r语言-42 ajax 下载文件未配置 responseType blob 导致的文件异常
推荐 原创前言
这是一个最近的关于文件下载碰到的一个问题
主要的情况是, 基于 xhr 发送请求, 获取下载的文件
然后 之后 xhr 这边拿到 字节序列之后, 封装 blob 来进行下载
然后 最开始我们这边没有配置 responseType 为 blob, arraybuffer, 然后 导致下载出来的 文件大小超过了一倍,m 并且解压出现了问题
然后 增加了 responseType 配置为 blob 之后, 文件下载的功能就正常了
这里来大致看一下 大体的一个情况, 因为 xhr 这边具体的 编码 response, responseText, responseXml 的代码查看不了, 因此看不到 字节序列 转换为 字符串的过程, 因此 这里的结论仅仅是一个 大致的推导
另外 js 这边 new Blob 的具体的代码 也是查看不了, 因此 查看不了 字符串 转换为 字节序列 的这个过程
测试用例
客户端这边发送请求的 demo 代码如下
ajax({
method: 'post',
url: '/xxx/file/batchDownload',
data: data,
// responseType: 'arraybuffer'
}).then(res => {
let blob = new Blob([res], {type: "application/zip"});
const link = document.createElement("a");
link.download = 'file.zip';
link.style.display = "none";
link.href = URL.createObjectURL(blob);
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}).finally(() => {
this.setdownLoading(row, false)
})
正常的情况
如下是一个列表展示, 原始正确的 zip 文件大小为 811667 字节
// 原始文件大小
blob
811667
// 原始字节序列 使用给定的编码编码为字符序列, 然后再使用相同的编码解码为字节序列
new String(baos.toByteArray(), $charset).getBytes($charset)
gbk : 810632
utf8 : 1475674
// 前端 xhr 代码中不配置 responseType 为 arraybuffer/blob 的情况
