科技-奇富科技:大数据任务从诊断到自愈的实践之路
推荐 原创一、为什么要做诊断引擎
毓数平台是奇富科技公司自主研发的一站式大数据管理、开发、分析平台,覆盖大数据资产管理、数据开发及任务调度、自助分析及可视化、统一指标管理等多个数据生命周期流程,让用户使用数据的同时,挖掘数据最大的价值。而毓数平台的大数据任务调度底层是基于Apache DolphinScheduler实现的。
整个大数据平台有1000+机器、几十P数据量,每日新增200T数据。每天在毓数工作流上运行的任务实例有20万+,周活跃用户500+;运行的任务类型有Spark任务、Sqoop任务、DataX任务等10多种任务类型。
而我们的几百位业务同学对大数据框架底层原理几乎都不太了解,因此日常会需要数据平台部门同学协助业务去分析和排查大数据任务运行问题。数据平台部门同学每天都会花费很多时间和精力在任务人工诊断上,而相应业务同学面对异常任务也会很苦恼。每个月数据平台部门协助用户诊断任务问题平均耗费4人/天工时。
对于,异常任务,让我印象很深刻的一件事情是,23年有一位业务同学在群里询问他的sql为啥报错。将业务的Sql简写后异常如下图所示。
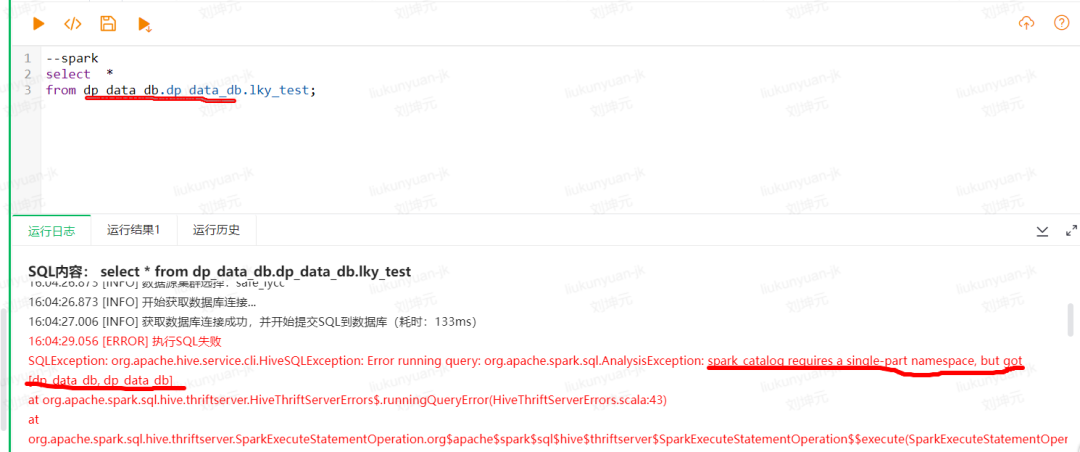
然后过了几分钟另外一个业务同学在群里回复他说:“你多写了一个库名”。这个现象让我发现,虽然我们数据平台的同学认为这个问题很简单,很容易排查。但是当业务的sql比较复杂并且业务对写sql不太熟悉时,就会经常被异常困扰几分钟甚至更长时间,不能快速解决sql的异常。
而且sql语法异常可能大家排查和解决比较简单,而spark sql的数据倾斜、数据膨胀、OOM等异常需要业务登录spark ui去排查。这样对业务简直就太困难了,因此我们决定做一款面向自助查询和工作流的大数据任务实时诊断引擎。
二、诊断引擎需求分析
(一)、诊断所有大数据任务
我们理想中诊断引擎必须支持毓数平台中运行的所有大数据任务。前面我们说过,我们工作流有Spark任务、Sqoop任务、DataX任务等10多种任务类型;而自助查询支持mysql、tidb、doris、tidb、spark等数据源查询。因此诊断引擎必须能够对所有大数据任务进行诊断。
