Android安全-记一次对vm保护的算法的快速定位
推荐 原创在找sgmain相关资料时看到了这个贴子:
https://bbs.pediy.com/thread-267741.htm
之后对大佬使用的trace工具很感兴趣,对反编译引擎也很感兴趣,不过底蕴不够,反编译引擎之类的也就将就用第三方,只能常试用frida的Stalker改了个类似的trace工具试了下效果也就有了这篇文章
用到的工具:ida/Ghidra/frida
看的是手淘6.5.82版本的sgmain,因为本身只是对trace工具的一次验证,所以不包含实际的算法分析过程,只谈测试过程中的感受
快速定位主要依赖的是Stalker,ida和Ghidra主要是用于静态分析
在静态分析上,我这种小菜鸡就不讨论两个反编译引擎的本质哪个优劣,就谈使用的感受。
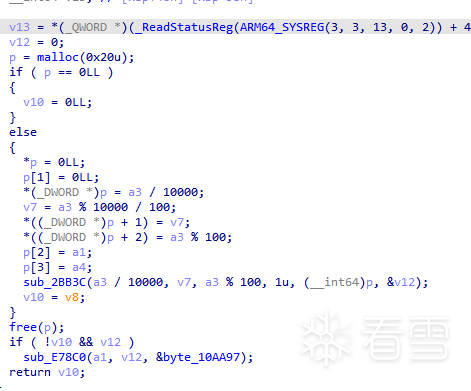
先上对比,对于sgmain的doCommand方法
ida的效果:
ghidra的效果:
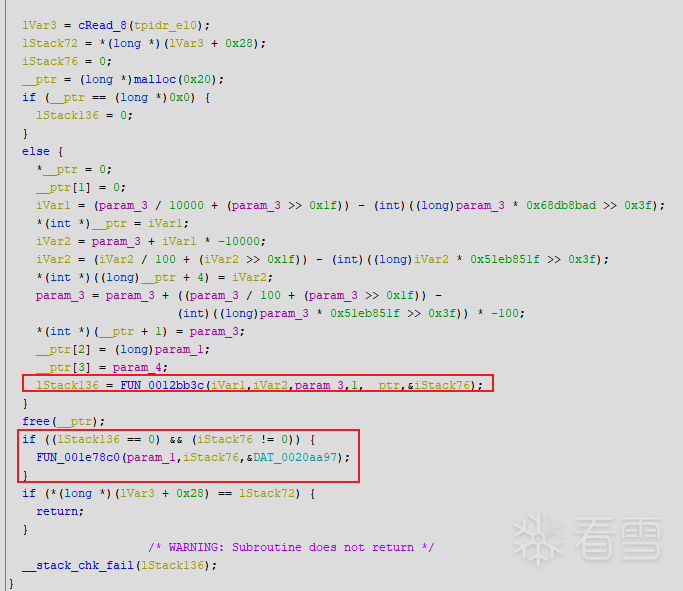
源码大概是这样子的:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
__int64 __fastcall sub_2DB50(JNIEnv
*
param_1,_int64 param_2,
int
param_3,
long
param_4){
unsigned
int
v12
=
0
;
long
ret
=
0
;
long
*
ptr
=
(
long
*
)malloc(
0x20
);
if
(ptr !
=
nullptr){
ptr[
0
]
=
0LL
;
ptr[
1
]
=
0LL
;
*
(_DWORD
*
)ptr
=
param_3
/
10000
;
v7
=
param_3
%
10000
/
100
;
*
((_DWORD
*
)ptr
+
1
)
=
v7;
*
((_DWORD
*
)ptr
+
2
)
=
param_3
%
100
;
ptr[
2
]
=
param_1;
ptr[
3
]
=
param_4;
ret
=
sub_2BB3C(param_3
/
10000
, v7, param_3
%
100
,
1u
, ptr, &v12);
}
free(ptr);
if
(ret
=
=
0
&& v12 !
=
0
){
/
/
throw Exception
sub_E78C0(param_1, v12,
0x20aa97
)
}
return
ret;
}
|
可以很明显看出ida对除法的优化更好一些,ghidra在除法这块就没有ida好,但是我个人更喜欢Ghidra的效果
这里说句题外话,关于除法,编译器对一个整数进行除法运算时往往会转换成乘一个魔数然后除2的多少次方这种,这个推导过程很复杂,本质上就是把除任意整数变成除2的N次方的数,但过程中存在很多边界问题导致比较复杂,不过如果当ida之类的返编译器在复杂需要手动推导时,网上有种方法可以算出大概的值,不过涉及到符号问题及取模问题,记得好像是有Sub类指令参与的可能就是取模,但没有细究,有兴趣的可以自己编译后对比看看。
一般像这种同时存在
乘法、位移0x3F/0x1f取符号位、ASR之类指令时,基本八九不离十就可能是除法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
LOAD:
000000000002DBFC
A9
75
91
52
+
MOV W9,
#0x68DB8BAD
LOAD:
000000000002DBFC
69
1B
AD
72
LOAD:
000000000002DC04
A9
7E
29
9B
SMULL X9, W21, W9
LOAD:
000000000002DC08
1F
7D
00
A9 STP XZR, XZR, [X8]
LOAD:
000000000002DC0C
E8
1B
40
F9 LDR X8, [SP,
#0x80+p]
LOAD:
000000000002DC10
2C
FD
7F
D3 LSR X12, X9,
#0x3F ; '?'
