编程技术-eBPF初学者编码实践
推荐 原创【编程技术-eBPF初学者编码实践】此文章归类为:编程技术。
1 | 初学者指eBPF技术初学者,并非编码初学者,至少要有C/C++,GO,Rust开发基础,本篇编码使用C/C++。 |
eBPF 是一项革命性的技术,起源于 Linux 内核,它可以在特权上下文中(如操作系统内核)运行沙盒程序。它用于安全有效地扩展内核的功能,而无需通过更改内核源代码或加载内核模块的方式来实现。
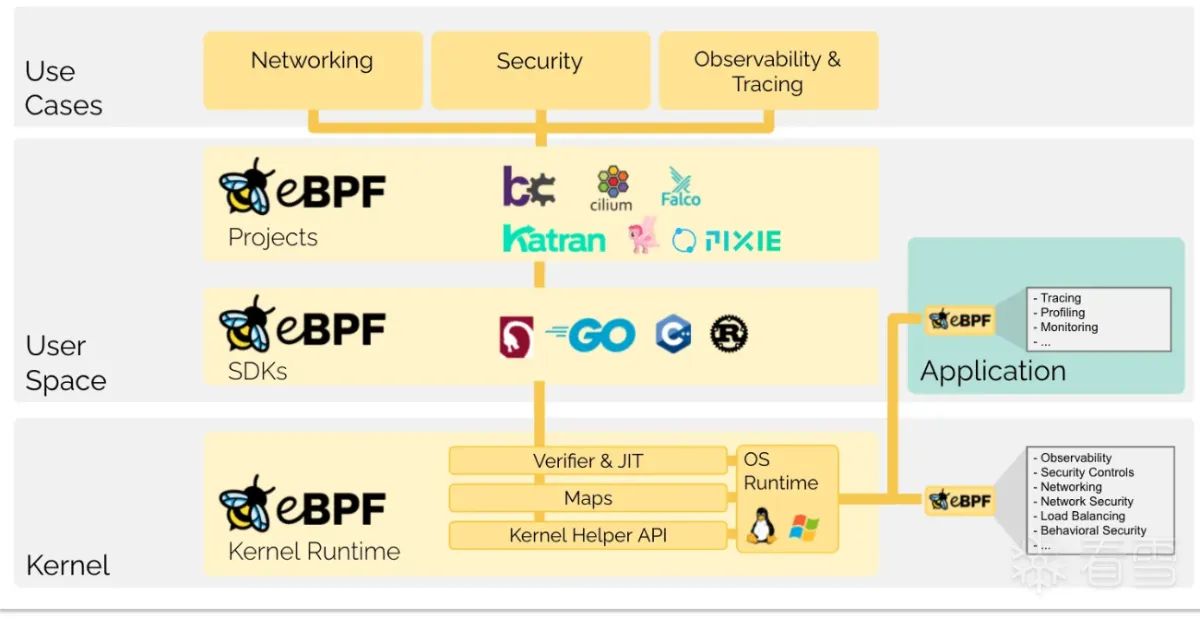
eBPF执行编译字节码,通过Just-In-Time编译成对应机器码,通常BPF Hook负责数据生产和动作执行,数据透传通过perfbuf和ringbuf方式消费。
Kernele 5.8支持ringbuf(BPF环形缓冲区),perf改良版,ringbuf兼容perf且高效,多生产单消费队列设计,本篇需要低内核版本兼容,使用perbuf来做数据传输。
题外话,微软高版本也在努力应用eBPF,也许不久的将来,会为Windows OS添上一笔"浓墨重彩"。
1 | https://github.com/microsoft/ebpf-for-windows |
eBPF编码环境
1 2 3 4 5 6 7 8 9 10 11 12 | Ubuntu 22 5.15.0-125-genericgcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0clang version 14.0.0-1ubuntu1.1 Target: x86_64-pc-linux-gnu Thread model: posixbpftool version /usr/lib/linux-tools/5.15.0-125-generic/bpftool v5.15.167# development installapt install linux-tools-5.15.0-125-generic -yapt install wget curl build-essential pkgconf zlib1g-dev llibssl-dev ibelf-dev -y |
eBPF编码实践
libbpf build
1 2 3 4 | git clone git@github.com:libbpf/libbpf.gitcd libbpf/srcmkdir build root BUILD_STATIC_ONLY=y OBJDIR=build DESTDIR=root make |
build目录生成libbpf.a,将libbpf.a和inlcude拷贝到项目工程下链接使用即可,cmake编译可添加如下:
1 2 3 4 5 6 7 | # 拷贝bpf/include 到目录下include_directories("../include/")# 拷贝libbpf.a 到目录下LINK_DIRECTORIES("../lib/bpf/") # 链接libbpf.atarget_link_libraries(ebpftrace libbpf.a elf z) |
创建三个空白文件,分别traceEngin.h,traceEngin_maps.h,traceEngin.c
1 2 3 4 | | vmlinux.h | 系统自带头文件,包含内核中使用的有数据类型定义. | find / -name vmlinux* | | traceEngin.h | 头文件 | || traceEngin_maps.h | 通用数据结构存储模板类型 | || traceEngin.c | 代码实现,.c文件可以是多个,也可以编码同一个文件中 | | |
Capture Network
小试牛刀,基于eBPF Hook监控Linux流量,调研eBPF流量方案,eBPF Tc Hook和 eBPF Socket API Hook。
eBPF Tc
Tc流量控制子系统Traffic Control,Kernel 4.1开始支持eBPF挂钩点,Tc协议栈位置在链路层,类Windows OS NDIS网络驱动框架。
r0 eBPF
1 2 3 4 5 | qdisc(队列规则):qdisc是Linux中用于管理数据包的核心数据结构。数据包从网络层进入qdisc,然后根据不同的策略被发送到设备驱动层。qdisc有很多种类型,如pfifo_fast(默认)、htb(层次令牌桶)、tbf(令牌桶过滤器)等。class(分类):class是qdisc内部的一个逻辑分组,用于实现更细粒度的流量控制。每个class都有一个唯一的ID,可以设置特定的速率限制、优先级等属性。filter(过滤器):filter用于根据数据包的特征(如IP地址、端口、协议等)将其分类到不同的class。常用的过滤器有u32、fw(防火墙标记)、route(路由表)等 |
eBPF Tc支持的挂钩点可以接参考libbpf.c中static const struct bpf_sec_def section_defs.