(二)、实时看见诊断结果
诊断引擎必须实时产出诊断报告,我们不太能接受用户看见了异常点击诊断按钮,然后旋转几圈才能看见诊断报告(也可能看不见报告)。也不能接受用户需要从A平台跳转到B平台去看诊断报告。
用武侠小说里的一句话,“毒蛇出没之处,七步之内必有解药”。必须让用户在看见异常1秒钟内看见所对应的诊断报告。让用户使用毓数平台的诊断体验达到最好。
其次,通过自助查询提交的Spark任务虽然还在运行中,没有失败,但是从Spark指标或者日志中已经发现了数据倾斜、数据膨胀、OOM等。也应该在任务提交处,及时弹出诊断报告。达到任务还没有失败时,诊断报告已经产出。最终实现异常与诊断报告实时产出。
(三)、诊断规则易扩展
诊断引擎的诊断规则新增流程必须快速,不能通过发版的方式,例如每周发布一次。如果诊断规则,每周发布一次,对于我们快速帮助业务解决问题而言,太慢了。
因此,我们对于诊断规则发布和生效要求在分钟级。开发、测试好后的诊断规则在1分钟内就能发布到生产环境进行诊断。
(四)、诊断规则灰度发布
诊断引擎的诊断规则必须支持灰度发布,在生产环境运行一段时间后,效果评估没有问题后,用户才能在任务提交入口处看见诊断报告。
(五)、支持阈值实时调整
比如我们的诊断规则有Spark大任务、Spark 小文件。那么多少Spark的task达到多少阈值才算命中Spark大任务?平均写出HDFS多少字节算是小文件?这些阈值可以脱离诊断规则,配置在常量表中。同样修改这些阈值配置,支持分钟级生效。
三、诊断引擎架构剖析
(一)、大数据任务提交入口
诊断元数据采集的入口有工作流、自助查询,但是未来也不排除需要支持Linux客户端、Jupyter等提交任务入口。
(二)、大数据诊断元数据类型
需要支持的大数据诊断元数据有log、metrics,未来也不排除支持Trace等数据。
(三)、诊断引擎架构
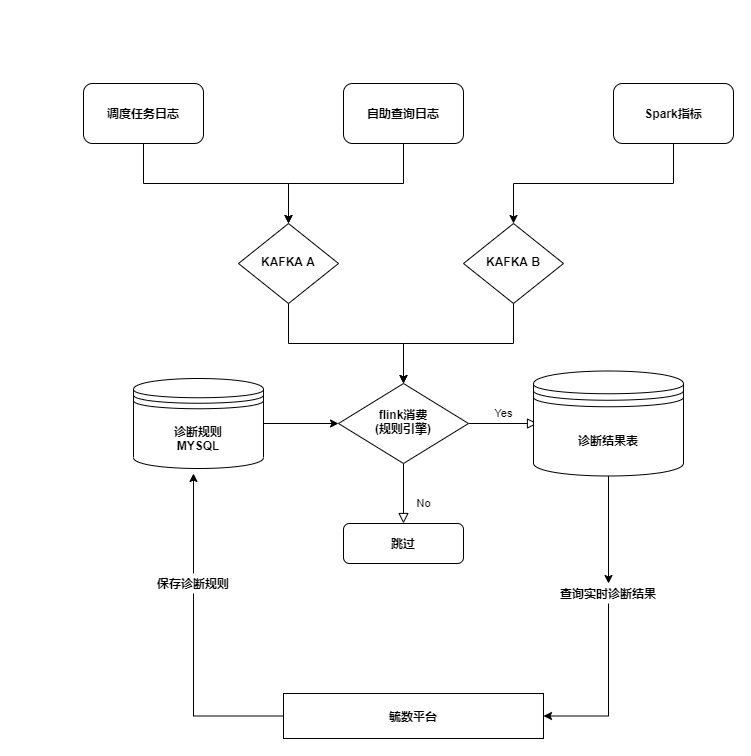