LOAD:
000000000002DC14
29
FD
6C
93
ASR X9, X9,
#0x2C ; ','
LOAD:
000000000002DC18
20
01
0C
0B
ADD W0, W9, W12
LOAD:
000000000002DC1C
0A
E2
84
52
MOV W10,
#0x2710
LOAD:
000000000002DC20
EB A3
90
52
MOV W11,
#0x851F
LOAD:
000000000002DC24
00
01
00
B9
STR
W0, [X8]
LOAD:
000000000002DC28
6B
3D
AA
72
MOVK W11,
#0x51EB,LSL#16
LOAD:
000000000002DC2C
0A
D4
0A
1B
MSUB W10, W0, W10, W21
LOAD:
000000000002DC30
E8
1B
40
F9 LDR X8, [SP,
#0x80+p]
LOAD:
000000000002DC34
4A
7D
2B
9B
SMULL X10, W10, W11
LOAD:
000000000002DC38
A9
7E
2B
9B
SMULL X9, W21, W11
LOAD:
000000000002DC3C
4B
FD
7F
D3 LSR X11, X10,
#0x3F ; '?'
LOAD:
000000000002DC40
4A
FD
65
93
ASR X10, X10,
#0x25 ; '%'
LOAD:
000000000002DC44
41
01
0B
0B
ADD W1, W10, W11
LOAD:
000000000002DC48
01
05
00
B9
STR
W1, [X8,
#4]
LOAD:
000000000002DC4C
2A
FD
7F
D3 LSR X10, X9,
#0x3F ; '?'
LOAD:
000000000002DC50
28
FD
65
93
ASR X8, X9,
#0x25 ; '%'
LOAD:
000000000002DC54
E9
1B
40
F9 LDR X9, [SP,
#0x80+p]
LOAD:
000000000002DC58
08
01
0A
0B
ADD W8, W8, W10
LOAD:
000000000002DC5C
8A
0C
80
52
MOV W10,
#0x64 ; 'd'
LOAD:
000000000002DC60
02
D5
0A
1B
MSUB W2, W8, W10, W21
LOAD:
000000000002DC64
22
09
00
B9
STR
W2, [X9,
#8]
|
如上面的这种代码,就可以尝试用(1 << XX) / (magicNum - 1)这种方式来算出大概的除数,比如就上面的指令来说:
|
1
2
3
4
|
>>> (
1
<<
0x2c
)
/
(
0x68db8bad
-
1
)
10000.000002510205
>>> (
1
<<
0x25
)
/
(
0x51eb85ef
-
1
)
99.99998491839733
|
而且在patch后的及时效果上面感觉更好一些,特别是那些br reg,adrp ret之类的跳转识别效果会比ida好,用ida的时候那个JMPOUT很尴尬,即使你使用跳转patch了也不一定能有效f5,可能还得去除中间的一些混淆的乱码才可以
其次Ghidra也存在一个比较尴尬的问题,就像上面这个代码里面框起来的代码,那个0x2bb3c这个函数(ghidra会自动添加基址,默认是0x100000),在初次打开时,这个函数被识别为了空函数,而且无反回,这也就直接导致下面的那个0xe78c0所在的代码块被直接隐藏了,因为lStack76 != 0被直接视为了不可达分支,修改函数定义后代码也就立刻重新生成了上面的这个效果,修改是及时生效的,效果不错。
现在的一些间接跳转的混淆,不管他怎么变形,实际上很多时候都是常量表达式,而对于常量表达式的这种间接跳有很多种方式处理
比如0x2bb3c头部的这段代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
LOAD:
000000000002BB3C
SUB SP, SP,
#0x1B0
LOAD:
000000000002BB40
STP X28, X27, [SP,
#0x1A0+var_50]
LOAD:
000000000002BB44
STP X26, X25, [SP,
#0x1A0+var_40]
LOAD:
000000000002BB48
STP X24, X23, [SP,
#0x1A0+var_30]
LOAD:
000000000002BB4C
STP X22, X21, [SP,
#0x1A0+var_20]
LOAD:
000000000002BB50
STP X20, X19, [SP,
#0x1A0+var_10]
LOAD:
000000000002BB54
STP X29, X30, [SP,
#0x1A0+var_s0]
LOAD:
000000000002BB58
ADD X29, SP,
#0x1A0
LOAD:
000000000002BB5C
MRS X26,
#3, c13, c0, #2
LOAD:
000000000002BB60
MOV W23, W1
LOAD:
000000000002BB64
MOV W24, W0
LOAD:
000000000002BB68
MOV W10,
#0x2710
LOAD:
000000000002BB6C
MOV W12,
#0x64 ; 'd'
LOAD:
000000000002BB70
LDR X14, [X26,
#0x28]
LOAD:
000000000002BB74
MUL W15, W24, W10
LOAD:
000000000002BB78
MUL W12, W23, W12
LOAD:
000000000002BB7C
MOV W22, W2
LOAD:
000000000002BB80
MOV W13,
#0xC600
LOAD:
