Android安全-某大厂风控sdk vmp算法分析
推荐 原创【Android安全-某大厂风控sdk vmp算法分析】此文章归类为:Android安全。
某大厂风控sdk vmp算法分析
某大厂旗下的社交软件风控sdk由m指纹,和sign1,sign2签名组成,sign2是去年年底12月or今年年初新加的.这个so有好几套vmp,一套vmp版的白盒aes作用于sign2,一套vmp的Curve25519在初始化的过程同时也是给m的密钥,此外还有一套似乎是变种的标准aes用来加密m,两套aes差别很大.
由于这个厂法务很牛,细节就不多说了,说说大概流程,懂的自然知道在说什么,不懂的看了也没多大帮助.
大概花了一周时间把算法全部分析清楚了,上周一开始的,从最简单的sign1开始,花了一天半时间,m花了两天时间,sign2花了三天半时间.
首先把unidbg补好,主要是反射的代码unidbg没有实现好,仿照unidbg中类似方法实现即可,还有就是初始化的时候过滤掉日志或者解密的函数调用,避免引起干扰,其他的问题不大.
sign1
首先是把输入sha256一下,这里好像不是vmp,有点久了,忘了,反正不管是vmp还是ollvm的标准hash算法,只要找k,iv,就一定可以找到明文,对于像crc32这种没k或者iv的,可以匹配特征,总之就是标准hash无论是ollvm还是vmp都等于没有防护.熟练之后在trace文件里匹配特征不用5分钟就能完成一个标准hash.
输入的sha256后拆分了两段,后面16字节直接给sign1的最后面16字节,前面16字节经过一个小算法处理给sign1的前16字节.一开始没看懂前16字节怎么处理的,从后往前推,发现每一个字节都是单独处理的,并且如果往上追踪所需字节的生成,就会陷入一个很大的死循环,这里大概费了半天时间才搞明白要从前往后推.
原本思路是从后往前追踪,行不通之后开始考虑结果和上面的sha256有关,修改sha256最终的结果发现无论怎么改只与前16字节有关,所以考虑从sha256刚出结果开始trace,跑出最终结果后断开,这样这段算法大概只有5000行汇编

这是一个函数的入口,刚开始没看懂v0是什么,arm64一般用X0 - X7传参,返回值给x0,但是这里不一样,入参和中间变量全部保存到v0+偏移的位置,这里的v0是x19,也就是全部保存到了x19的位置.没看懂之前想尝试纯汇编还原 如果一条一条指令翻译的话5000条至少要1个星期,还是不翻译错的情况下,并且还要修正,确保所有入参的情况下结果都是对的.
以下是这个函数的入口的伪c,大概要还原100多个函数即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 | _QWORD *sub_242930(){ __int64 v0; // x19 unsigned __int8 *v1; // x20 unsigned __int8 *v2; // x22 unsigned __int8 *v3; // x23 unsigned __int64 v4; // x8 unsigned __int8 *v5; // x1 unsigned __int64 v6; // x2 unsigned __int64 v7; // x8 unsigned __int8 *v8; // x1 unsigned __int64 v9; // x2 unsigned __int64 v10; // x8 unsigned __int8 *v11; // x1 unsigned __int64 v12; // x2 unsigned __int64 v13; // x8 bool v14; // zf unsigned __int64 v15; // x8 unsigned __int64 v16; // x2 __int64 v17; // x1 unsigned __int64 v18; // x8 bool v19; // zf unsigned __int64 v20; // x8 unsigned __int64 v21; // x2 __int64 v22; // x1 char v23; // w8 char v24; // w11 char v25; // w8 int v26; // w12 char v27; // w11 bool v28; // nf char v29; // w12 char v30; // w9 char v31; // w9 char v32; // w8 char v33; // w8 char v34; // w8 char *v35; // x9 sub_4E5D50(*(v0 + 0x38)); v4 = *v2; if ( (v4 & 1) != 0 ) v5 = *(v2 + 2); else v5 = v2 + 1; if ( (v4 & 1) != 0 ) v6 = *(v2 + 1); else v6 = v4 >> 1; (sub_4E5E70)(*(v0 + 0x38), v5, v6); (sub_4E5E70)(*(v0 + 0x38), off_622128 + 0xFD77E6A4, 1LL); v7 = *v3; if ( (v7 & 1) != 0 ) v8 = *(v3 + 2); else v8 = v3 + 1; if ( (v7 & 1) != 0 ) v9 = *(v3 + 1); else v9 = v7 >> 1; (sub_4E5E70)(*(v0 + 0x38), v8, v9); (sub_4E5E70)(*(v0 + 0x38), off_622128 + 0xFD77E6A4, 1LL); v10 = *v1; if ( (v10 & 1) != 0 ) v11 = *(v1 + 2); else v11 = v1 + 1; if ( (v10 & 1) != 0 ) v12 = *(v1 + 1); else v12 = v10 >> 1; (sub_4E5E70)(*(v0 + 0x38), v11, v12); (sub_4E5E70)(*(v0 + 0x38), off_622128 + 0xFD77E6A4, 1LL); v13 = **(v0 + 0x120); v14 = (v13 & 1) == 0; *(v0 + 0x390) = *(v0 + 0x48) + 0x10LL; v15 = v13 >> 1; if ( v14 ) v16 = v15; else v16 = *(*(v0 + 0x48) + 8LL); if ( v14 ) v17 = *(v0 + 0x48) + 1LL; else v17 = **(v0 + 0x390); (sub_4E5E70)(*(v0 + 0x38), v17, v16); (sub_4E5E70)(*(v0 + 0x38), off_622128 + 0xFD77E6A4, 1LL); v18 = **(v0 + 0x148); v19 = (v18 & 1) == 0; *(v0 + 0x398) = *(v0 + 0x58) + 0x10LL; v20 = v18 >> 1; if ( v19 ) v21 = v20; else v21 = *(*(v0 + 0x58) + 8LL); if ( v19 ) v22 = *(v0 + 0x58) + 1LL; else v22 = **(v0 + 0x398); (sub_4E5E70)(*(v0 + 0x38), v22, v21); sub_4E6C94(*(v0 + 0x38), *(v0 + 0xF8)); v23 = **(v0 + 0xF8); v24 = 2 * v23; *(v0 + 0x3A0) = *(v0 + 0x40) + 1LL; v25 = v23 | 0x80; v26 = v24; v27 = v24 ^ 0x1B; v28 = v26 < 0; v29 = (2 * v27) ^ 0x1B; *(v0 + 0x3AC) = **(v0 + 0x3A0); if ( !v28 ) v29 = 2 * v27; *(v0 + 0x3B0) = *(v0 + 0x40) + 2LL; *(v0 + 0x3BC) = **(v0 + 0x3B0); *(v0 + 0x3C0) = *(v0 + 0x40) + 3LL; *(v0 + 0x3CC) = **(v0 + 0x3C0); *(v0 + 0x3D0) = *(v0 + 0x40) + 4LL; *(v0 + 0x3DC) = **(v0 + 0x3D0); *(v0 + 0x3E0) = *(v0 + 0x40) + 5LL; *(v0 + 0x3EC) = **(v0 + 0x3E0); *(v0 + 0x3F0) = *(v0 + 0x40) + 6LL; *(v0 + 0x3FC) = **(v0 + 0x3F0); *(v0 + 0x400) = *(v0 + 0x40) + 7LL; *(v0 + 0x40C) = **(v0 + 0x400); *(v0 + 0x410) = *(v0 + 0x40) + 8LL; *(v0 + 0x41C) = **(v0 + 0x410); *(v0 + 0x420) = *(v0 + 0x40) + 9LL; *(v0 + 0x42C) = **(v0 + 0x420); *(v0 + 0x430) = *(v0 + 0x40) + 0xALL; *(v0 + 0x43C) = **(v0 + 0x430); *(v0 + 0x440) = *(v0 + 0x40) + 0xBLL; *(v0 + 0x44C) = **(v0 + 0x440); *(v0 + 0x450) = *(v0 + 0x40) + 0xCLL; *(v0 + 0x45C) = **(v0 + 0x450); *(v0 + 0x460) = *(v0 + 0x40) + 0xDLL; *(v0 + 0x46C) = **(v0 + 0x460); *(v0 + 0x470) = *(v0 + 0x40) + 0xELL; *(v0 + 0x47C) = **(v0 + 0x470); *(v0 + 0x480) = *(v0 + 0x40) + 0xFLL; v30 = **(v0 + 0x480); *(v0 + 0x48C) = v25; *(v0 + 0x488) = v30; v31 = 2 * v29; *(v0 + 0x490) = v27 ^ *(v0 + 0x48C); v32 = *(v0 + 0x490); if ( v29 < 0 ) v31 = (2 * v29) ^ 0x1B; *(v0 + 0x498) = v31; *(v0 + 0x494) = v29 ^ v32; v33 = 2 * *(v0 + 0x498); if ( *(v0 + 0x498) < 0 ) v33 ^= 0x1Bu; *(v0 + 0x49C) = v33; v34 = 2 * *(v0 + 0x49C); if ( *(v0 + 0x49C) < 0 ) v34 ^= 0x1Bu; *(v0 + 0x4A0) = v34; *(v0 + 0x4A4) = 2 * *(v0 + 0x4A0); v35 = off_621E50 + (sub_2406D8 - 0x39B12F4 + 0x725EA4); *(v0 + 0x4A7) = *(v0 + 0x4A0) >= 0; return (v35)(0x39B12F4, 0x621000LL, 0x621000LL);} |
还原python之后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | table = list(bytearray(bytes.fromhex(begin)))v0 = [0] * 4096# 242930v23 = table[0]v24 = 2 * v23 & 0xffv0[0x3a0] = table[1]v25 = v23 | 0x80v26 = v24v27 = v24 ^ 0x1Bv28 = (v26 & 0xFF) - ((v26 & 0x80) << 1) < 0v29 = (2 * v27)& 0xff ^ 0x1Bv0[0x3ac] = v0[0x3a0]if not v28: v29 = (2 * v27) & 0xffv0[0x3b0] = table[2]v0[0x3bc] = v0[0x3b0]v0[0x3c0] = table[3]v0[0x3cc] =v0[0x3c0]v0[0x3d0] = table[4]v0[0x3dc] = v0[0x3d0]v0[0x3e0] = table[5]v0[0x3ec] = v0[0x3e0]v0[0x3f0] = table[6]v0[0x3fc] = v0[0x3f0]v0[0x400] = table[7]v0[0x40c] = v0[0x400]v0[0x410] = table[8]v0[0x41c] = v0[0x410]v0[0x420] = table[9]v0[0x42c] = v0[0x420]v0[0x430] = table[10]v0[0x43c] = v0[0x430]v0[0x440] = table[11]v0[0x44c] = v0[0x440]v0[0x450] = table[12]v0[0x45c] = v0[0x450]v0[0x460] = table[13]v0[0x46c] = v0[0x460]v0[0x470] = table[14]v0[0x47c] = v0[0x470]v0[0x480] = table[15]v30 = v0[0x480]v0[0x48c] = v25v0[0x488] = v30v31 = 2 * v29 &0xffv0[0x490] = v27 ^ v0[0x48c]v32 = v0[0x490]if (v29 & 0xFF) - ((v29 & 0x80) << 1) < 0: v31 = (2 * v29)&0xff ^ 0x1Bv0[0x498] = v31v0[0x494] = v29 ^ v32v33 = 2 * v0[0x498] &0xffif (v0[0x498] & 0xFF) - ((v0[0x498] & 0x80) << 1) < 0: v33 ^= 0x1Bv0[0x49c] = v33v34 = 2 * v0[0x49c] &0xffif (v0[0x49c] & 0xFF) - ((v0[0x49c] & 0x80) << 1) < 0: v34 ^= 0x1Bv0[0x4a0] = v34v0[0x4a4] = 2 * v0[0x4a0] &0xffv0[0x4a7] = int((v0[0x4a0] & 0xFF) - ((v0[0x4a0] & 0x80) << 1) >= 0) |
只需要有练习时长两年半的经验即可又快又准的还原成python,当然遇到不一样的地方还得对着汇编来看,100多个函数1天就完成了,完成后还得进行修正,难免会有错误的地方,比如这次入参结果是对的,另一组就不对.