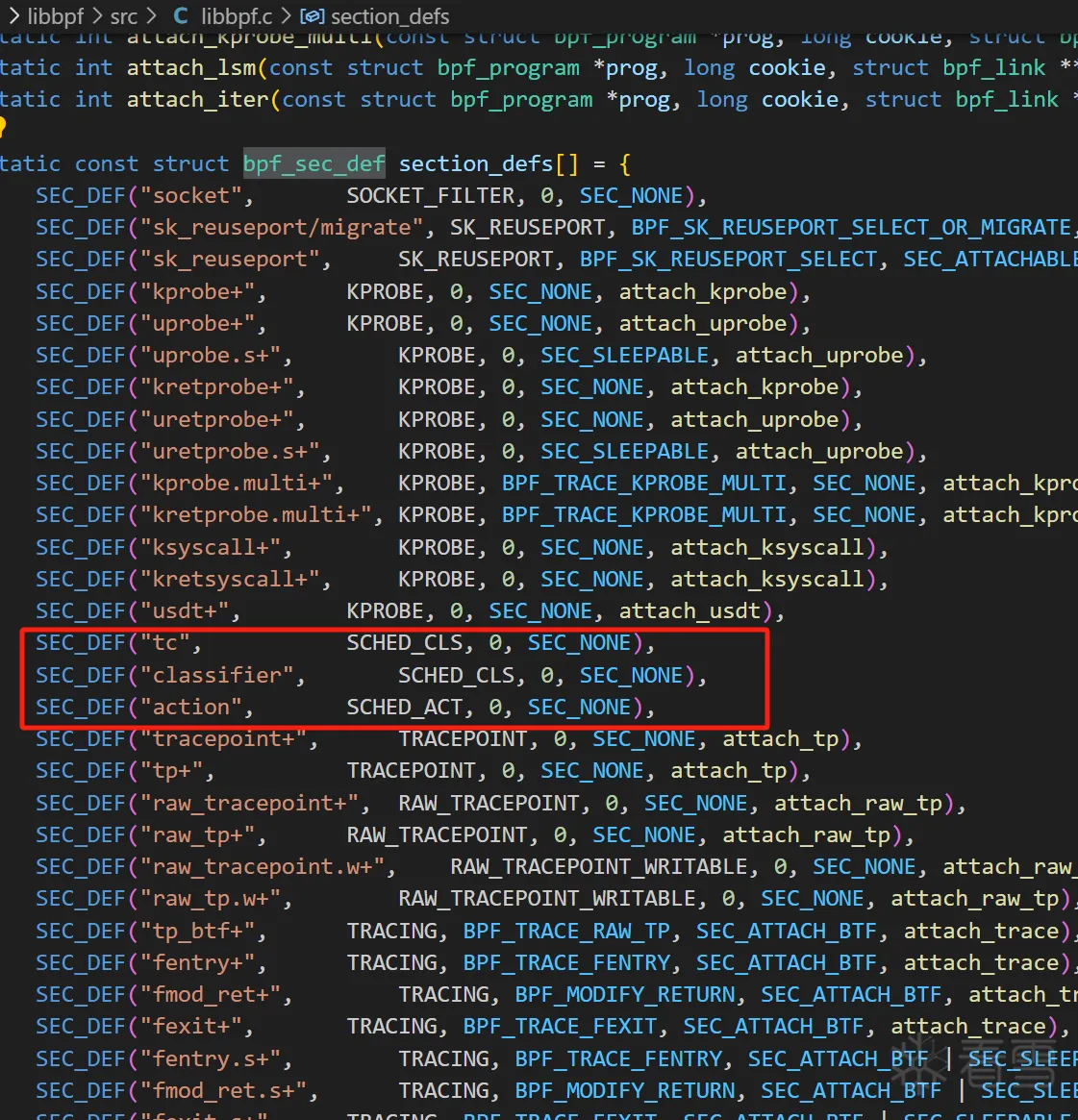
1 2 3 4 5 6 7 8 9 10 | queueing discipline (qdisc):排队规则,根据某种算法完成限速、整形等功能class:用户定义的流量类别classifier (也称为 filter):分类器,分类规则action:要对包执行什么动作TC_ACT_UNSPEC (-1) 默认返回值TC_ACT_OK (0) 放行TC_ACT_RECLASSIFY (1) 重注分类,类似于WFP的包重注TC_ACT_SHOT (2) 丢包TC_ACT_PIPE (3) 传递执行 |
More See: https://eunomia.dev/zh/tutorials/bcc-documents/kernel-versions/
eBPF Tc 分为ingress|egress,传递上下文是sk_buff结构。direct-action模式模理解为把classifier和action结合,内核中SEC("tc")和SEC("classifier")一样,官方推荐使用"tc",但低内核版本还是使用SEC("classifier_egress") or SEC("classifier_ingress")。
1 2 | BPF_PROG_TYPE_SCHED_CLS: a network traffic-control classifierBPF_PROG_TYPE_SCHED_ACT: a network traffic-control action |
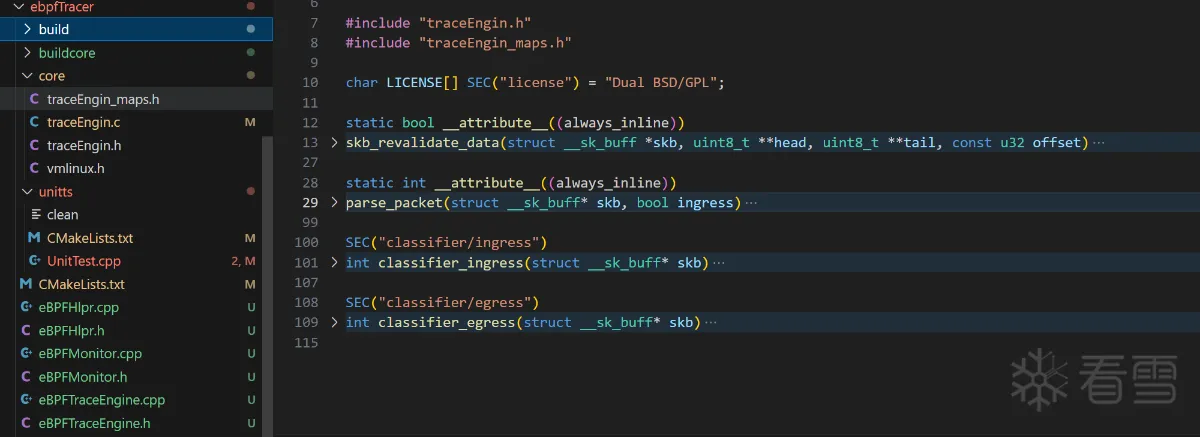
traceEngin.c中实现捕获ingress和egress数据流量,通过SEC("tc")定义eBPF程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #include "vmlinux.h"#include <bpf/bpf_helpers.h>#include <bpf/bpf_endian.h>#include <bpf/bpf_core_read.h>#include <bpf/bpf_tracing.h>#include "traceEngin.h"#include "traceEngin_maps.h"#include <string.h>__attribute__((always_inline)) static int parse_packet_tc(struct __sk_buff* skb, bool ingress){ __sk_buffer 处理.}/// @tchook {"ifindex":1, "attach_point":"BPF_TC_INGRESS"}/// @tcopts {"handle":1, "priority":1}SEC("tc")int classifier_ingress(struct __sk_buff* skb){ if(skb) return parse_packet_tc(skb, true); return 0;}/// @tchook {"ifindex":1, "attach_point":"BPF_TC_EGRESS"}/// @tcopts {"handle":1, "priority":1}SEC("tc")int classifier_egress(struct __sk_buff* skb){ if(skb) return parse_packet_tc(skb, false); return 0;} |
注释tchook告诉eBPF TC将eBPF程序附加到网络接口的ingress|egress附加点,注释tcopt是附加选项,priority表示优先级。
More See: https://patchwork.kernel.org/project/netdevbpf/patch/20210512103451.989420-3-memxor@gmail.com/
traceEngin.h声明自定义的数据结构(proc_ctx, network_ctx)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | #ifndef TRACEENGIN_H#define TRACEENGIN_H#define TASK_COMM_LEN 16#define INET_ADDRSTRLEN_EX 16#define INET6_ADDRSTRLEN_EX 46#define GET_FIELD_ADDR(field) __builtin_preserve_access_index(&field)#define READ_KERN(ptr) \ ({ \ typeof(ptr) _val; \ __builtin_memset((void *)&_val, 0, sizeof(_val)); \ bpf_core_read((void *)&_val, sizeof(_val), &ptr); \ _val; \ })#define READ_USER(ptr) \ ({ \ typeof(ptr) _val; \ __builtin_memset((void *)&_val, 0, sizeof(_val)); \ bpf_core_read_user((void *)&_val, sizeof(_val), &ptr); \ _val; \ })#define ETH_P_IP 0x0800#define ETH_P_IPV6 0x86DD#define TC_ACT_UNSPEC (-1)#define TC_ACT_OK 0#define TC_ACT_RECLASSIFY 1#define TC_ACT_SHOT 2struct proc_ctx { __u64 mntns_id; __u32 netns_id; __u32 pid; __u32 tid; __u32 uid; __u32 gid; __u8 comm[TASK_COMM_LEN];};struct network_ctx { bool ingress; uint32_t pid; uint32_t protocol; uint32_t ifindex; uint32_t local_address; uint32_t remote_address; struct in6_addr local_address_v6; struct in6_addr remote_address_v6; uint32_t local_port; uint32_t remote_port; uint32_t packet_size; uint64_t timestamp; struct proc_ctx socket_proc;};#endif /* TRACEENGIN_H */ |
traceEngin_maps.h中定义了eBPF networkMap,max_entries最大条数是10240,key和value用于存储生产数据,value保存network_ctx数据。