000000000002BB84
ADD W10, W15, W12
LOAD:
000000000002BB88
MOV W8,
#0x96
LOAD:
000000000002BB8C
SUB X9, X29,
#-var_70
LOAD:
000000000002BB90
MOVK W13,
#0x53E,LSL#16
LOAD:
000000000002BB94
ADD W10, W10, W22
LOAD:
000000000002BB98
MOV X21, X4
LOAD:
000000000002BB9C
ADD W13, W10, W13
LOAD:
000000000002BBA0
STUR X14, [X29,
#var_58]
LOAD:
000000000002BBA4
STUR W8, [X29,
#var_70]
LOAD:
000000000002BBA8
ADR X27, loc_2BBAC
LOAD:
000000000002BBAC
LOAD:
000000000002BBAC
loc_2BBAC ; DATA XREF: sub_2BB3C
+
6C
↑o
LOAD:
000000000002BBAC
LDRSW X4,
=
0xFFFFFE62
LOAD:
000000000002BBB0
MOV X20,
#0xAB
LOAD:
000000000002BBB4
EOR X4, X4, X20
LOAD:
000000000002BBB8
ADD X4, X4,
#0x88
LOAD:
000000000002BBBC
MVN X4, X4
LOAD:
000000000002BBC0
LDRSW X10, [X9]
LOAD:
000000000002BBC4
EOR X4, X4, X10
LOAD:
000000000002BBC8
ADD X27, X27, X4
LOAD:
000000000002BBCC
MOV X8,
#0x62 ; 'b'
LOAD:
000000000002BBD0
BR X27
|
代码看起来有点复杂,各种运算,还有间接地址访问,而且每个函数头部都有这种间接跳,且貌似每个表达式都不一样,但实际上这种处理起来也相当简单,分静态和动态两种情况。
动态的情况不用说,单步或trace来获取对应的跳转地址即可,对于Ghidra,也不需要特别处理,它会自动帮你把这些常量表达式计算出来,在进行反编译时会自动使用它计算出的结果进行代入。
比如下面的是Ghidra的汇编显示:
|
1
2
3
4
5
6
|
LAB_0013dd1c XREF[
1
]:
0013dd00
(j)
0013dd1c
e8
03
00
90
adrp x8,
0x1b9000
0013dd20
08
01
11
91
add x8,x8,
#0x440
0013dd24
08
09
40
f9 ldr x8,[x8,
#0x10]=>DAT_001b9450 = 000000000013DC94h
0013dd28
08
71
02
91
add x8,x8,
#0x9c
0013dd2c
00
01
1f
d6 br x8
=
>LAB_0013dd30
|
而如果你要说就用ida,不开启动态调试的情况下也简单,用ida的脚本使用unicorn进行模拟执行一下结果就跑出来了:
对于那种代码之间被各种跳转包围的间接跳,例如:
ida中那种函数中间的间接跳
|
1
2
3
4
5
6
7
8
9
10
11
|
LOAD:
000000000002BD58
loc_2BD58 ; DATA XREF: sub_2BB3C
+
3B0
↓o
LOAD:
000000000002BD58
; LOAD:off_16FC38↓o
LOAD:
000000000002BD58
E9
23
0A
A9 STP X9, X8, [SP,
#0x1A0+var_100]
LOAD:
000000000002BD5C
88
36
40
F9 LDR X8, [X20,
#(off_16FC28 - 0x16FBC0)] ; loc_2BD68
LOAD:
000000000002BD60
FF
0F
00
F9
STR
XZR, [SP,
#0x1A0+var_188]
LOAD:
000000000002BD64
08
2D
00
91
ADD X8, X8,
#0xB
LOAD:
000000000002BD68
LOAD:
000000000002BD68
loc_2BD68 ; DATA XREF: sub_2BB3C
+
220
↑o
LOAD:
000000000002BD68
; LOAD:off_16FC28↓o
LOAD:
000000000002BD68
03
00
00
14
B loc_2BD74 ; loc_2BD74 ; Keypatch modified this
from
:
LOAD:
000000000002BD68
; BR X8
|
ghidra函数中部的间接跳:
|
1
2
3
4
5
6
|
LAB_0013dd1c XREF[
1
]:
0013dd00
(j)
0013dd1c
e8
03
00
90
adrp x8,
0x1b9000
0013dd20
08
01
11
91
add x8,x8,
#0x440
0013dd24
08
09
40
f9 ldr x8,[x8,
#0x10]=>DAT_001b9450 = 000000000013DC94h
0013dd28
08
71
02
91
add x8,x8,
#0x9c
0013dd2c
00
01
1f
d6 br x8
=
>LAB_0013dd30
|
处理方式其实差不多,不管是ida还是Ghidra它们即便是能算出来跳转地址,也会给你提示,比如上面的ida就提示地址是loc_2BD68,但是他们为了确宝流程尽可能准确,所以一般不会在返汇编窗口中进行常量化,这时候就需要进行手动patch。
如果是硬是要ida配合Unicorn,这时候也不是不可以,但是因为部分常量在其它代码块中,再加上里面经常混杂一些地址中常量的访问,在通用性上面可能会不太好,所以这种时候一般建议是用trace的数据,或依赖现有工具返汇编引擎的结果来参考进行Patch。