以下是我们诊断引擎架构图,我们会实时收集Apache DolphinScheduler worker上所有任务产生的日志到Kafka中。
我们也会和我司自研的自助查询系统合作,自助查询系统也会实时发送用户提交任务的日志到Kafka中。其次,我们重写了Spark的metric sink,实现将运行的Spark任务metric实时发送到kafka中。
我们自研了一个基于Flink和Janino的规则引擎,通过Flink消费Kafka的数据,并对数据进行实时诊断。而Flink引擎每隔1分钟会将存在mysql中新增的java代码交给Janino编译成字节码,从而实现了规则实时加载和实时生效。
规则引擎实时加载规则,并对kafka中的数据进行实时诊断,将诊断结果写入mysql中。而工作流或者自助查询系统调用接口查询mysql中是否有诊断报告,并对用户展示诊断报告。
(四)、诊断引擎与开源对比
以下是我司自研的大数据诊断引擎与OPPO开源的罗盘对比。我觉得我们的诊断引擎在易用性、实时性,规则灰度、任务自愈、大数据任务类型等方面是优于罗盘的。不过我们在诊断规则深度方面还不如罗盘,比如Spark CPU浪费、内存浪费等方面,我们还没有开发规则。
不过后续,我们也可以实现这些资源浪费规则,目前精力主要做的是异常覆盖率提升、还有调度自愈等。
OPPO罗盘:https://github.com/cubefs/compass
四、诊断引擎实现
一)任务元数据采集
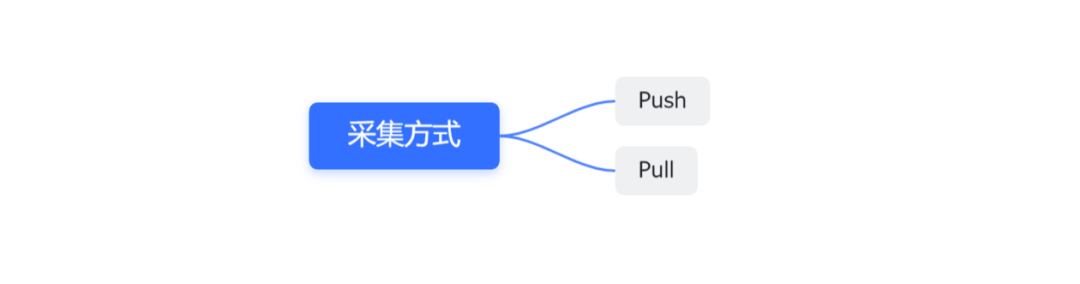
Push:有侵入性、运维简单、容易丢数据、适应性好。一般适用于任务类采集。
Pull:没有侵入性、运维复杂、不容易丢数据、适应性差。一般适用于服务类采集。
在对工作流任务运行的log采集上,我们采用了push方式主动上报任务运行日志到kafka中。
不采用pull方式的原因是,worker上运行的任务log写到了磁盘很多个文件中,而通过filebeat等方式采集磁盘log文件很难实现。
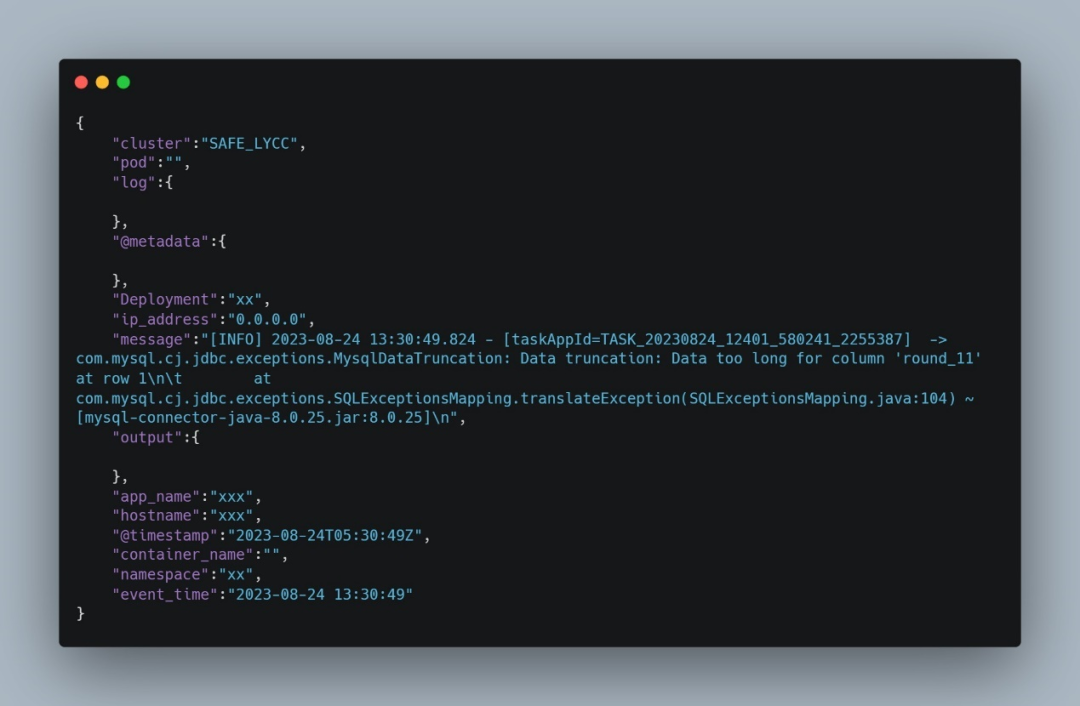