type表示MAP使用类型,HashMap就是哈希实现,BPF_MAP_TYPE_HASH key/value是可删除,BPF_MAP_TYPE_ARRAY数组类型,key/value是不可删除的,可覆盖value,存储超过max_entries最大条目就会报E2BIG错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | #ifndef TRACEENGIN_MAPS_H#define TRACEENGIN_MAPS_H#include "traceEngin.h"#define MAX_PERCPU_BUFSIZE (1 << 15)/* map macro defination */#define BPF_MAP(_name, _type, _key_type, _value_type, _max_entries) \ struct { \ __uint(type, _type); \ __type(key, _key_type); \ __type(value, _value_type); \ __uint(max_entries, _max_entries); \ } _name SEC(".maps");#define BPF_HASH(_name, _key_type, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_HASH, _key_type, _value_type, _max_entries)#define BPF_LRU_HASH(_name, _key_type, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_LRU_HASH, _key_type, _value_type, _max_entries)#define BPF_LPM_TRIE(_name, _key_type, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_LPM_TRIE, _key_type, _value_type, _max_entries)#define BPF_ARRAY(_name, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_ARRAY, __u32, _value_type, _max_entries)#define BPF_PERCPU_ARRAY(_name, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_PERCPU_ARRAY, __u32, _value_type, _max_entries)#define BPF_PROG_ARRAY(_name, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_PROG_ARRAY, __u32, __u32, _max_entries)#define BPF_PERF_OUTPUT(_name, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_PERF_EVENT_ARRAY, int, __u32, _max_entries)#define BPF_PERCPU_HASH(_name, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_PERCPU_HASH, int, int, _max_entries)#define BPF_SOCKHASH(_name, _key_type, _value_type, _max_entries) \ BPF_MAP(_name, BPF_MAP_TYPE_SOCKHASH, _key_type, _value_type, _max_entries)typedef struct simple_buf { __u8 buf[MAX_PERCPU_BUFSIZE];} buf_t;/* perf_output for events */// BPF_PERF_OUTPUT(exec_events, 1024);// BPF_PERF_OUTPUT(file_events, 1024);// BPF_PERF_OUTPUT(net_events, 1024);struct { __uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY); __uint(key_size, sizeof(int)); __uint(value_size, sizeof(u32)); __uint(max_entries, 1024);} eventMap SEC(".maps");// create a map to hold the network informationstruct { __uint(type, BPF_MAP_TYPE_HASH); __type(key, int); __type(value, struct network_ctx); __uint(max_entries, 1024);} networkMap SEC(".maps");#endif |
eBPF位置属于数据链路层,__sk_buff的数据也是链路层上下文, 按照四层协议封包结构如下,__sk_buff数据[ethhdr] + [ip|icmp] + [tcp|udp] + [data]
1 2 3 4 | | ethhdr | 数据链路层 || iphdr | 网络层 || tcp/udp | 传输层 || data | 应用层 | |
traceEngin.c函数parse_packe解析__sk_buff结构,代码对TCP|UDP v4/v6 [protocol,src:port,dests:port,ingress]关键数据提取,通过bpf_perf_event_output传输数据给应用层消费.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 | __attribute__((always_inline))static bool skb_revalidate_data(struct __sk_buff *skb, uint8_t **head, uint8_t **tail, const u32 offset){ if (*head + offset > *tail) { if (bpf_skb_pull_data(skb, offset) < 0) { return false; } *head = (uint8_t *) (long) skb->data; *tail = (uint8_t *) (long) skb->data_end; if (*head + offset > *tail) { return false; } } return true;}__attribute__((always_inline))static int parse_packet_tc(struct __sk_buff* skb, bool ingress){ if(!skb || (NULL == skb)) return 0; // packet pre check uint8_t* packet_start = (uint8_t*)(long)skb->data; uint8_t* packet_end = (uint8_t*)(long)skb->data_end; if (packet_start + sizeof(struct ethhdr) > packet_end) return TC_ACT_UNSPEC; struct ethhdr* eth = (struct ethhdr*)packet_start; if(!eth || (NULL == eth)) return TC_ACT_UNSPEC; // get ip hdr packet uint32_t hdr_off_len = 0; struct network_ctx net_ctx = { 0, }; const int type = bpf_ntohs(eth->h_proto); if(type == ETH_P_IP) { hdr_off_len = sizeof(struct ethhdr) + sizeof(struct iphdr); if (!skb_revalidate_data(skb, &packet_start, &packet_end, hdr_off_len)) return TC_ACT_UNSPEC; struct iphdr* ip = (void*)packet_start + sizeof(struct ethhdr); if (!ip || (NULL == ip)) return TC_ACT_UNSPEC; net_ctx.local_address = ip->saddr; net_ctx.remote_address = ip->daddr; net_ctx.protocol = ip->protocol; } else if( type == ETH_P_IPV6) { hdr_off_len = sizeof(struct ethhdr) + sizeof(struct ipv6hdr); if (!skb_revalidate_data(skb, &packet_start, &packet_end, hdr_off_len)) return TC_ACT_UNSPEC; struct ipv6hdr* ip6 = (void*)packet_start + sizeof(struct ethhdr); if (!ip6 || (NULL == ip6)) return TC_ACT_UNSPEC; net_ctx.local_address_v6 = ip6->saddr; net_ctx.remote_address_v6 = ip6->daddr; net_ctx.protocol = ip6->nexthdr; } else return TC_ACT_UNSPEC; // get network hdr packet if (IPPROTO_TCP == net_ctx.protocol) { if (!skb_revalidate_data(skb, &packet_start, &packet_end, hdr_off_len + sizeof(struct tcphdr))) return TC_ACT_UNSPEC; struct tcphdr* tcp = (void*)packet_start + hdr_off_len; if (!tcp || (NULL == tcp)) return TC_ACT_UNSPEC; net_ctx.local_port = tcp->source; net_ctx.remote_port = tcp->dest; } else if (IPPROTO_UDP == net_ctx.protocol) { if (!skb_revalidate_data(skb, &packet_start, &packet_end, hdr_off_len + sizeof(struct udphdr))) return TC_ACT_UNSPEC; struct udphdr* udp = (void*)packet_start + hdr_off_len; if (!udp || (NULL == udp)) return TC_ACT_UNSPEC; net_ctx.local_port = udp->source; net_ctx.remote_port = udp->dest; } else return TC_ACT_UNSPEC; net_ctx.pid = 0; net_ctx.ingress = ingress; net_ctx.packet_size = skb->len; net_ctx.ifindex = skb->ifindex; net_ctx.timestamp = bpf_ktime_get_ns(); const size_t pkt_size = sizeof(net_ctx); bpf_perf_event_output(skb, &eventMap, BPF_F_CURRENT_CPU, &net_ctx, pkt_size); if (type == ETH_P_IP) { const char fmt_str[] = "[eBPF tc] %s"; const char fmt_str_local[] = " local: %u:%d\t"; const char fmt_str_remote[] = "remote: %u:%d\n"; if (IPPROTO_UDP == net_ctx.protocol) { const char chproto[] = "UDP"; bpf_trace_printk(fmt_str, sizeof(fmt_str), chproto); } else if(IPPROTO_TCP == net_ctx.protocol){ const char chproto[] = "TCP"; bpf_trace_printk(fmt_str, sizeof(fmt_str), chproto); } else { const char chproto[] = "Unknown"; bpf_trace_printk(fmt_str, sizeof(fmt_str), chproto); } bpf_trace_printk(fmt_str_local, sizeof(fmt_str_local), net_ctx.local_address, net_ctx.local_port); bpf_trace_printk(fmt_str_remote, sizeof(fmt_str_remote), net_ctx.remote_address, net_ctx.remote_port); } return TC_ACT_UNSPEC;}; |
bpf_perf_event_output传输的类型有限制
1 2 | This helper writes a raw blob into a special BPF perf event held by of type BPF_MAP_TYPE_PERF_EVENT_ARRAYSee: https://docs.ebpf.io/linux/helper-function/bpf_perf_event_output/ |
如果只想方便调试和输出,可以使用bpf_trace_printk函数,fmt参数个数有限制,通过trace_pipe看输出的调试日志。
1 | cat /sys/kernel/debug/tracing/trace_pipe |
利用clang编译,生成traceEngin.ebpf.o文件,加载和调试tc