比如,在Ghidra中与上面的类似的代码块在反汇编引擎中一般会给你提示出来:
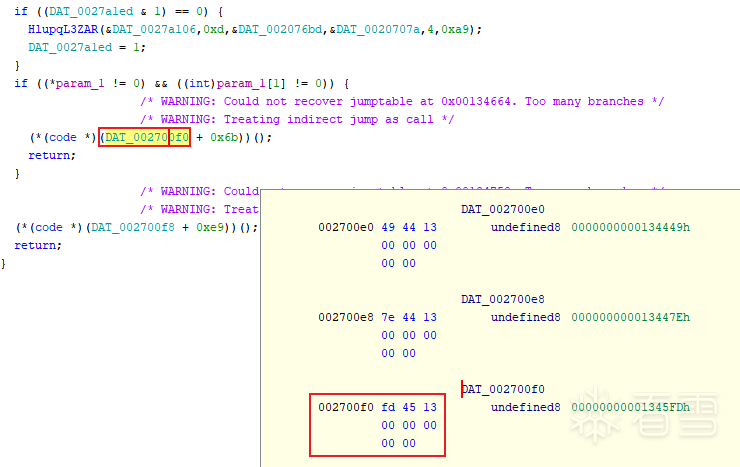
在汇编页面就是如下的这种:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
LAB_00134638 XREF[
1
]:
00134604
(j)
00134638
69
22
40
a9 ldp x9,x8,[x19]
0013463c
a8
03
18
f8 stur x8,[x29,
#local_90]
00134640
08
7d
40
92
and
x8,x8,
#0xffffffff
00134644
a9 a7
38
a9 stp x9,x9,[x29,
#local_88]
00134648
a8 c3
17
b8 stur w8,[x29,
#local_94]
0013464c
e9
07
00
b4 cbz x9,LAB_00134748
00134650
c8
07
00
34
cbz w8,LAB_00134748
00134654
f6
09
00
90
adrp x22,
0x270000
00134658
d6
82
01
91
add x22,x22,
#0x60
0013465c
c8
4a
40
f9 ldr x8,[x22,
#0x90]=>DAT_002700f0 = 00000000001345FDh
00134660
08
ad
01
91
add x8,x8,
#0x6b
00134664
00
01
1f
d6 br x8
=
>LAB_00134668
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
|
typedef struct _StData{
void
*
*
ppParamSt;
int
sz;
}StData;
typedef struct _StParam1{
int
param;
int
unknow;
StData
*
pSD;
}StParam1;
typedef struct _StParam2{
int
unknow;
int
param;
long
flag;
StData
*
pSD;
}StParam2;
typedef struct _StParam3{
long
unknow;
int
param;
int
unknow;
long
encryFuncAddr;
}StParam3;
long
FUN_0012bb3c(
int
param_1,
int
param_2,
int
param_3,
int
param_4,
long
*
param_5,
int
*
param_6)
{
int
iVar1;
long
lVar2;
StParam3
*
pSVar3;
long
local_1a8;
StParam1
*
pSStack416;
long
lStack408;
StParam2
*
pSStack400;
long
lStack392;
int
local_17c;
long
local_178;
int
local_7c;
long
*
plStack120;
int
*
piStack112;
long
local_68;
StData
*
*
pplVar1;
local_7c
=
1
;
plStack120
=
param_5;
piStack112
=
param_6;
local_178
=
FUN_00168480(param_1
*
10000
+
param_2
*
100
+
param_3
+
88000000
,
param_4,
0
, &plStack120, &local_7c);
if
(local_7c !
=
0
) {
pplVar1
=
(
long
*
*
)
0x279af0
;
/
/
全局变量非常量
if
(param_4 !
=
0
) {
pplVar1
=
(
long
*
*
)&DAT_00279ae8;
/
/
全局变量非常量
}
iVar1
=
(
*
pplVar1)
-
>sz;
if
(iVar1 <
1
){
local_17c
=
0x26b0
;
}
else
{
for
(local_1a8
=
0
; local_1a8 < iVar1; local_1a8
+
+
){
pSStack416
=
(StParam1
*
)(
*
pplVar1)
-
>ppParamSt[local_1a8];
if
(pSStack416
-
>param
=
=
param_1){
goto LAB_JMP1;
}
}
pSStack416
=
0
;
LAB_JMP1:
if
(pSStack416
=
=
0
){
local_17c
=
0x26b0
;
}
else
{
iVar1
=
pSStack416
-
>pSD
-
>sz;
if
(iVar1 <
1
){
local_17c
=
0x26b1
;
}
else
{
for
(lStack408
=
0
; lStack408 < iVar1; lStack408
+
+
){
pSStack400
=
(StParam2
*
)pSStack416
-
>pSD
-
>ppParamSt[lStack408];
if
(pSStack400
-
>param
=
=
param_2){
goto LAB_JMP2;
}
}
pSStack400
=
0
;
LAB_JMP2:
if
(pSStack400
=
=
0
){
local_17c
=
0x26b1
;
}
else
{
iVar1
=
pSStack400
-
>pSD
-
>sz;
if
(iVar1 >
0
){
for
(lStack392
=
0
; lStack392 < iVar1; lStack392
+
+
){
pSVar3
=
(StParam3
*
)pSStack400
-
>pSD
-
>ppParamSt[lStack392];
if
(pSVar3 !