在这里,可以将taskAppId理解为分布式跟踪中的TraceId,每条log都需要携带一条TraceId,通过TraceId和工作流或者自助查询等关联起来。
对自助查询也是,自助查询提交的sql运行的日志也会实时push到kafka中。通过解析自助查询发送到kafka中log携带的TaskAppId,就能关联到自助查询每个Query的唯一的ID。
而采集Spark运行的指标,因为我们要做到实时诊断,因此没有采集Spark history的数据,而是实现一个spark metric kafka sink。这样随着启动Spark任务,便会将Spark任务运行的metric实时上报到kafka中。
以上是Spark的metric上报的部分指标,发现数据无法满足我们诊断需求。而我们需要的是Spark UI中展示的metric数据。

通过分析知道,既然Spark UI可以展示这些指标,那么这些指标必然存在Spark Driver中,只要我们从Driver中拿到这些指标就能发送到Kafka中了。后来我们从Spark源码中知道,Spark UI展示的这些metric存在于AppStatusStore数据结构中。因此我们从AppStatusStore中获取指标,并发送到kafka中。 "app_name":"SPARK_METRIC", "sparkMetricReportVersion":"v2", "applicationUser":"xx", "dataCenter":"xx", "ip_address":"xx", "metrics":[ { "metric":{ "shufflerecordsWritten":10353530, "taskKey":100, "localBytesRead":0, "attempt":0, "duration":3900003, "executorDeserializeCpuTime":5917691, "shufflewriteTime":0, "resultSize":4480, "host":"xx", "peakExecutionMemory":2228224, "recordsWritten":0, "remoteBlocksFetched":0, "stageId":1, "bytesWritten":0, "jvmGcTime":0, "remoteBytesRead":3221225479, "executorCpuTime":16868539, "executorDeserializeTime":5, "memoryBytesSpilled":0, "executorRunTime":16, "fetchWaitTime":0, "errorMessage":"", "recordsRead":0, "shuffleRecordsRead":1035353, "bytesRead":0, "remoteBytesReadToDisk":0, "diskBytesSpilled":0, "shufflebytesWritten":32212254, "speculative":false, "jobId":0, "launchTime":1692783512714, "localBlocksFetched":0, "resultSerializationTime":0, "name":"task", "taskId":100, "status":"SUCCESS" } } ], "application_id":"application_1692703487691_0205", "event_time":1692783655749, "applicationName":"xx", "sparkVersion":"3.3.2"
(二)为何选择Janino
Janino是一个超小、超快的开源Java 编译器。Janino不仅可以像javac一样将一组Java源文件编译成一组字节码class文件,还可以在内存中编译Java表达式、代码块、类和.java文件,加载字节码并直接在JVM中执行。而我们可以通过Janino动态编译java代码,从而实现一个轻量级规则引擎。
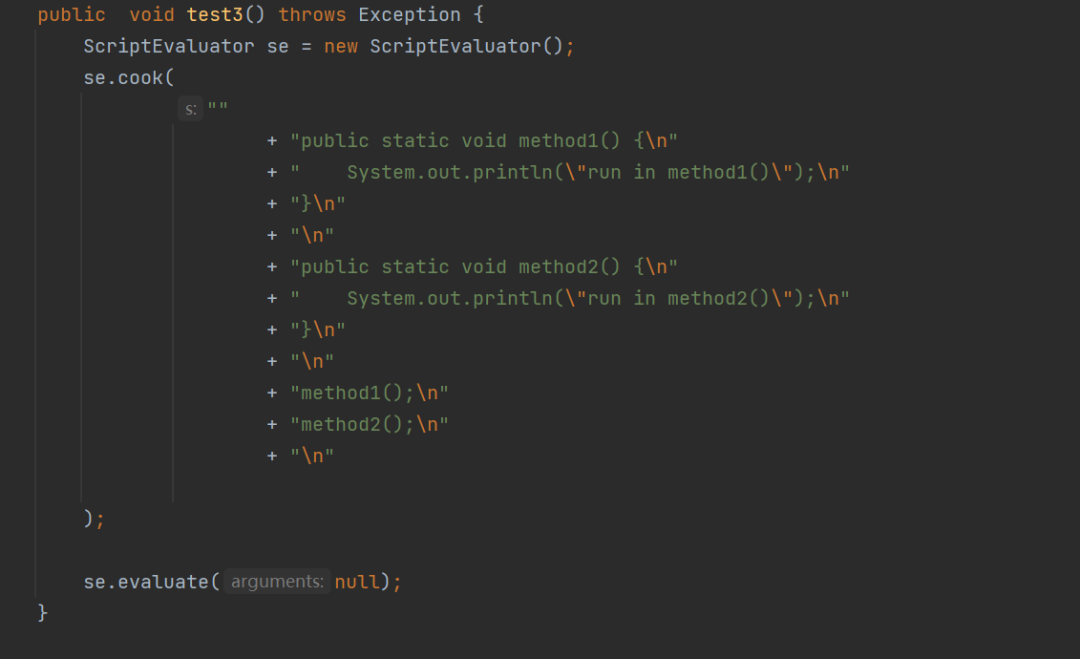