xhr, without responseType blob, new Blob([res], {type: "application/zip"});
1476964
服务器这边响应的正常的 zip 文件大小如下, 是正确的, 可以正常打开
然后 我们看一下 正常的情况, 即 ajax 增加 responseType 为 blob/arraybuffer 的情况
这里是 axios 中的基于 xhr 的一个适配器, 这里是具体的基于 XmlHttpRequest 发送请求的地方
我们可以看到 response 为 blob, 然后 字节数为 811667 拿到的是正常的数据
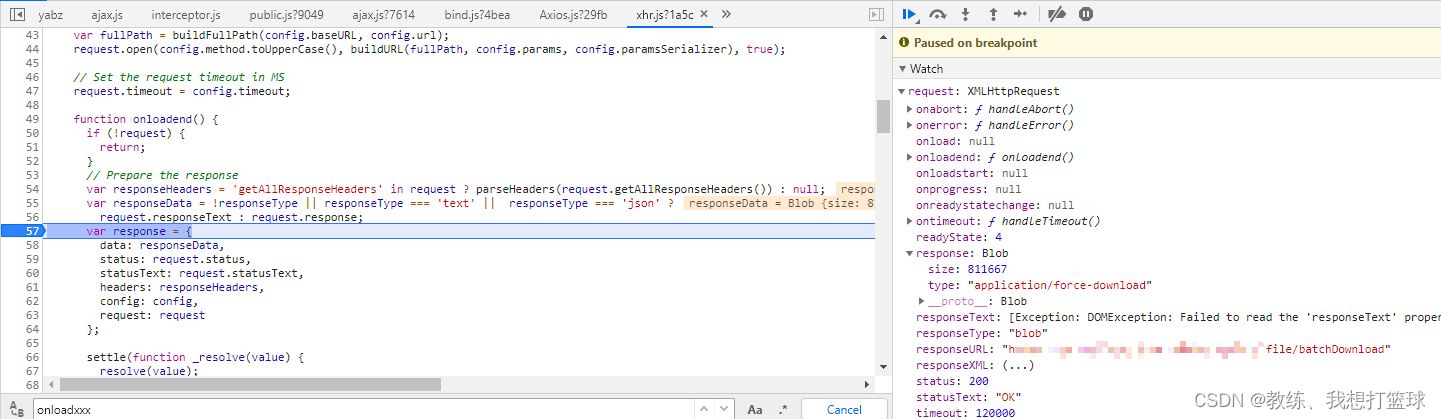
然后 进而再外层 业务 handle 处理的时候 也是拿到的正确的数据
然后 最终下载的压缩包, 正常

异常的情况
然后 这里可以看到的是 responseData 是一个字符串, 说明 他已经被转换过了
因为 服务器那边传输的是原始的字节序列, 然后 这里被转换过了之后 可能会造成 字节序列 的数据丢失, 错误
可以看到 这里数据大小是 1.5M 大概是原始数据的两倍, 字节转字符的编码可能是 gbk 或者 utf8

然后 业务这边再根据 字符串传唤为字节序列, 存放到 blob, 拿到的也是一个错误的数据
可以看到这里数据量大小为 1476944 和上面表格统计的大小基本一致, 之所以说基本一致, 是因为多次下载 会有少许不同, 大小差距在 20字节左右

所以 综上问题就在于在这个 字节序列 转 字符序列 再转 字节序列 的过程中造成了数据的错误
这个过程 会经过两次字符编码体系的处理
- 如果这两次都是 相同的单字节编码, 那么不会出现问题
- 如果是两次都是 相同的多字节编码 则可能存在问题, 因为 目标字节序列 可能未必复合目标编码的格式约束, 然后 造成了数据的不可逆丢失
- 如果是两次是 不同的编码, 并且存在兼容的 codepoint, 而且 字节序列 中的数据均在这些兼容的 codepoint 范围内, 则不会出现问题, 否则 会出现数据错误
但是 目标字节序列, 是 zip 格式, 任何一个字节的错误 都可能造成整体文件 不符合 zip 的规范, 或者 最开始 验签的时候 就校验不通过
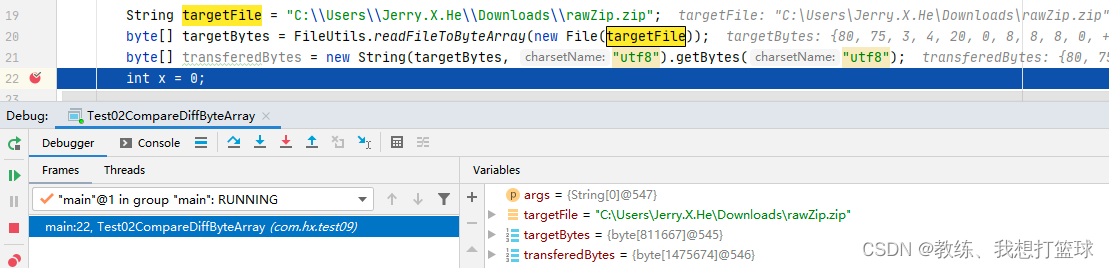
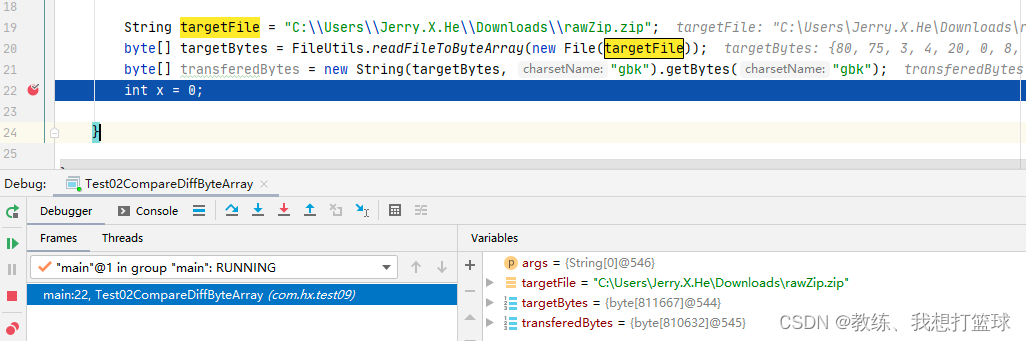
字节序列 使用 utf8编码转换为字符串, 然后再依据utf8编码转换为字节序列, 数据会不会丢失?