=
0
&& pSVar3
-
>param
=
=
param_3){
local_178
=
(
*
(func
*
)(pSStack400
-
>flag ^ pSVar3
-
>encryFuncAddr))(param_5, param_6);
return
local_178;
}
}
}
local_17c
=
0x26b2
;
}
}
}
}
if
(param_6 !
=
(
int
*
)
0x0
) {
*
param_6
=
local_17c
+
(param_2
*
100
+
param_1
*
10000
+
param_3)
*
10000
;
}
local_178
=
0
;
}
return
local_178;
}
|
常见的混淆基本都是差不多的处理方式,再复杂的基本也离不开Trace了。
Stalker与ida的trace各有优缺点吧,ida的trace是依托于调试器的,所以调试器有的缺点他都有,一般配合DBG_Hooks脚本处理效果更好,我一般喜欢在定位范围缩小到一定程度后才会用它,再则是用它来追踪程序的退出流程返向推检测的代码,不过这里主要说Stalker使用的问题就不聊它了。
Stalker很早之前就存在了,不过貌似这个东西在arm64之后才用的比较多一些,在arm32里面需要处理跳转地址的问题,而我实际使用过程中发现,如果开启了call事件,基本必崩,所以所有事件都是false的情况下做的处理,简而言之就是只用了transform回调。
在使用过程中发现几点问题:
1.Stalker的模式给我的感觉是将每一个以b/ret之类的流程跳转指令作为块的分离点来处理的,transform入口处iterator.next()返回的是块的地址,所以在这里直接使用某一地址来判断是否为Trace跟踪的代码区间可能会存在问题,比如,我在尝试任意指令hook时不遍历整个iterator块而用addr.compare == 0作为判断就会永远无法到达,因为transform每次来时iterator.next()返回的只会是代码块的首地址
2.由于前面的原因,所以iterator.putCallout中的指令是没有b/ret之类跳转指令的,在arm32里面常见的adrp pc, #imm这类指令在这里没有看到,所以暂时不清楚这种情况会不会有其它变化。
3.instruction的regsRead和regsWritern里面是空的,碰到跳转或条件指令里里面会有值,但不包含常规寄存器,猜测可能是在性能优化上的有意为之,不过问题不大,无非就是在处理ldr x0,[x0]这类指令时打印寄存器值时需要注意一些。
除了这些外貌似也没什么太大的问题,整体执行速度还不错,就是代码量大时偶尔会挂掉,特别是在跟踪步入bl指令时。
然后依拖于Stalker封装了几个函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
/
/
跟踪函数
/
/
param0:跟踪的模块
/
/
param1:激活trace的hook点,主要是做条件判定,符合条件的才trace
/
/
param2
-
param3:跟踪的代码块区间,主要用来控制trace的指令区间
/
/
param4:是否步入(超出模块的不跟),默认
False
,开
True
容易触发time校验导至挂掉
/
/
trace_entry(
"libsgmainso-6.5.82.so"
, base.add(
0x2db50
),