这样,规则代码就可以存放到mysql中,实现诊断规则动态加载。不过,需要注意的是,诊断规则编译这些java字符串代码时,需要md5存map中,通过md5值判断是否已经编译过,防止重复编译,否则Flink运行一段时间,就会OOM。
(三)诊断数据模型设计
对于诊断引擎数据模型应该怎样设计呢?我首先想到的是大数据任务诊断类似于医院体检。
我们想象一下现实中,我们是如何体检的。首先,医生会采集体检对象的血液、身高、体重、X光检测等。这些采集到的数据,对应诊断系统中的metric指标,例如shuffle条数、gc耗时等。医生还会询问我们是否熬夜,最近是不是有哪里不舒服。我们会回答,没有不舒服的地方或者我胃不太舒服。而“胃不太舒服”就是对应诊断系统中的log。医生拿到指标和log后,会根据metric和log以及医生的诊断经验(诊断规则)生成诊断报告。而诊断报告有几个要素:疾病名字、疾病描述、命中的metric或者log、结论、药方。
- **病类型**
病类型表:存储疾病类型,例如胃病;疾病描述,例如此病会影响食欲甚至危急生命。对应诊断引擎就是“语法错误”、“数据倾斜”等。
- **药方**
优化建议表:存储了这个疾病通用的优化规则,例如应该吃什么药。对应诊断引擎就是“如何调整spark参数”、“在写库名时,不小心写成了 库名.库名.表名,这种情况下需要改写为 库名.表名”等。
- **诊断规则**
诊断规则表:存储了诊断规则,例如如何看X光机拍摄的照片,或者分析抽血得到血液指标等。对应诊断引擎中java代码部分,运行诊断规则会生成诊断结论。
- **诊断结论**
诊断结论表:存储了运行诊断规则得到的结论。我得了胃病,严不严重,并能关联到药方。
对应诊断引擎就是运行java代码时分析metric或者log得到疾病类型、生成结论,并关联诊断建议(药方)。
- **常量表**
常量表:常量表存储了诊断规则需要用到的一些阈值。例如高血压值是多少,低血压值是多少?对于诊断引擎就是数据倾斜多少倍数算倾斜?数据膨胀多少倍算是膨胀?平均字节数多少算是小文件?为什么不把阈值放诊断规则里呢?是因为考虑到诊断规则是多变的,因此把常用阈值放入常量表中,这样就不用修改诊断规则java代码就可以调整诊断逻辑了。