这里还有一个伽罗瓦域内乘 GF(2^8) 在0x2上的乘法,如上图框所示,判断v0[0x4a8]<0时,v2就^0x1b,对应下面的num>=0x80,^0x1b
按伪c翻译成python的话就是(v2 & 0xFF) - ((v2 & 0x80) << 1) < 0就^0x1b,不能直接复制上面的<,同理后面还有>=
1 2 3 4 5 6 | def mul_by_02(num): # 伽罗瓦域内乘 GF(2^8) * 0x02 if num < 0x80: res = (num << 1) else: res = (num << 1) ^ 0x1b return res % 0x100 |
全部扣出来后再手动调整一下确保所有情况下输入输出能对应上.
这个基本没有多大难度,只要方向正确就是熟练度的问题.
m指纹
m里面主要加密指纹数据,先说加密方法,后面再说加密了哪些指纹.
m的前半部分base64解码后有一个key,抓包中发现是变化的,需要找到生成算法.
后半部分首先是指纹zilb压缩一下,打印memcpy的时候看到78 9c,这个zlib的压缩头,压缩后的长度和m base64解码后的长度对等,猜测是分组加密,trace中搜索输入发现异或了上一组的密文,找到了iv,说明可能是cbc模式.trace这个iv的写入发现和另一组16字节的数据写在相邻地址,拿去验证发现是标准aes.如果要trace还原密钥的话,比较困难,因为这个aes也是一个变种的aes,这个aes部分大概跑了100多万汇编左右,虽然不在vmp里面,但确实和标准的处理很不一样,但确实是标准aes,就没看后续了.
解密抓包中m发现无法解密出来,考虑是否是动态key iv,trace key iv写入发现是在第二步初始化的过程写入,单独trace发现这里跑了300w左右.
最开始我把随机数都固定成0了,发现m前半部分的k 是2fe57da347cd62431528daac5fbb290730fff684afc4cfc2ed90995f58cb3b74
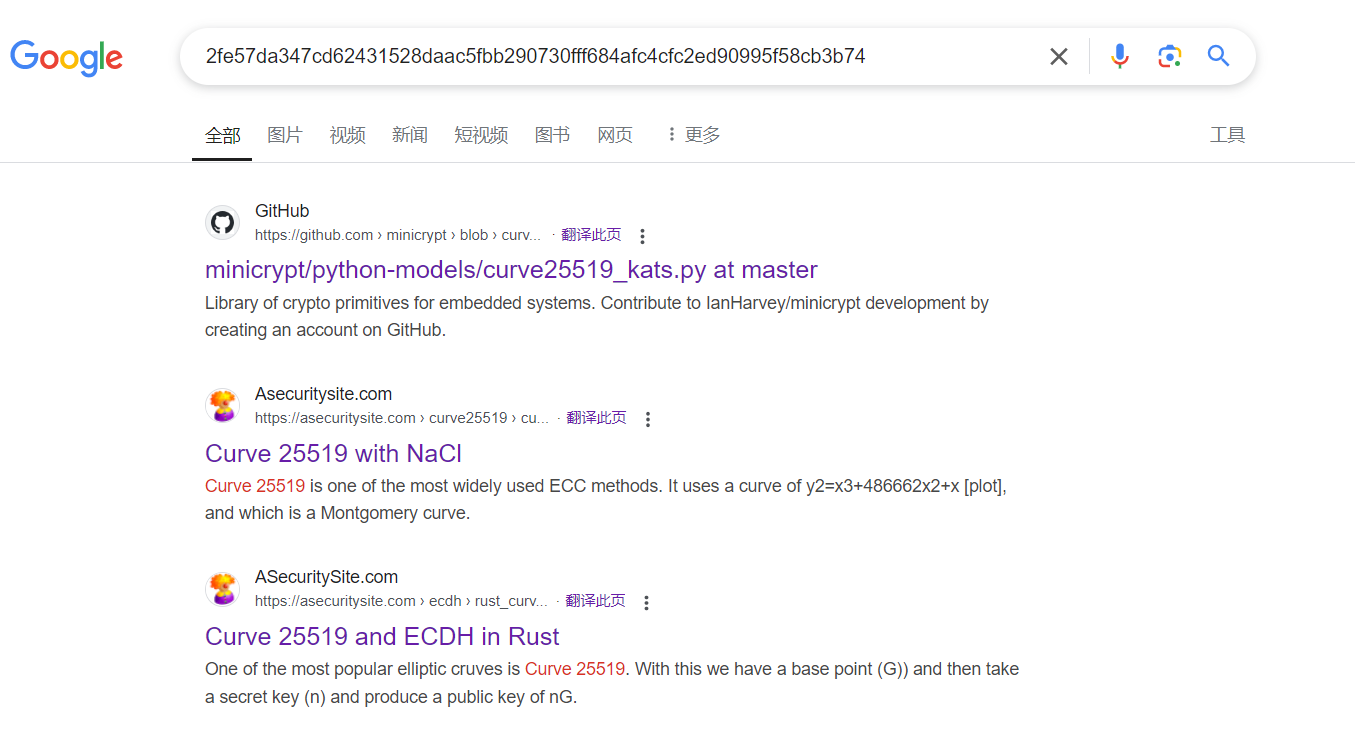
搜索的结果里面刚好有,拿去验证下,发现是标准的 curve25519,输入是随机的32字节0x00
1 2 3 4 5 6 7 8 9 10 11 | from cryptography.hazmat.primitives import serializationfrom cryptography.hazmat.primitives.asymmetric import x25519alice_sk_hex = "0000000000000000000000000000000000000000000000000000000000000000"alice_sk_bytes = bytes.fromhex(alice_sk_hex)# 根据字节数据创建密钥对象alice_private_key = x25519.X25519PrivateKey.from_private_bytes(alice_sk_bytes)public_key = alice_private_key.public_key().public_bytes(encoding=serialization.Encoding.Raw,format=serialization.PublicFormat.Raw).hex()print(public_key) |