0x2bb3c
,
0x2befc
)
/
/
同上,跟踪所有bl指令,并打印参数信息,快束定位这个挺好使,这里测试是字符串,其它的可以做适当调整
/
/
trace_entry_bl(
"libsgmainso-6.5.82.so"
, base.add(
0x2db50
),
0x2db50
,
0x2DCF0
, true)
/
/
跟踪所有逻辑指令,比如lsl
/
lsr等,打印偏移
/
VA及详细指令信息,实际使用效果不好,干扰太多
/
/
trace_entry_logic(
"libsgmainso-6.5.82.so"
, base.add(
0x2db50
),
0x2db50
,
0x2DCF0
, true)
/
/
同上
/
/
param4:为在指定地址的指令执行时调用回调
/
/
param5:回调函数
/
/
函数功能主要是处理在特殊地址执行时相关数据的打印
/
/
trace_callback(
"libsgmainso-6.5.82.so"
,
0x2db50
,
0x2bb3c
,
0x2befc
,
0x2bc84
, function(context) {
/
/
var insn
=
Instruction.parse(context.pc)
/
/
var insnStr
=
insn.toString().padEnd(
25
,
" "
)
/
/
var strLog
=
insn.address.sub(g_baseAddr)
+
" "
+
insn.address
+
":\t"
+
insnStr
+
"\t"
+
" "
+
getOpInfo(context, insn)
/
/
console.log(strLog)
/
/
/
/
})
|
因为是随手测试的,所以没有专门去看sign的计算是哪一个,就随手测试了几个值,不需要的屏蔽掉了,也就有了下面的这个结果:
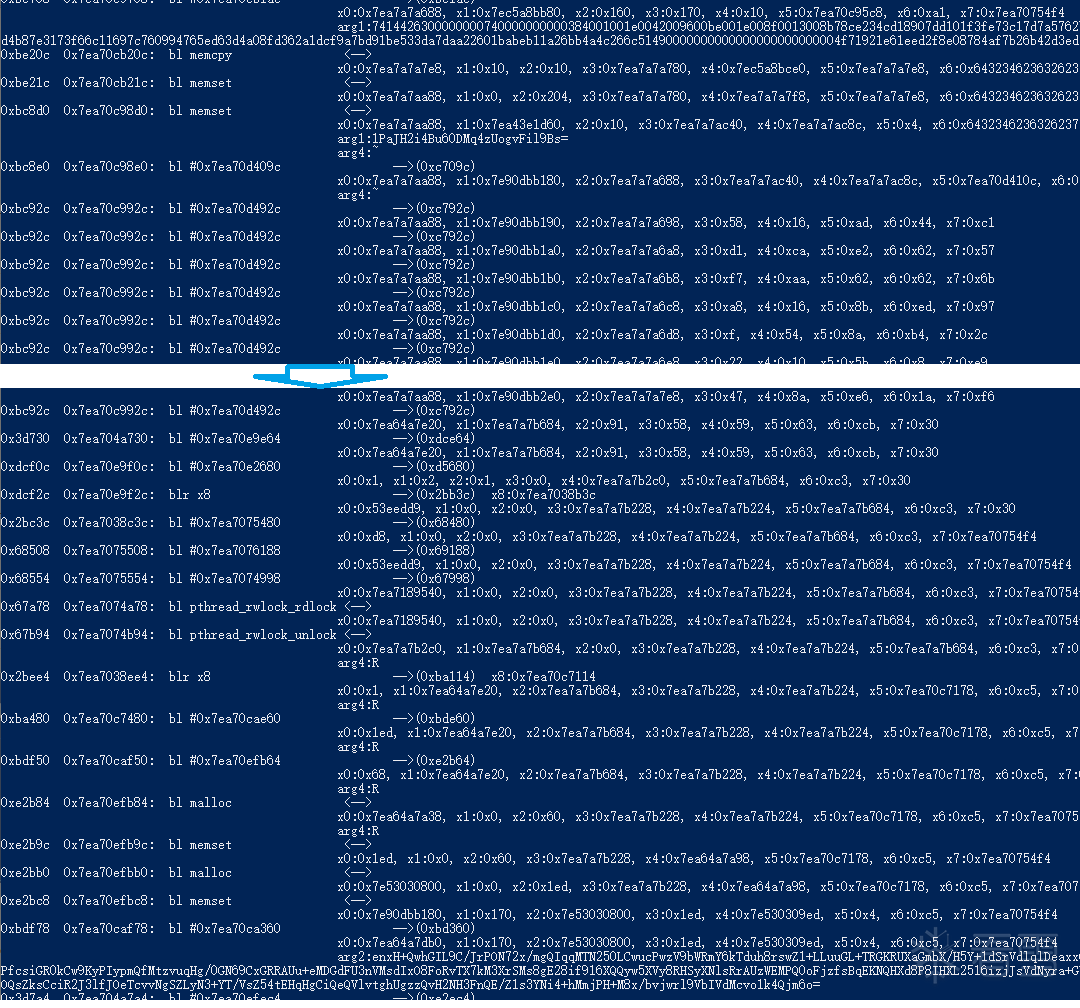
sign计算的中间call都应该算是比较清析吧
中间的流程大概就是在0xbc708处bl 0xbe1ac,之后就是0xbc8e0处调用0xc709c,参数是1PaJH2i4Bu60DMq4zUogvFil9Bs=字符串,之后一连串的bl 0xc792c,之后会使用新的函数调用bl 0x2bb3c进行执行,之后还有
|
1
2
3
4
5
|
x0:
0x7ec5a203e0
, x1:
0x1ec
, x2:
0x1ec
, x3:
0x0
, x4:
0x0
, x5:
0x0
, x6:
0x0
, x7:
0x7ea70754f4
0xe73ac
0x7ea70f43ac
: blr x8
-
-
>(libart.so!
0x32d3a4
_ZN3art3JNI12NewByteArrayEP7_JNIEnvi) x8:
0x7ecf7133a4
x0:
0x7ec5a203e0
, x1:
0x49
, x2:
0x0
, x3:
0x1ec
, x4:
0x7e53030800
, x5:
0x7ea7a7b348
, x6:
0x0
, x7:
0x7ea70754f4
arg4:enxH
+
QwhGIL9C
/
JrXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXjm6o
=
0xe7414
0x7ea70f4414
: blr x8
-
-
>(libart.so!
