokens
它甚至还写了LLAMA 2的碳排放情况…
评价指标方面,LLAMA 2 70B在MMLU和GSM8K上与GPT-3.5相近,但是在代码基线上有差距,在几乎所有的基线上都比PaLM(540B)强。与GPT-4和PaLM-2-L相比,还有很大差距。
微调
SFT监督微调
使用了公开的微调数据,自己标了一些,有27540这么多就不标了,因为数量少质量高效果也能好。
对于微调过程,每一个样本包含一个提示prompt和一个答案。为了确保模型序列长度都被填充,训练集里将全部的prompt和答案相连。用了特殊token划分prompt和答案片段。使用了一种自回归目标函数,并将来自用户prompt的token计算loss归零,所以只在答案token上反向传播。模型微调轮数为2。
RLHF 人类反馈的增强学习
RLHF是一种将微调模型行为与人类偏好和指令对齐的一种模型训练过程。首先让标注员写一个提示(prompt),然后对两个样本模型的回答根据制定的标准选择更好的一个,这种数据用于训练奖励模型(reward model)。为了多样性最大化,两个模型参数和超参数不同。为了让参与者强制选择,每个回答会打标程度(很好,好,一般,不确定)。合适的标注从两个方面考虑,有用性和安全性。在其它答案是安全的情况下,不会选择不安全的回答为最佳,因为本文认为安全回答也是更好的。
收集了更多的偏好数据后,奖励模型进步了,LLAMA 2-CHAT就会训练地更好,而它更好又会改变模型数据分布。如果不用最新的样本分布,奖励模型的精确度就会很快降低。所以在微调新一轮LLAMA 2-CHAT前使用当前最新的LLAMA 2-CHAT收集数据很重要。这一步让奖励模型保持正确的分布,也能保持最新模型的准确奖励值。
本文收集了超过一百万(1 million)人工标注数据,称做Meta奖励模型数据。不同领域提示和回答的数量不同,总结和在线公式数据一般有较长的提示,然而对话型提示通常较短。平均来看,本文的数据比开源数据集有更多轮的对话,并且更长。
奖励模型将模型回复和对应的提示(包括之前的多轮上下文)作为输入,输出一个标量分数来衡量模型生成质量。将这些分数作为奖励,通过RLHF优化LLAMA 2-CHAT获得更好的效果,提升有用性和安全性。
有用性和安全性往往需要折中,所以本文训练了两个分开的奖励模型,一个用来优化可用性(Helpfulness RM),一个用来优化安全性(Safety RM)。
本文使用预训练对话模型checkpoint来初始化奖励模型,这样可以确保所有的模型从预训练中得到知识。除了将下一个token预测分类头替换为一个标量奖励值的回归头输出以外,模型架构和超参数和预训练模型一致。
为了训练奖励模型,将人工标注数据转为二分类排序标签格式(比如选择&拒绝),让选择的回复有更高的分数。loss是二分类排序损失函数: L r a n k i n g = − l o g ( σ ( r θ ( x , y c ) − r θ ( x , y r ) ) ) L_{ranking}=-log(\sigma(r_\theta(x, y_c)-r_\theta(x,y_r))) Lranking=−log(σ(rθ(x,yc)−rθ(x,yr)))
其中, r θ ( x , y ) r_\theta(x, y) rθ(x,y)是对于提示x和回答y的标量分数输出表示, θ \theta θ是模型权重。 y c y_c yc是标注员选择的回答, y r y_r yr是被拒绝的回答。
输出是有四个分数的标量(比如很好),为了加大各分数差距,更好的区别有用性和安全性,将损失函数改为:
L r a n k i n g = − l o g ( σ ( r θ ( x , y c ) − r θ ( x , y r ) − m ( r ) ) ) L_{ranking}=-log(\sigma(r_\theta(x, y_c)-r_\theta(x,y_r) - m(r))) Lranking=−log(σ(rθ(x,yc)−rθ(x,yr)−m(r)))
其中, m ( r ) m(r) m(r)是评分的离散函数,两个回答越不同,这个边距越大,两个回答越相似,这个边距越近。这个边距可以提升有用性。
训练细节:训了一轮,本文发现训久了过拟合。
本文采用了两种主要的RLHF微调算法:
- PPO(Proximal Policy Optimization)算法
- 拒绝采用微调(Rejection Sampling fine-tuning),只在70B上用了
在K个模型输出中使用奖励模型选择最好的,将选择出来的做梯度更新。对于每个提示,包含最好奖励分数的样本作为新的标准。然后在新的样本中微调,加强奖励。
两个算法主要在广度和深度上有区别。
多轮对话一致性的系统信息