刚开始不知道这个算法是个什么东西,以为我需要的key和iv也是通过类似方法算的,比如再把m前面的key也这样算一下,发现结果不对,又拿了一份python源码看,匹配输入和trace文件中寻找,我把输入换成了下面的,这样方便查找
1 | buf = new byte[]{0x0,0x01,0x02,0x03,0x04,0x05,0x06,0x07,0x08,0x09,0x0a,0x0b,0x0c,0x0d,0x0e,0x0f,0x10,0x11,0x12,0x13,0x14,0x15,0x16,0x17,0x18,0x19,0x1a,0x1b,0x1c,0x1d,0x1e,0x1f}; |
我发现输入确实进行了两次加密,并且分配均匀,300w行各拿一半,为什么下面的输入和上面的一样呢?
这里大概想了一晚上都没想明白,也没找到输入,睡一觉后脑子清醒了,第二天重新查找了关于curve25519的内容,发现这个东西还有个叫做共享密钥的存在.
根据查找的资料我整理了下关于curve25519的原理,这个算法和rsa这种有公私钥的不太一样,rsa只需一个私钥,一个公钥.这个算法需要有两个私钥,两个公钥,一个共享密钥来完成客户端和服务器的加解密.以下我以客户端和服务端的视角来模拟加解密的过程.
假设客户端app是alice,服务器是bob,这里有几个基础知识,私钥推导出公钥.公钥无法推导私钥
alice每次启动时随机生成32字节作为私钥1,由私钥1可以直接生成公钥1,也就是m前半部分里的东西
同理服务器bob有一组私钥2,测试过这组私钥不同版本是一样的,因为私钥2生成的公钥2是藏在so里面的,这个公钥2找到的结果是一样的.
私钥1和公钥2生成共享密钥,拆成两半当作key和iv用来加密,服务器bob接收密文和公钥1,服务器bob的私钥2和公钥1也可以生成共享密钥用来解密,共享密钥是一样的,这样即完成了加解密的过程.
对比https的 rsa加密aes的key,有什么不一样的吗?有的,区别很大. 在不hook的情况下,htpps的抓包可以解密,这种模式抓包了也解不了
从抓包(中间人攻击)的视角来看,对于https只要在客户端和服务器之间加一个抓包软件,比如charles,就可以完成密文的解密.
原理是客户端发请求给服务器,charles作为代理先收到客户端请求,charles返回一个rsa的公钥给客户端,客户端随机生成一组aes密钥通过rsa加密后给charles,后续客户端和charles通信即可通过aes的密钥完成加解密.与此同时,charles给服务器发请求,服务器发另一组rsa的公钥给charles,同理获得了和服务器加密的aes的key,这样charles既可以解密客户端请求里的东西,也可以解密服务器返回的内容.前提是客户端要信任charles安装的证书,也就是常说的证书安装和信任过程.
回到这里的curve25519,想要解密至少需要一把私钥,服务器的私钥不可能获得(渗透不现实),客户端的私钥不会出现在请求里,除非提前hook固定私钥,就可以解密.
如果这里也用rsa+aes的方式呢,只要服务器给客户端的公钥不加密,就可以实现类似上面charles的功能,也就是在不hook的情况下,可以完成解密替换等操作.
这里的算法主要就是动态aes key iv和curve25519,其他没什么难的地方.
固定私钥可以在刚生成随机的那个时候固定,不同版本位置不一样,匹配特征也可以快速找到.