0x32d424
_ZN3art3JNI18SetByteArrayRegionEP7_JNIEnvP11_jbyteArrayiiPKa) x8:
0x7ecf713424
|
流程貌似还算比较清晰
然后在ghidra里面看了一下,不忍直视,来点片段享受一下吧
0xbc560
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
do {
uVar11
=
puVar6[
1
];
uVar10
=
*
puVar6;
local_880
=
CONCAT17((byte)((ulong)local_870 >>
0x38
) ^
(byte)((uVar10 &
0xffffff0000000000
) >>
0x38
),
CONCAT16((byte)((ulong)local_870 >>
0x30
) ^
(byte)((uVar10 &
0xffffff0000000000
) >>
0x30
),
CONCAT15((byte)((ulong)local_870 >>
0x28
) ^
(byte)(uVar10 >>
0x28
),
CONCAT14((byte)((ulong)local_870 >>
0x20
) ^
(byte)(uVar10 >>
0x20
),
CONCAT13((byte)((ulong)local_870
>>
0x18
) ^
(byte)(uVar10 >>
0x18
),
CONCAT12((byte)((ulong)
local_870 >>
0x10
) ^ (byte)(uVar10 >>
0x10
),
CONCAT11((byte)((ulong)local_870 >>
8
) ^
(byte)(uVar10 >>
8
),
(byte)local_870 ^ (byte)uVar10)))))));
uStack2168
=
CONCAT17((byte)((ulong)uStack2152 >>
0x38
) ^
(byte)((uVar11 &
0xffffff0000000000
) >>
0x38
),
CONCAT16((byte)((ulong)uStack2152 >>
0x30
) ^
(byte)((uVar11 &
0xffffff0000000000
) >>
0x30
),
CONCAT15((byte)((ulong)uStack2152 >>
0x28
) ^
(byte)(uVar11 >>
0x28
),
CONCAT14((byte)((ulong)uStack2152 >>
0x20
)
^ (byte)(uVar11 >>
0x20
),
CONCAT13((byte)((ulong)uStack2152
>>
0x18
) ^
(byte)(uVar11 >>
0x18
),
CONCAT12((byte)((ulong)
uStack2152 >>
0x10
) ^ (byte)(uVar11 >>
0x10
),
CONCAT11((byte)((ulong)uStack2152 >>
8
) ^
(byte)(uVar11 >>
8
),
(byte)uStack2152 ^ (byte)uVar11)))))));
FUN_001c792c(auStack592,puVar9,&local_880);
uStack2152
=
puVar9[
1
];
local_870
=
*
puVar9;
puVar9
=
puVar9
+
2
;
uVar8
=
uVar8
-
1
;
puVar6
=
puVar6
+
2
;
}
while
(uVar8 !
=
0
);
local_9a8
=
local_9a8 &
0xfffffff0
;
|
0xc709c
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
local_2a0
=
param_1;
puStack664
=
param_2;
do {
uVar19
=
puStack664[
1
];
uVar16
=
*
puStack664;
local_2a8
=
local_2a8
-
4
;
uVar17
=
(undefined)((ulong)uVar16 >>
0x20
);
uVar8
=
(ulong)CONCAT16((char)((ulong)uVar16 >>
0x28
),
(uint6)((uint)(CONCAT12(uVar17,(short)uVar16) &
0xff00ff
) <<
0x18
|
(uint)(byte)((ulong)uVar16 >>
8
) <<
0x10
));
uVar9
=
(ulong)CONCAT16((char)((ulong)uVar19 >>
0x28
),
(uint6)CONCAT11((char)uVar19,(char)((ulong)uVar19 >>
8
)) <<
0x10
);
uVar15
=
CONCAT15((char)((ulong)uVar16 >>
0x30
),
(uint5)CONCAT12((char)(uVar8 >>
0x18
),
CONCAT11((char)(uVar8 >>
0x10
),
(char)((ulong)uVar16 >>
0x10
))) <<
8
);
uVar8
=
(ulong)CONCAT16((char)(uVar8 >>
0x30
),uVar15);
uVar18
=
CONCAT15((char)((ulong)uVar19 >>
0x30
),
(uint5)CONCAT12((char)(uVar9 >>
0x18
),
CONCAT11((char)(uVar9 >>
0x10
),
(char)((ulong)uVar19 >>
0x10
))) <<
8
);
uVar9
=
(ulong)CONCAT16((char)(uVar9 >>
0x30
),uVar18);
local_2a0[
1
]
=
((ulong)CONCAT41((uint)(byte)((ulong)uVar19 >>
0x20
) <<
0x18
,(char)uVar19) &
0xffffffff00
) <<
0x18
|
(ulong)CONCAT16((char)((uVar9 &
0xffffffff00000000
) >>
0x30
),
CONCAT15((char)((uVar9 &
0xffffffff00000000
) >>
0x28
),
CONCAT14((char)((ulong)uVar19 >>
0x38
),
CONCAT13((char)(uVar9 >>
0x18
),
|
0xc792C
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
if
((param_1 !
=
(uint
*
)
0x0
&& param_2 !
=
(undefined
*
)
0x0
) && param_3 !