// 原始文件大小
blob
811667
// 原始字节序列 使用给定的编码编码为字符序列, 然后再使用相同的编码解码为字节序列
new String(baos.toByteArray(), $charset).getBytes($charset)
gbk : 810632
utf8 : 1475674
这里我们先来看下 这里例子中的文件的情况, 这里就解释了 不配置 responseType 为 arraybuffer/blob 的情况下下载出来的数据是错误的问题
使用 utf8 的时候, 整个过程最终结果的字节序列长度为 1475674
使用 gbk 的时候, 整个过程最终结果的字节序列长度为 810632
然后 我们这里来看拿一下 上面的转换之后, 什么情况下 数据会丢失? 什么情况下 数据不丢失?
如果 字节序列是满足 utf8 的编码规范, 则数据不会丢失, 否则 可能会有数据丢失
比如这里是原始字节序列 不满足 utf8 的编码规范, 然后 造成了数据的丢失, 原始 仅仅有 6 个字节, 转换之后却有 18 个字节, 并且 数据还存在错误
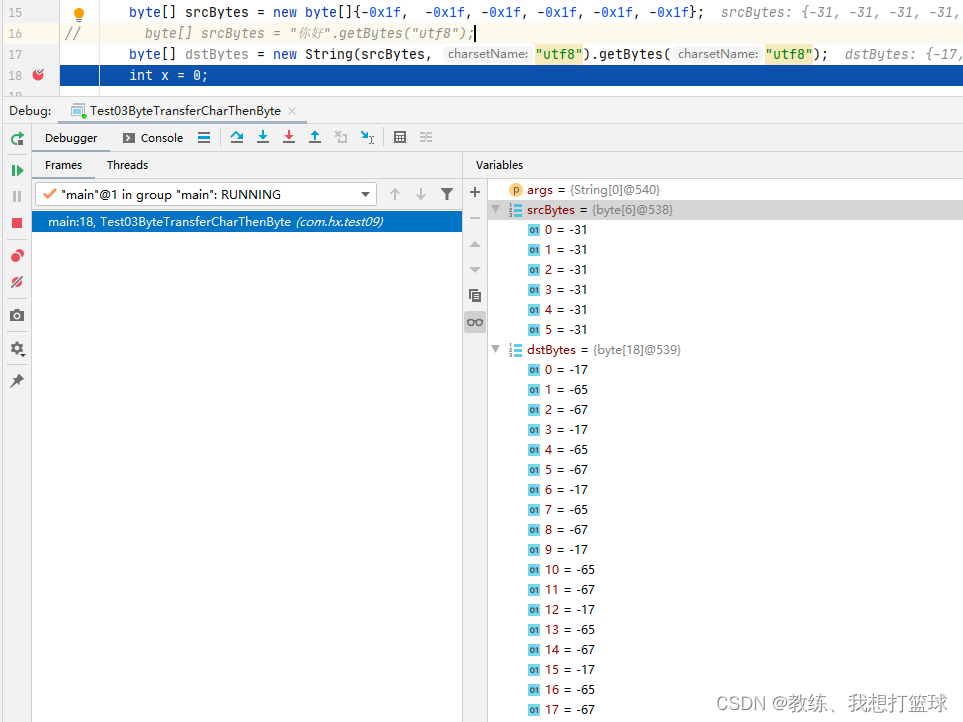
比如这里是原始字节序列 满足 utf8 的编码规范, 然后 可以看到的是 原始字节序列 和 目标字节序列 是相同的
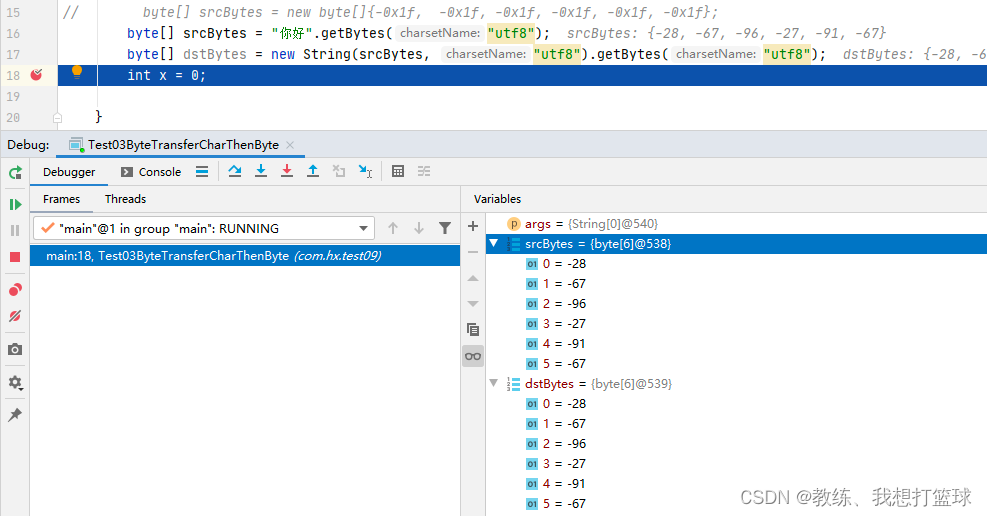
但是我们的目标文件是一个 zip 格式的二进制文件, 我们不能确保它的字节序列满足 固定的字符编码[假设浏览器这边是以 utf8 进行编码解码]
所以 如果是存在一个这个转换过程的话, 是可能存在 字节序列的数据的错误, 丢失
进而 导致 下载下来的文件, zip 解压缩软件 识别出错
完
更多【r语言-42 ajax 下载文件未配置 responseType blob 导致的文件异常】相关视频教程:www.yxfzedu.com