另外一种办法就是 hook __read_chk函数,一开始hook /dev/urandom的read不知道为啥没生效,后来请教了寄予蓝大佬提供了这么一个方案,确实可行.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | function hook_dlopen() { Interceptor.attach(Module.findExportByName(null, "android_dlopen_ext"), { onEnter: function (args) { var pathptr = args[0]; if (pathptr !== undefined && pathptr != null) { var path = ptr(pathptr).readCString(); if(path.indexOf('libmsaoaidsec.so') >= 0){ ptr(pathptr).writeUtf8String(""); } // console.log('path: ',path) } } });}hook_dlopen()// Hook __read_chkInterceptor.attach(Module.findExportByName(null, "__read_chk"), { onEnter: function (args) { // console.log("[+] hook __read_chk"); this.fd = args[0].toInt32(); this.buffer = args[1]; this.size = args[2].toInt32(); this.bufsize = args[3].toInt32(); }, onLeave: function (retval) { if (this.size == 32) { console.log("[+] Original __read_chk data:", hexdump(this.buffer, {length:0x20})); // 定义要填入的hex字符串 const hexValues = [ 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0 ]; // 根据实际size决定写入多少数据 const writeSize = Math.min(this.size, hexValues.length); // 写入数据 for (var i = 0; i < writeSize; i++) { Memory.writeU8(this.buffer.add(i), hexValues[i]); } console.log("[+] Modified __read_chk data:", hexdump(this.buffer, {length:0x20})); console.log("[+] Modified /dev/urandom __read_chk:", this.size, "bytes"); } }}); |