1 | clang -O2 -g -I "../../include" -target bpf -D__KERNEL__ -D__TARGET_ARCH_x86_64 -D__BPF_TRACING__ -D__linux__ -fno-stack-protector -c "${directory}traceEngin.c" -o "traceEngin.ebpf.o" |
tc需要绑定到网卡上,可以使用tc命令加载traceEngin.ebpf.o调试,步骤如下:
1 2 3 4 5 6 | version: tc utility, iproute2-5.15.0, libbpf 0.5.0tc qdisc add dev eth0 clsacttc filter add dev eth0 ingress bpf da obj traceEngin.ebpf.o sec tctc filter show dev eth0 ingresstc filter del dev eth0 ingress |
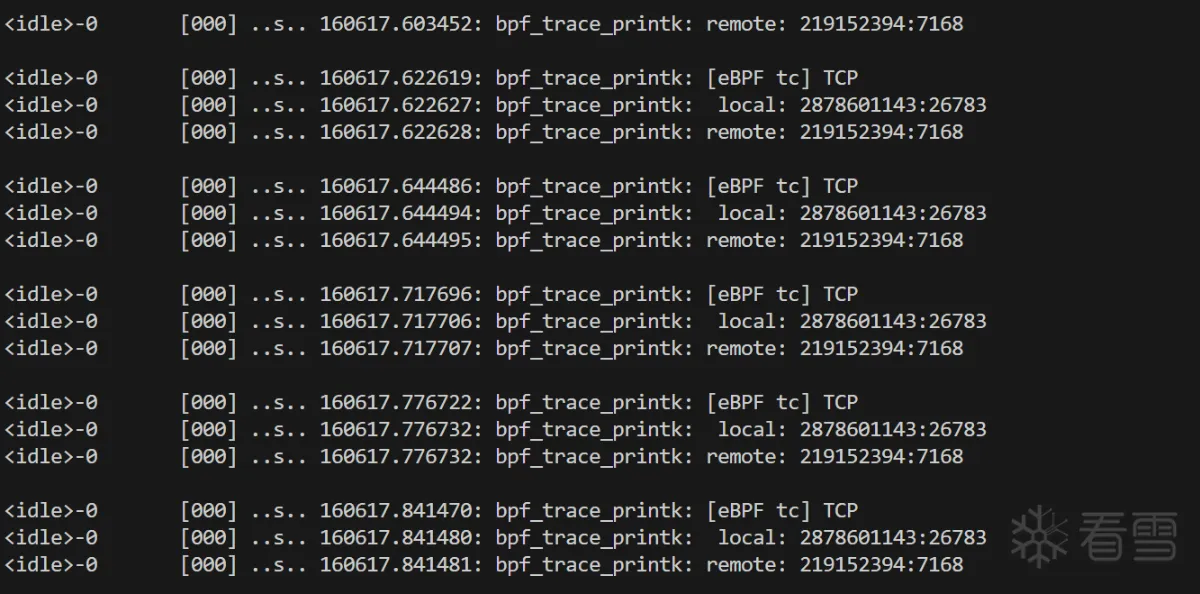
r3 Load eBPF
r0 eBPF编码完成后,应用层(推荐)使用skeleton方式加载,skeleton提供了用户空间应用层接口方法。
clang生成traceEngin.ebpf.o之后,使用bpftool gen skeleton .o文件生成skel.h,步骤如下:
1 2 3 4 5 | directory="/xxxxx/ebpfTracer/core/"clang -O2 -g -I "../../include" -target bpf -D__KERNEL__ -D__TARGET_ARCH_x86_64 -D__BPF_TRACING__ -D__linux__ -fno-stack-protector -c "${directory}traceEngin.c" -o "traceEngin.ebpf.o"bpftool gen skeleton "traceEngin.ebpf.o" name "traceEngin" > "traceEngin.skel.h"cp traceEngin.skel.h ../../includecp traceEngin.ebpf.o ../../lib |
traceEngin.skel.h文件如下,第三个struct定义Map和全局只读数据,第四个struct是SEC()定义的eBPF程序,第五个struct是eBPF Link。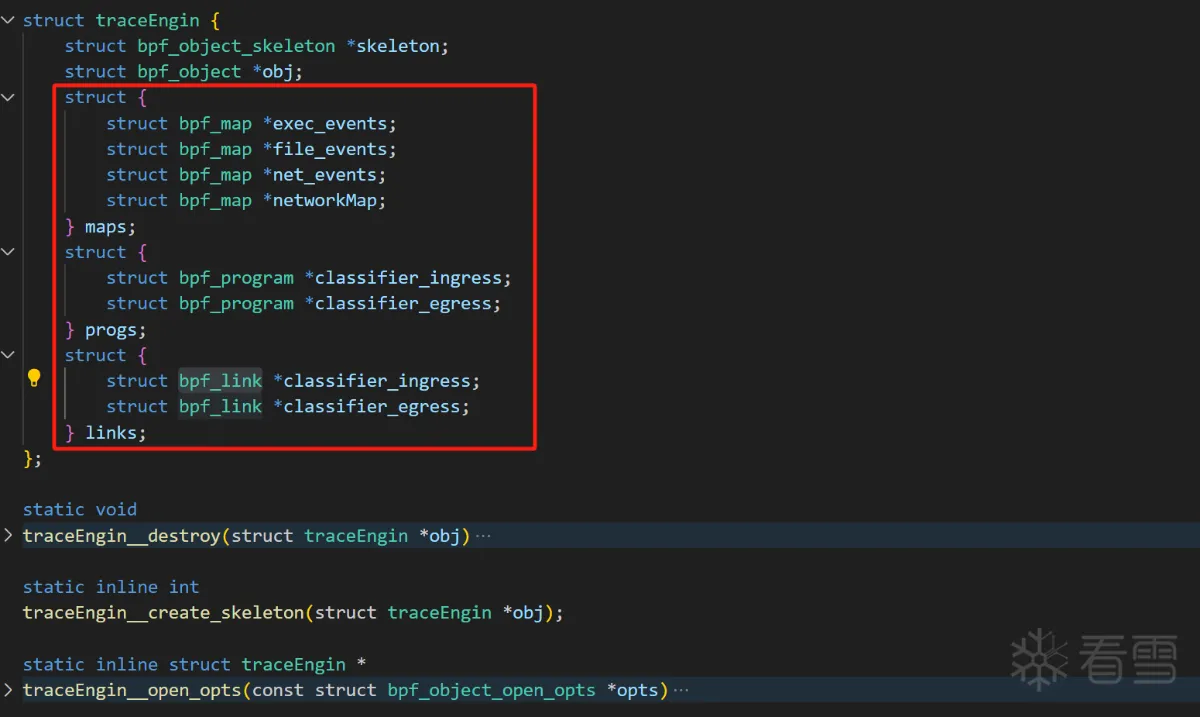
应用层加载eBPF traceEngin.skel.h,生命周期__open,__load,__attach,__destroy(销毁),RunRestrack()负责traceEngin.skel.h加载。
代码中设置libbpf_set_print(libbpf_print_fn),eBPF调试信息会被打印出来,加载或执行报错看输出日志。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #include "traceEngin.skel.h"int libbpf_print_fn(enum libbpf_print_level level, const char* format, va_list args){ return vfprintf(stderr, format, args);}const bool eBPFTraceEngine::RunRestrack(struct TraceEnginConfiguration* config){ if (!config) return false; if (config->bEnableBPF == false) return false; libbpf_set_print(libbpf_print_fn); SetMaxRLimit(); // Open the eBPF program m_skel = traceEngin__open(); if (!m_skel || (nullptr == m_skel)) return false; int ret = -1; ret = traceEngin__load(m_skel); if (ret) { traceEngin__destroy(m_skel); return false; } ret = traceEngin__attach(m_skel); if (ret) { traceEngin__destroy(m_skel); return false; } return true;} |
eBPF tc hook加载有点特殊,libbpf中有声明加载tc的方法。
1 2 3 4 5 6 7 8 | LIBBPF_API int bpf_tc_hook_create(struct bpf_tc_hook *hook);LIBBPF_API int bpf_tc_hook_destroy(struct bpf_tc_hook *hook);LIBBPF_API int bpf_tc_attach(const struct bpf_tc_hook *hook, struct bpf_tc_opts *opts);LIBBPF_API int bpf_tc_detach(const struct bpf_tc_hook *hook, const struct bpf_tc_opts *opts);LIBBPF_API int bpf_tc_query(const struct bpf_tc_hook *hook, struct bpf_tc_opts *opts); |
代码加载eBPF tc如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | DECLARE_LIBBPF_OPTS(bpf_tc_hook, hook);DECLARE_LIBBPF_OPTS(bpf_tc_opts, ops);hook.ifindex = 1;hook.attach_point = BPF_TC_INGRESS; // 填充方向// options从skel里面获取ops.prog_fd = bpf_program__fd(skel->progs.tc_ingress);ops.flags = BPF_TC_F_REPLACE// 创建tc hook bpf_tc_hook_create(&hook);int err = bpf_tc_attach(&hook, &ops);if (err) { printf("Cannot attach\n"); goto cleanup;}while(1) { work}// clearbpf_tc_hook_destroy(&hook); |