=
(uint
*
)
0x0
) {
uVar9
=
(param_3[
3
] &
0xff00ff00
) >>
8
| (param_3[
3
] &
0xff00ff
) <<
8
;
uVar9
=
(uVar9 >>
0x10
| uVar9 <<
0x10
) ^ param_1[
3
];
local_d0
=
param_1
+
0x24
;
uVar10
=
(
*
param_3 &
0xff00ff00
) >>
8
| (
*
param_3 &
0xff00ff
) <<
8
;
uVar10
=
(uVar10 >>
0x10
| uVar10 <<
0x10
) ^
*
param_1;
uVar11
=
(param_3[
1
] &
0xff00ff00
) >>
8
| (param_3[
1
] &
0xff00ff
) <<
8
;
uVar11
=
(uVar11 >>
0x10
| uVar11 <<
0x10
) ^ param_1[
1
];
uVar12
=
(param_3[
2
] &
0xff00ff00
) >>
8
| (param_3[
2
] &
0xff00ff
) <<
8
;
uVar12
=
(uVar12 >>
0x10
| uVar12 <<
0x10
) ^ param_1[
2
];
uVar14
=
*
(uint
*
)(&DAT_002bca7c
+
(ulong)(uVar10 >>
0x18
)
*
4
) ^ param_1[
4
] ^
*
(uint
*
)(&DAT_002bce7c
+
(ulong)(uVar11 >>
0x10
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd27c
+
(ulong)(uVar12 >>
8
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd67c
+
(ulong)(uVar9 &
0xff
)
*
4
);
uVar1
=
*
(uint
*
)(&DAT_002bca7c
+
(ulong)(uVar12 >>
0x18
)
*
4
) ^ param_1[
6
] ^
*
(uint
*
)(&DAT_002bce7c
+
(ulong)(uVar9 >>
0x10
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd27c
+
(ulong)(uVar10 >>
8
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd67c
+
(ulong)(uVar11 &
0xff
)
*
4
);
uVar2
=
*
(uint
*
)(&DAT_002bca7c
+
(ulong)(uVar11 >>
0x18
)
*
4
) ^ param_1[
5
] ^
*
(uint
*
)(&DAT_002bce7c
+
(ulong)(uVar12 >>
0x10
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd27c
+
(ulong)(uVar9 >>
8
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd67c
+
(ulong)(uVar10 &
0xff
)
*
4
);
uVar9
=
*
(uint
*
)(&DAT_002bca7c
+
(ulong)(uVar9 >>
0x18
)
*
4
) ^ param_1[
7
] ^
*
(uint
*
)(&DAT_002bce7c
+
(ulong)(uVar10 >>
0x10
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd27c
+
(ulong)(uVar11 >>
8
&
0xff
)
*
4
) ^
*
(uint
*
)(&DAT_002bd67c
+
(ulong)(uVar12 &
0xff
)
*
4
);
|
更多【记一次对vm保护的算法的快速定位】相关视频教程:www.yxfzedu.com
相关文章推荐
- CTF对抗-2022祥云杯CTF babyparser - Android安全CTF对抗IOS安全
- Android安全-【从源码过反调试】中间篇-给安卓12内核增加个syscall - Android安全CTF对抗IOS安全
- CTF对抗- 2022 KCTF 第五题 灾荒蔓延 98k Writeup - Android安全CTF对抗IOS安全
- 编程技术-简单Win32的Shellcode实现框架和解析 - Android安全CTF对抗IOS安全
- 编程技术-使用神经网络拟合数学函数 - Android安全CTF对抗IOS安全
- Android安全- Android 内存执行ELF研究 - Android安全CTF对抗IOS安全
- CTF对抗-KCTF2022秋季赛第二题题解 - Android安全CTF对抗IOS安全
- 软件逆向-RotaJakiro后门与Buni后门关联性分析 - Android安全CTF对抗IOS安全
- CTF对抗-2022KCTF秋季赛 第三题 水患猖獗 - Android安全CTF对抗IOS安全
- 二进制漏洞-linux内核pwn之基础rop提权 - Android安全CTF对抗IOS安全
- Android安全-Base64 编码原理 && 实现 - Android安全CTF对抗IOS安全
- 软件逆向-对双机调试下KdDebuggerNotPresent标志位的研究 - Android安全CTF对抗IOS安全
- CTF对抗-KCTF2022秋季赛第二题分析(4qwerty7) - Android安全CTF对抗IOS安全
- Pwn-从某新生赛入门PWN(一) - Android安全CTF对抗IOS安全
- CTF对抗-KCTF 2022 秋季赛 第二题 wp - 98k战队 - Android安全CTF对抗IOS安全
- Android安全- 60秒学会用eBPF-BCC hook系统调用 ( 2 ) hook安卓所有syscall - Android安全CTF对抗IOS安全
- Pwn-pwn题jarvisoj_fm - Android安全CTF对抗IOS安全
- 软件逆向-[分享]Hello,R3入R0 - Android安全CTF对抗IOS安全
- 编程技术-小工具_通过串口上传下载文件 - Android安全CTF对抗IOS安全
- Android安全-安卓协议逆向之frida hook百例二 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com