有些指令应该贯穿对话始终,比如“扮演xx”指令,但是原始的RLHF模型在几轮后会忘记初始指令。为此,提出Ghost注意力(GAtt)。
LLaMA: Open and Efficient Foundation Language Models
概述
不像Chinchilla、PaLM或者GPT-3,只使用公开可用的数据训练。
训练不是最快的,但是推理是最快的。
本文目标是打造一系列用更多token训练的最佳推理性能的大模型。LLaMA:6.7B、13.0B、32.5B、65.2B
LLaMA-13B超过GPT3。
LLaMA-65B与Chinchilla或PaLM-540B相当。
方法
预训练数据
- English CommonCrawl(67%):使用fastText去掉非英语文本、使用一个n-gram语言模型去掉低质量内容、用一个线性模型对维基百科中用作参考文献的页面与随机抽样的页面以及未归类为参考文献的废弃页面进行分类
- C4(15%):与CCNet的主要区别是质量过滤,它主要依赖于启发式,如标点符号的存在或网页中的单词和句子的数量
- Github(4.5%):基于行长度或字母数字字符比例的启发式法过滤低质量文件
- Wikipedia(4.5%)
- Gutenberg and Book3(4.5%):去掉了有90%重复的书籍
- ArXiv(2.5%):删除了第一部分之前的所有内容、参考书目、.tex文件中的评论、用户编写的内联扩展定义和宏
- Stack Exchange(2%):问答数据,删除了文本中的HTML标签,并根据分数对答案进行了排序(由高到低)
分词:BPE算法
整个训练集经分词后有1.4T个token(33B和65B)
架构
transformer架构基础上魔改。
魔改点(中括号内为灵感来源):
- 预归一化[GPT3]:使用RMSNorm
- SwiGLU激活函数[PaLM]
- 旋转embedding[GPTNeo]:将绝对位置编码换成了旋转位置嵌入RoPE
优化器:AdamW
训练速度优化:
- 随机多头注意力机制,不保存注意力权重,不计算key/query分数(masked)
- 减少了反向传播中重复计算的激活单元的数量,只保存最耗费计算的单元,比如线性层的输出;没有使用PyTorch autograd;使用了模型和序列并行化减少模型内存占用;尽量将激活单元的计算和GPU之间的网络通信通用
训练时间:
65B参数模型:2048张A100 GPU,80GB内存,380 tokens/sec/GPU,1.4T tokens训练了21天
它甚至还写了LLAMA的碳排放情况…
更多【论文阅读-大模型相关论文笔记】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-【机器学习】Kmeans聚类算法 - 其他
- 集成学习-【Python机器学习】零基础掌握RandomForestRegressor集成学习 - 其他
- java-LeetCode //C - 373. Find K Pairs with Smallest Sums - 其他
- 集成学习-【Python机器学习】零基础掌握StackingClassifier集成学习 - 其他
- 编程技术-如何提高企业竞争力?CRM管理系统告诉你 - 其他
- java-Java - Hutool 获取 HttpRequest:Header、Body、ParamMap 等利器 - 其他
- c++-C++特殊类与单例模式 - 其他
- 编辑器-vscode git提交 - 其他
- 前端-WebGL的技术难点分析 - 其他
- c++-【c++之设计模式】组合使用:抽象工厂模式与单例模式 - 其他
- python-【JavaSE】基础笔记 - 类和对象(下) - 其他
- github-Redis主从复制基础概念 - 其他
- 运维-【iOS免越狱】利用IOS自动化WebDriverAgent实现自动直播间自动输入 - 其他
- 前端-AJAX-解决回调函数地狱问题 - 其他
- html5-HTML5的语义元素 - 其他
- html5-1.2 HTML5 - 其他
- hive-项目实战:抽取中央控制器 DispatcherServlet - 其他
- kafka-Kafka(消息队列)--简介 - 其他
- github-github 上传代码报错 fatal: Authentication failed for ‘xxxxxx‘ - 其他
- matlab-【MATLAB源码-第69期】基于matlab的LDPC码,turbo码,卷积码误码率对比,码率均为1/3,BPSK调制。 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