这样即可解密抓包中的m.
m加密的指纹是一段json数据,键都是x开头的.uni大概有100多个,真机差不多200个
主要是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | package_nameversionro.build.fingerprintgsm.version.ril-impl 指示当前设备所使用的 RIL(Radio Interface Layer,射频接口层)实现的版本信息ro.config.ringtone 指定设备默认的来电铃声ro.build.host vpef12.mtv.corp.google.com 表示该系统固件(ROM)构建时所用的主机名uuidip_addr_list哈希校验、内存映射检测反调试(检测 proc/self/maps)动态库注入检测(LD_PRELOAD、appwidget)JIT 缓存完整性验证文件路径、内存段检查安装apk数量ro.build.iduaapk pathro.build.typero.build.version.incrementalro.build.version.releasero.build.version.sdkro.product.brand架构ro.build.display.idlocationmac地址ro.hardwarecpuinfoSensor |
等等,字段太多了,没完全研究...
sign2
sign2一个是这里面最难的了,也是trace中占大头的.单次执行函数4000w汇编,这里有3000w左右,不包括初始化的300w.
主要就是一个vmp版的白盒aes,把vmp版的白盒扣下来即可.还有一个就是动态输入和执行顺序,把输入拆成8块,搞4个加密函数,每次通过
对一个4字节的数据中的每个字节对0xa取整和取余,这样取出来有8个,刚好是1-8,另外一个2字节的同理是1-4,对应8块数据和4种调用方法,这就是aes输入的主要部分.最外层还有两个crc32.
对aes来说,方法对了,其实就不难,这里一共3次aes,拆成一次aes来做,大概900w汇编.之所以花了3天多是因为思维固定化了

aes前后都有异或操作,无论是匹配输入的异或,还是异或得到输出,都匹配不出结果,这个大概持续了一天毫无收获,第二天清醒了想着既然是魔改aes,会不会异或不是最前面的呢,于是开始匹配subbytes的内容,替换只一种指令可能,ldrb