五、大数据任务诊断应用
(一)诊断效果概览
1、诊断引擎生产应用情况
我们共开发了55条基于log或者metric的诊断规则,每天诊断的log条数约为7500万条,每天对log诊断次数约为36亿次;每天诊断的metric条数约为440万条,每天对metric诊断次数约为2640万次;每天生成的5.5万份诊断报告。
自从我们2023年10月份在工作流和自助查询上线了诊断引擎之后,平均减少了数据平台协助用户排查问题0.5人/天工时,工作流异常诊断覆盖率达到了85%,自助查询异常诊断覆盖率达到了88%,用户在服务群中询问问题的次数明显减少。
2、工作流失败任务诊断效果
以某日工作流诊断效果来看,工作流排除了依赖失败,共有2400多个失败任务。其中354个失败任务没有诊断报告,2062个失败任务生成了诊断报告,失败任务诊断报告命中率85.35%。
3、工作流成功任务诊断效果
诊断引擎是根据log和metric进行诊断,因此是没有区分成功任务还是失败任务。因此可以根据诊断命中情况对成功任务在未来运行情况进行预测。虽然任务运行成功了,如果任务发生了内存溢出、数据倾斜、数据膨胀等,可能也需要用户去关注。
还有一种情况是,数据质量的弱校验规则,数据质量比对没有通过。因为是弱数据质量规则,并不会导致任务失败,不过也需要提示出来。还有“同步0记录”诊断规则,比如DataX将Hive表数据同步到Mysql时,如果同步了0条数据,虽然同步任务成功了,我们也会在工作流页面提示出来。
4、自助查询失败任务诊断效果
自助查询失败的任务当日有2694个,而生成了诊断报告的失败任务有2378个,诊断命中率88.27%。业务在自助查询平台中提交的sql是在做探索性分析,大部分失败是语法错误,也是合理的。
(二)同步异常规则
诊断规则通过字符串匹配DataX抛出的异常日志判断是否命中。工作流在展示工作流实例时查询诊断命中表,并展示诊断结果。用户点击诊断结果会跳转到诊断报告。
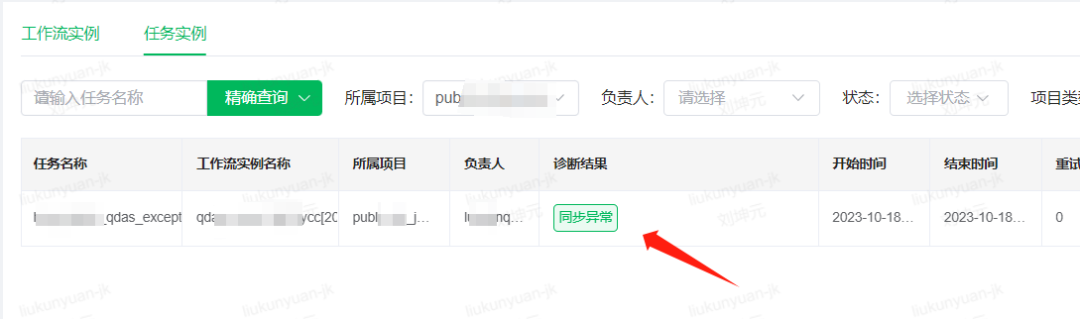