相关文章推荐
- hive-大数据毕业设计选题推荐-智慧消防大数据平台-Hadoop-Spark-Hive - 其他
- python-【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练 - 其他
- 编辑器-Linux编辑器---vim的使用 - 其他
- 矩阵-软文推广中媒体矩阵的优势在哪儿 - 其他
- 运维-CentOS 中启动 Jar 包 - 其他
- c#-C#中Linq AsEnumeralbe、DefaultEmpty和Empty的使用 - 其他
- jvm-JVM关键指标监控(调优) - 其他
- 编程技术-JavaScript + setInterval实现简易数据轮播效果 - 其他
- 编程技术-Datawhale智能汽车AI挑战赛 - 其他
- 编程技术-针对CSP-J/S的每日一练:Day 6 - 其他
- 编程技术-【vue实战项目】通用管理系统:api封装、404页 - 其他
- 云计算-软考 系统架构设计师系列知识点之云计算(3) - 其他
- 编程技术-排查Windows内存泄漏问题的详细记录 - 其他
- pdf-ReportLab创建合同PDF - 其他
- 编程技术-应用协议安全:Rsync-common 未授权访问. - 其他
- 编程技术-十九章总结 - 其他
- 编程技术-实用干货丨Eolink Apikit 配置和告警规则的各种用法 - 其他
- 系统架构-垂直领域对话系统架构 - 其他
- python-pycharm pro v2023.2.4(Python编辑开发) - 其他
- 云原生-修炼k8s+flink+hdfs+dlink(七:flinkcdc) - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com