举个例子 "ldrb w8, [x9, x8]" 从x9+x8偏移的位置取,x8就是动态的,可以由输入决定,那么x8呢
有可能就是输入,也有可能再次通过某个基值加上输入.如果直接是输入那就正则匹配 ldrb(.*?)0x67(.*?)=>,按照你的trace格式来
如果是通过某个基值加上输入就add(.*?)0x67
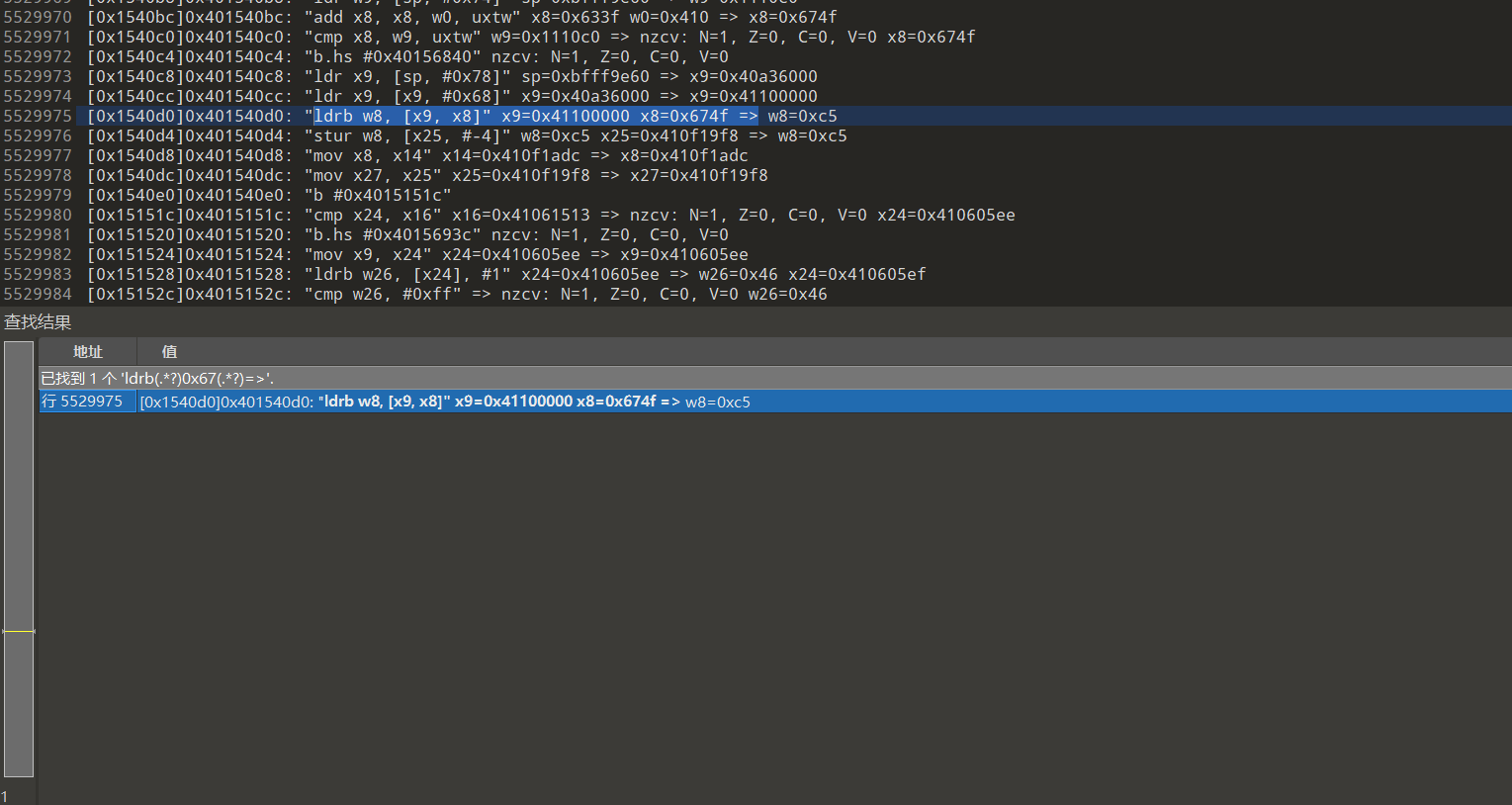
第一种没有,而且位置也太靠后了,下面这个就是匹配到了的
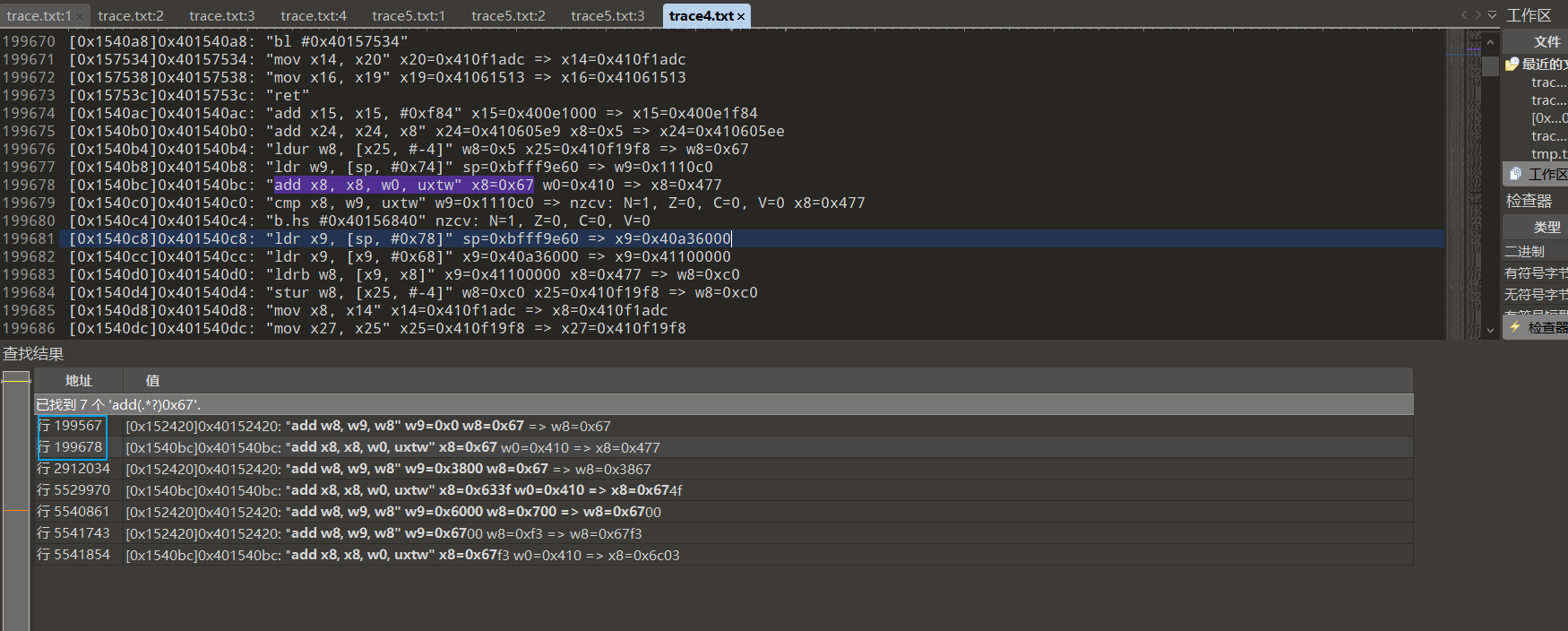
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 0x67+0x000=0x67+410=0x477 =>0xc0# 0xfa+0x700=0x7fa+410=c0a =>0xdc# 0x98+0xa00=0xa00+410=0xea8 =>0x99# 0x9d+0xd00=0xd9d+410=0x11ad =>0x89# 0x2c+0x100=0x12c+410=0x53c =>0x1b# 0xbe+0x400=0x4be+410=0x8ce =>0x3e# 0x60+0xb00=0xb60+410=0xf70 =>0xab# 0xde+0xe00=0xede+410=0x12ee =>0x56# 0x38+0x200=0x238+410=0x648 =>0xb3# 0xad+0x500=0x5ad+410=0x9bd =>0xa6# 0xb8+0x800=0x8b8+410=0xcc8 =>0xbd# 0xd1+0xf00=0xfd1+410=0x13e1 =>0x11# 0xf8+0x300=0x3f8+410=0x808 =>0xe8# 0xaa+0x600=0x6aa+410=0xaba =>0x46# 0x7b+0x900=0x97b+410=0xd8b =>0x84# 0xed+0xc00=0xced+410=0x10fd =>0x57 |
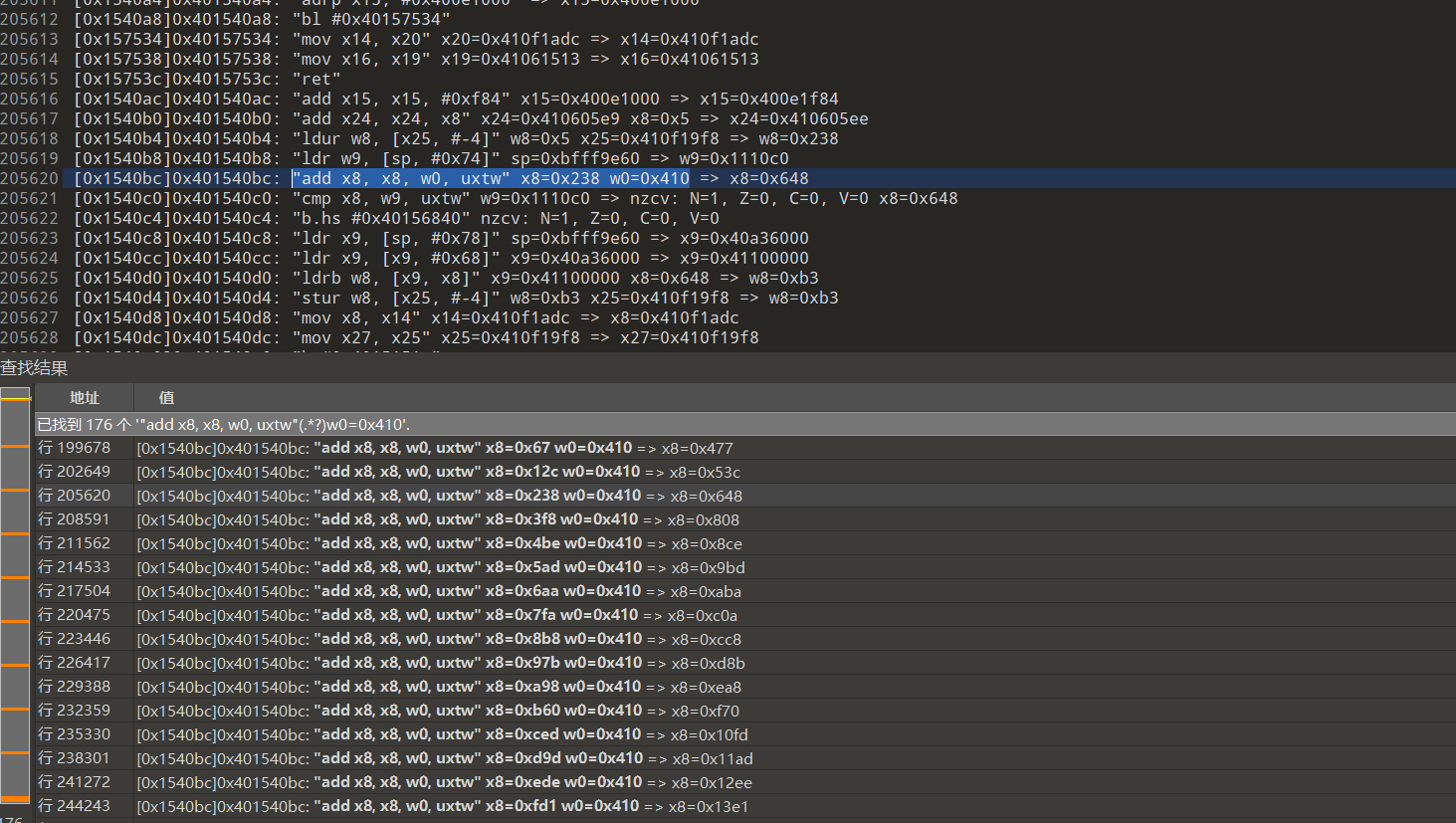
再次匹配特征就能看到11轮了,11个subBytes,中间9个就是mixCloumns,后续就是酷酷扣就行了. 扣出来就是11*16*256的大表,中间还夹着移位操作,这也不难.对比抖音的轻量级aes难度差不多,区别就是抖音的是两轮
扣出来后顺便看了下解密,看看真机中的能否对应上,这里花了1小时调试.
后来和群里一位搞过ios的大佬探讨了一下,他说是标准aes,我对着源码dfa了一下,还真是,并且android和ios的密钥都是一样的.
最后说一下怎么区分vmp和ollvm,很多人都区分不清.