启动eBPF perfbuf消费队列,perf_buffer__new 和 perf_buffer__poll组合用法,per_buffer_new参数1是perf接收的map对象,也就是bpf_perf_event_output的第二个参数名。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | #include "bpf/libbpf.h"void perf_event(void* ctx, int cpu, void* data, __u32 data_sz){ // get perf buf buffer handle}void perf_lost_events(void* ctx, int cpu, __u64 lost_cnt){}void* eBPFMonitor::EbpfTraceEventThread(void* thread_args){ // struct TraceEnginConfiguration* config = (struct TraceEnginConfiguration*)thread_args; // if (!config || (config == nullptr)) // return nullptr; traceEngin* skel = (traceEngin*)SingleeBPFTraceEngine::instance()->GetSkel(); if (!skel || (skel == nullptr)) { return nullptr; } eBPFMonitor::m_pb = perf_buffer__new( bpf_map__fd(skel->maps.net_events), PERF_BUFFER_PAGES, perf_event, perf_lost_events, NULL, NULL ); if (!eBPFMonitor::m_pb || (nullptr == eBPFMonitor::m_pb)) { return nullptr; } int err = 0; while (1) { if (SingleeBPFMonitor::instance()->GetStopStu()) break; if (!eBPFMonitor::m_pb || (nullptr == eBPFMonitor::m_pb)) break; err = perf_buffer__poll(eBPFMonitor::m_pb, PERF_POLL_TIMEOUT_MS); if (err < 0 && err != -EINTR) break; err = 0; } if (eBPFMonitor::m_pb) { perf_buffer__free(eBPFMonitor::m_pb); eBPFMonitor::m_pb = nullptr; } // send single const int pid = getpid(); kill(pid, SIGINT); return nullptr;} |
应用层代码中需要处理SIGINT | SIGTERM信号,某些情况下应用程序中断,eBPF没被卸载,就会一直运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | void eBPFTraceEngine::StopRestrack(){ if (m_skel) { traceEngin__destroy(m_skel); m_skel = nullptr; }}void sighandler(int) { // clear SingleeBPFTraceEngine::instance()->StopRestrack(); SingleeBPFMonitor::instance()->StopMonitor(nullptr); SingleTaskHandler::instance()->StopTaskThread(); exit(0);}int main() { // regsiter signal clear bpf signal(SIGINT, sighandler); signal(SIGTERM, sighandler); return 0;} |
eBPF Socket API
kprobe/tcp_v4_rcv
kprobe/tcp_v4_rcv挂钩点L4传输层,rvc通常用来做流量的性能分析,可以记录流量开始和结束时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #include <bpf/bpf_tracing.h>SEC("kretprobe/tcp_v4_rcv")int tcp_v4_rcv_ret(struct pt_regs* ctx) { if (ctx == NULL || (!ctx)) return 0; do { struct sk_buff* skb = (struct sk_buff*)PT_REGS_PARM1(ctx); if (!skb || (skb == NULL)) break; // get skb info const u64 time = bpf_ktime_get_ns(); const int pid = bpf_get_current_pid_tgid() >> 32; const char fmt_str[] = "[eBPF kp] tcp v4 rcv pid %d time %llu.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid, time); } while (false); return 0;}SEC("kretprobe/tcp_v6_rcv")int tcp_v6_rcv_ret(struct pt_regs* ctx) { if (ctx == NULL || (!ctx)) return 0; do { struct sk_buff* skb = (struct sk_buff*)PT_REGS_PARM1(ctx); if (!skb || (skb == NULL)) break; // get skb info const u64 time = bpf_ktime_get_ns(); const int pid = bpf_get_current_pid_tgid() >> 32; const char fmt_str[] = "[eBPF kp] tcp v6 rcv pid %d time %llu.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid, time); } while (false); return 0;} |
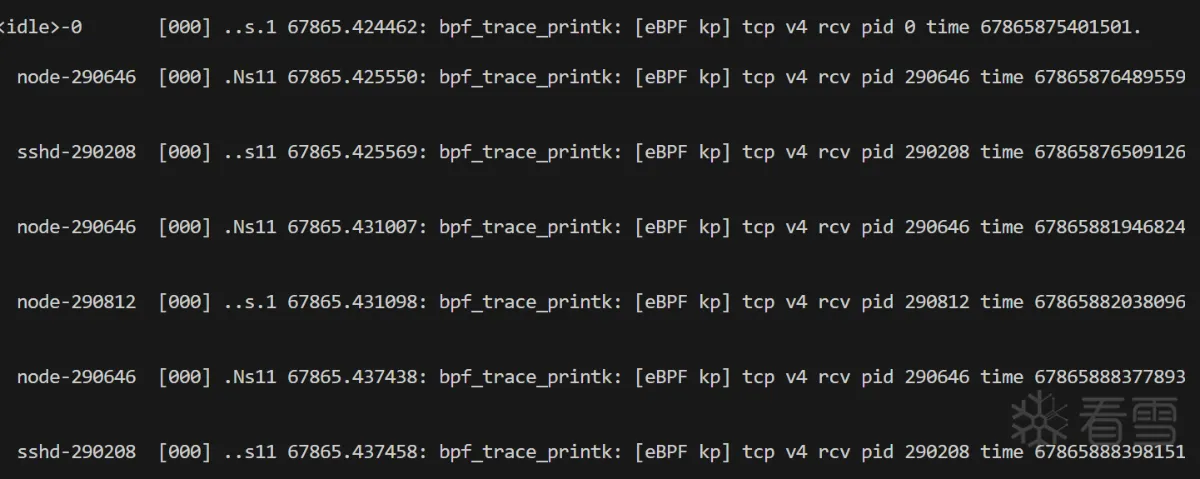
kprobe/ping_v4_sendmsg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | SEC("kprobe/ping_v4_sendmsg")int BPF_KPROBE(trace_ping_v4_sendmsg){ if(!ctx || (NULL==ctx)) return 0; struct network_ctx net_ctx = { 0, }; net_ctx.protocol = IPPROTO_ICMP; struct sock* sk = NULL; struct inet_sock* inet = NULL; struct msghdr* msg = NULL; struct sockaddr_in* addr = NULL; sk = (struct sock*)PT_REGS_PARM1(ctx); if(!sk || (NULL == sk)) return 0; inet = (struct inet_sock *) sk; if(!inet || (NULL == inet)) return 0; net_ctx.local_port = BPF_CORE_READ(inet, inet_sport); msg = (struct msghdr*)PT_REGS_PARM2(ctx); if (!msg || (NULL == msg)) return 0; addr = (struct sockaddr_in*)READ_KERN(msg->msg_name); if (!addr || (NULL == addr)) return 0; net_ctx.local_address = READ_KERN(addr->sin_addr).s_addr; const int pid = bpf_get_current_pid_tgid() >> 32; const char fmt_str[] = "[eBPF kp] ping v4 pid %d ping %u:%d.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid, net_ctx.local_address, net_ctx.local_port); return 0;} |
ping www.kanxue.com
1 2 3 4 | 64 bytes from 116.211.128.184 (116.211.128.184): icmp_seq=1 ttl=251 time=19.9 ms64 bytes from 116.211.128.184 (116.211.128.184): icmp_seq=2 ttl=251 time=20.0 ms64 bytes from 116.211.128.184 (116.211.128.184): icmp_seq=3 ttl=251 time=19.7 ms64 bytes from 116.211.128.184 (116.211.128.184): icmp_seq=4 ttl=251 time=20.1 m |
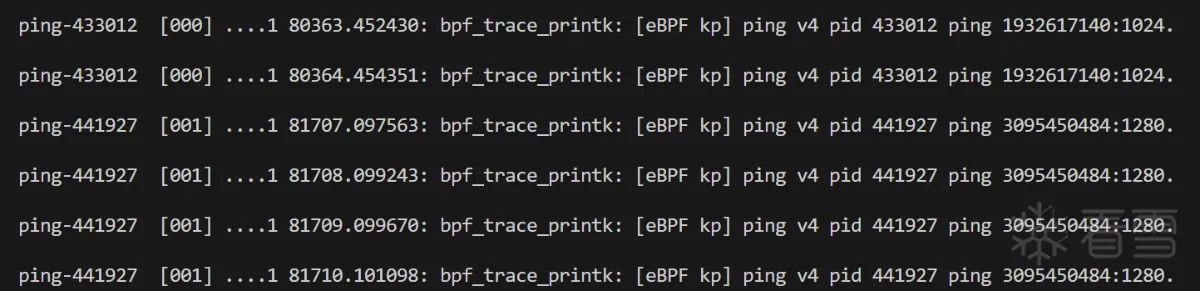
不一一举例,每个挂钩点传递上下文不同,数据和执行动作有区别,常见的eBPF Socke API挂钩点。
1 2 3 4 5 6 7 8 9 10 11 12 | SEC("tracepoint/syscalls/sys_enter_connect")SEC("tracepoint/syscalls/sys_exit_connect")SEC("kprobe/security_socket_bind")SEC("kprobe/tcp_v4_send_reset")SEC("kprobe/tcp_close")SEC("kretprobe/tcp_close")SEC("kprobe/ip_make_skb")SEC("kprobe/ip6_make_skb")SEC("kprobe/icmp_rcv")SEC("kprobe/icmp6_rcv")SEC("kprobe/udp_recvmsg")SEC("kretprobe/udp_recvmsg") |
Capture Process
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | SEC("tracepoint/syscalls/sys_enter_execve")int tp_syscalls_sysentrywrite(struct syscall_enter_args* ctx){ const int pid = bpf_get_current_pid_tgid() >> 32; const char fmt_str[] = "[eBPF sys_enter_execve] triggered from PID %d.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid); return 0;}SEC("tracepoint/syscalls/sys_exit_execve")int tp_sys_exit_execve(void* ctx){ const int pid = bpf_get_current_pid_tgid() >> 32; const char fmt_str[] = "[eBPF sys_exit_execve] triggered from PID %d.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid); return 0;}SEC("tracepoint/sched/sched_process_fork")int tp_sched_process_fork(struct trace_event_raw_sched_process_fork* ctx) { if (ctx == NULL || (!ctx)) return 0; const int pid = ctx->parent_pid; const char fmt_str[] = "[eBPF tp sched] process fork pid %d.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid); return 0;}SEC("tp/sched/sched_process_exit")int handle_exit(struct trace_event_raw_sched_process_template* ctx){ if (ctx == NULL || (!ctx)) return 0; struct task_struct* task = NULL; task = (struct task_struct*)bpf_get_current_task(); if (task == NULL || (!task)) return 0; const int pid = bpf_get_current_pid_tgid() >> 32; const int ppid = BPF_CORE_READ(task, real_parent, pid); const int exit_code = (BPF_CORE_READ(task, exit_code) >> 8) & 0xff; const char fmt_str[] = "[eBPF tp sched] process exit pid %d exitcode %d.\n"; bpf_trace_printk(fmt_str, sizeof(fmt_str), pid, exit_code); return 0;} |
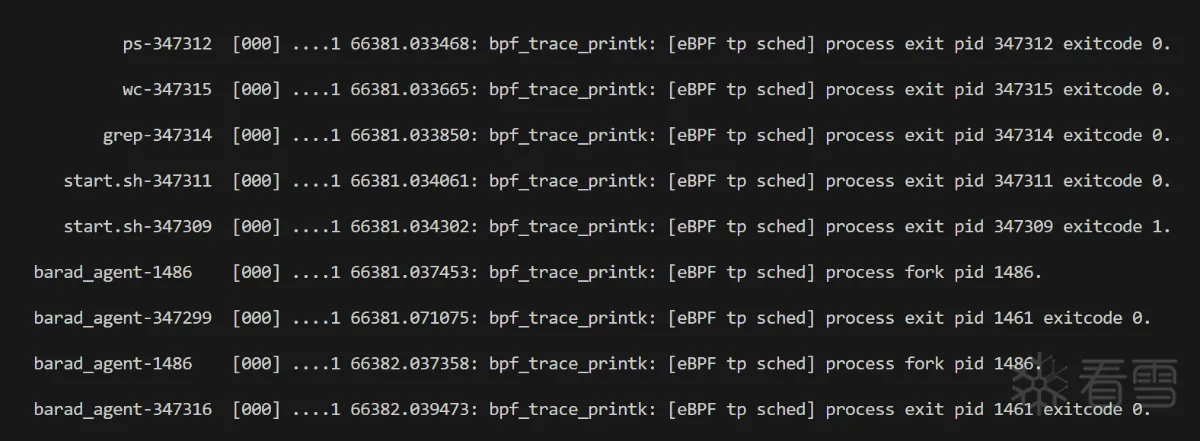
More Source
1 | https://github.com/TimelifeCzy/LibNetAndProxyEvent/tree/dev-ebpf/ebpfTracer & git checkout dev-ebpf |
1 | Hades eBPF Driver Source: https://github.com/chriskaliX/Hades/tree/main/plugins/edriver/bpf/include |
Issues
问题一:libc6依赖错误或找不到'bits/wordsize.h'
1 2 | /usr/include/x86_64-linux-gnu/gnu/stubs.h:7:11: fatal error: 'gnu/stubs-32.h' file not found# include <gnu/stubs-32.h> |