单看cfg或者case分发都容易误判,只有执行了多少汇编是最准确的,通常vmp过的代码执行数量会比ollvm的执行相差100倍左右,就是一个ollvm的aes20万行,vmp后就2000w行,实际上,单次执行一次aes,如果不进行多余操作,保守估计1w汇编就足够了.
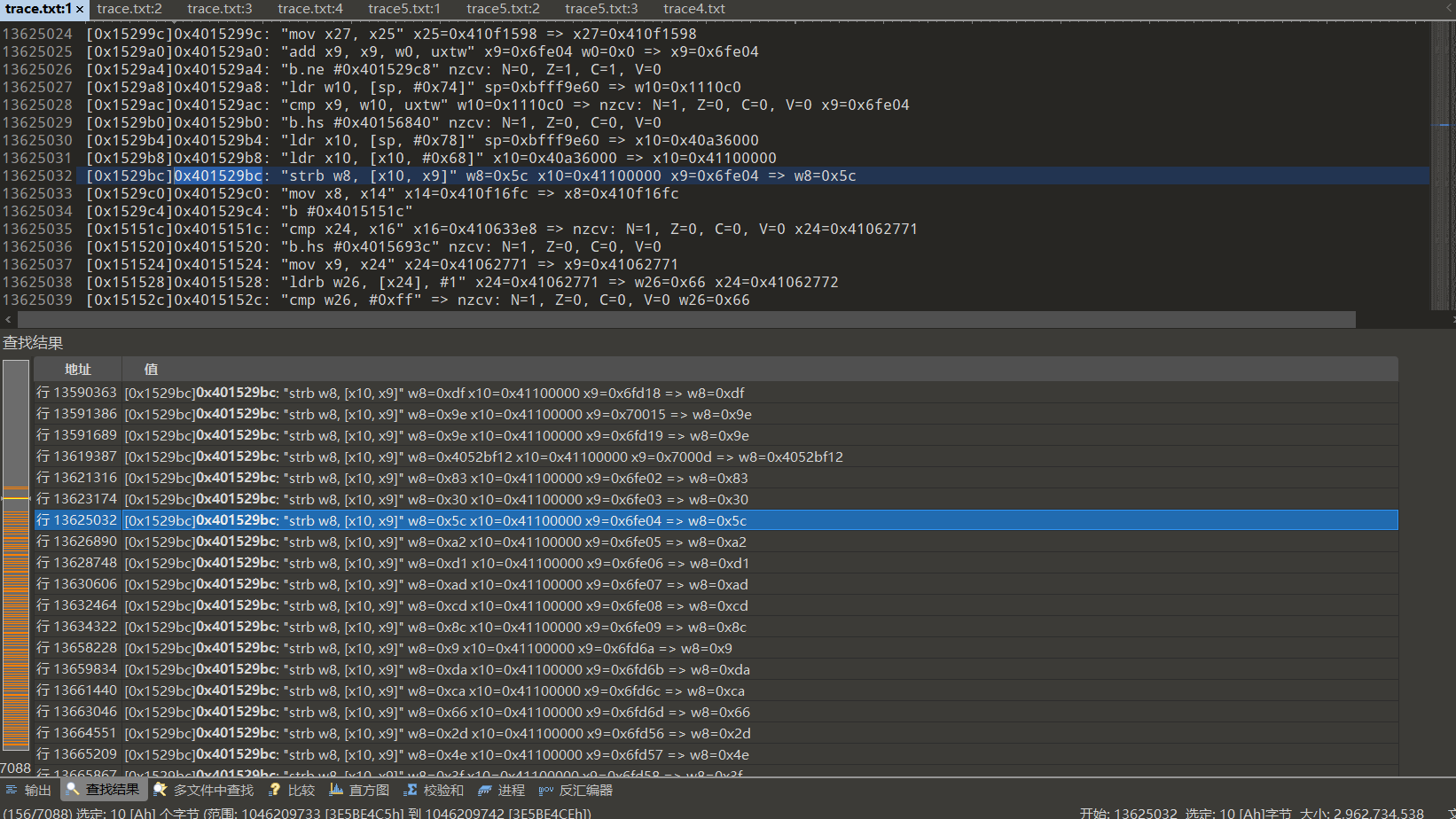
vmp会有特别多的ldr str 一个变量从出现到真正派上用场,中间可能隔了几万条指令.
参考链接:359K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6V1N6h3&6Q4x3X3f1I4y4U0y4Q4x3X3g2U0L8$3#2Q4x3V1k6F1k6i4N6K6i4K6u0r3M7q4)9J5c8U0b7$3j5U0c8S2x3h3f1H3k6e0S2T1x3K6c8S2k6o6y4T1x3e0V1$3k6o6k6T1j5K6M7$3y4$3f1@1z5h3u0X3
最后:有人会说,主播主播,你的trace确实很强,但是确实是太吃手法了,有没有更加强势的操作?有的,有的,兄弟,像这么强势的操作还有3种,你可以frida rpc,xposed rpc,还有unidbg spingboot,手残党福利,缺点就是慢和容易风控.

后期todo内容:某main,某guard...敬请期待
更多【Android安全-某大厂风控sdk vmp算法分析】相关视频教程:www.yxfzedu.com
相关文章推荐
- 二进制漏洞-win越界写漏洞分析 CVE-2020-1054 - Android安全CTF对抗IOS安全
- Pwn-2022长城杯决赛pwn - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter服务端 - Android安全CTF对抗IOS安全
- Pwn-沙箱逃逸之google ctf 2019 Monochromatic writeup - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com