解决方案,看/usr/include/x86_64-linux-gnu具体有没有头文件,如果存在添加路径C编译即可。
1 2 | vim ~/.bashrc,最后添加C include的头文件引用路径export C_INCLUDE_PATH=/usr/include/x86_64-linux-gnu:$C_INCLUDE_PATH |
如果文件不存在,尝试安装libc6
1 | apt-get install libc6-dev libc6-dev-i386 |
问题二:clang有时候需要指定架构,代码中使用了PT_REGS_PARM宏,需要指定__TARGET_ARCH_xxx,否则编译报错如下:
1 2 3 4 5 6 | error: Must specify a BPF target arch via __TARGET_ARCH_xxx sk = (struct sock*)PT_REGS_PARM1(ctx);error: Must specify a BPF target arch via __TARGET_ARCH_xxx struct sk_buff* skb = (struct sk_buff*)PT_REGS_PARM2(ctx); GCC error "Must specify a BPF target arch via __TARGET_ARCH_xxx" |
解决方案,执行uname -m 查看 os arch, clang添加对应的架构,如x86|x86_64,可以传参-D__TARGET_ARCH_x86_64
1 | clang -O2 -g -I "../../include" -target bpf -D__KERNEL__ -D__TARGET_ARCH_x86_64 -D__BPF_TRACING__ -D__linux__ -fno-stack-protector -c "${directory}traceEngin.c" -o "traceEngin.ebpf.o" |
问题三:bpf_create_map_xattr错误
1 2 3 | libbpf: Error in bpf_create_map_xattr(exec_events):ERROR: strerror_r(-524)=22(-524). Retrying without BTF.libbpf: Error in bpf_create_map_xattr(file_events):ERROR: strerror_r(-524)=22(-524). Retrying without BTF.libbpf: Error in bpf_create_map_xattr(net_events):ERROR: strerror_r(-524)=22(-524). Retrying without BTF. |
先要排查key填充的数据, ARRAY map needs to have 4 - byte sized integer key.
1 | See: https://github.com/libbpf/libbpf-bootstrap/issues/209 |
也可以尝试下述定义方式解决问题
1 2 3 4 5 6 | struct { __uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY); __uint(key_size, sizeof(int)); __uint(value_size, sizeof(u32)); __uint(max_entries, 1024);} net_events SEC(".maps"); |
问题四:class doesn't support blocks
1 2 | Error: Class doesn't support blocks.We have an error talking to the kernel |
先执行tc qdisc add dev eth0 clsact
更多【编程技术-eBPF初学者编码实践】相关视频教程:www.yxfzedu.com
相关文章推荐
- 外文翻译-2022年,工业级EDR绕过蓝图 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-关于某ios版本分析 - 游戏逆向游戏开发编程技术加壳脱壳
- Pwn-祥云杯2022-leak Writeup - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术-加载了对应的调试符号文件也看不了函数名?也许是 fastlink 搞的鬼 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术-跨平台重构Cobaltstrike Beacon,行为对国内主流杀软免杀 - 游戏逆向游戏开发编程技术加壳脱壳
- 智能设备-关于thumb2指令下函数运行地址对齐问题及验证固件分析 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-某黑盒某请求参数分析 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全- 60秒学会用eBPF-BCC hook系统调用 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术-驱动保护-EAC内核调试检测分析 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-Android 系统源码下载编译刷机 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-编译frida16.0.2 python 模块 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-DASCTF X GFCTF 2022十月挑战赛 cuteRE WriteUp - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-攻防世界Mobile通关记录_apk逆向12_RememberOther_Ph0en1x-100_ill-intentions_wp - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:内核运用LoadImage屏蔽驱动 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-wibu证书 - 安全证书(一) - 游戏逆向游戏开发编程技术加壳脱壳
- 二进制漏洞-CVE-2018-17463详细分析及复现 - 游戏逆向游戏开发编程技术加壳脱壳
- CTF对抗-2022秋季赛题目提交 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-某当网apk加固脱个so - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-360ini.dll注入explorer技术分析 - 游戏逆向游戏开发编程技术加壳脱壳
- 二进制漏洞-CVE-2022-23613复现与漏洞利用可能性尝试 - 游戏逆向游戏开发编程技术加壳脱壳
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com