在诊断报告中会展示病症大类、ID(application_id)、病症描述、病症发生时间、命中的关键日志或者指标、病症结论以及诊断建议(药方)。比如在这个诊断建议中,就说明“数据同步,目前只支持orc格式,请创建orc格式的hive表”,用户就明白可以将自己的Hive表格式转为orc格式解决这个异常。
通过这种方式,用户在查询工作流实例时,在看见实例失败的1秒钟内,就能找到诊断报告去解决这个异常问题,实现了“七步之内必有解药”。

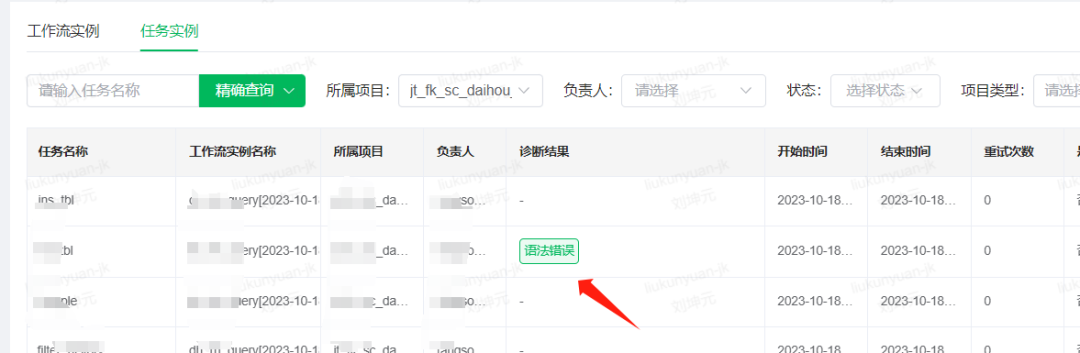
(三)语法错误规则
语法错误在自助查询平台和工作流中都是很常见的异常,特别是自助查询平台提交的任务语法错误情况会非常多。因此语法错误这个异常大类会对应很多诊断规则,属于一对多的情况。
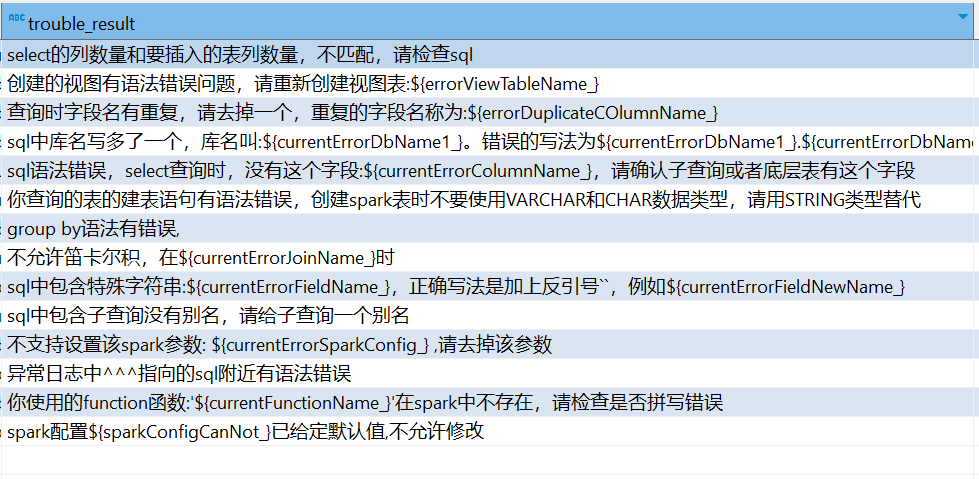
比如以Spark中查询的字段列数量和和插入表的列数量不匹配这个情况举例。我们在诊断规则中匹配“requires that the data to be inserted have the same number of columns as the target table”,如果log中出现了这个字符串,将会命中我们的诊断规则。 

语法错误更多是发生在自助查询中,以让我印象很深刻的sql语句中多写了一个库名举例,我们现在也实现了在发生这种情况时自动弹出“毓智AI专家”按钮。业务点击按钮就可以看见这个异常对应的诊断报告和结论:“sql中库名写多了一个,库名叫:dp_data_db。错误的写法为dp_data_db.dp_data_db.。正确的库名写法为:dp_data_db.”。
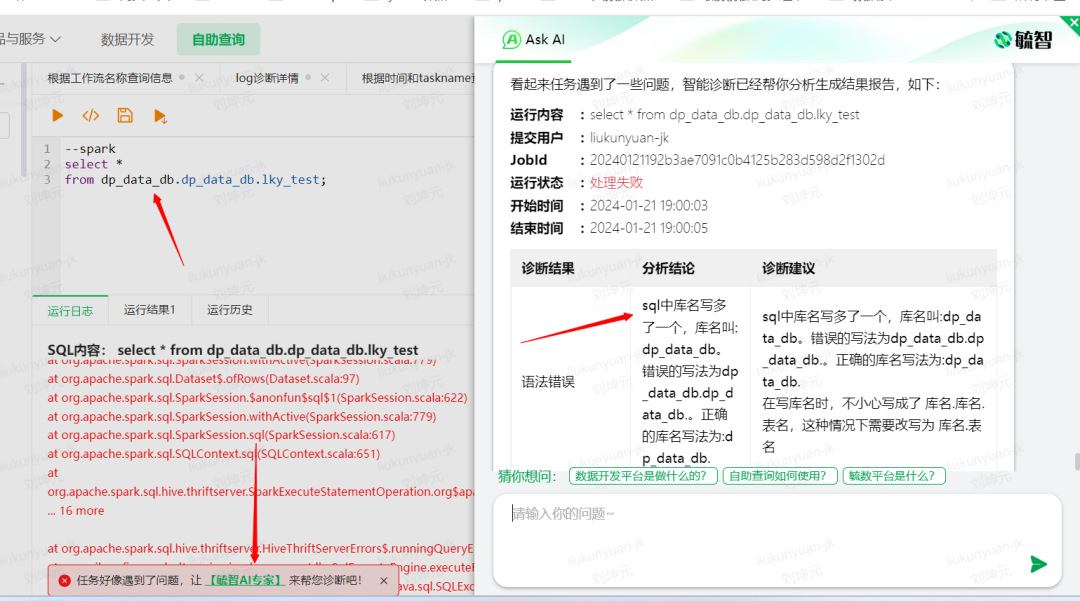
同样原理,我们在诊断规则中,通过多关键字匹配log,并从log中正则匹配出多写的库名。这样我们诊断结论能精确给出用户多写了哪一个库名。
同样,我们再以group by和select 字段不匹配这个语法异常说明。当group by后面缺少biz_type时,spark会抛出异常。
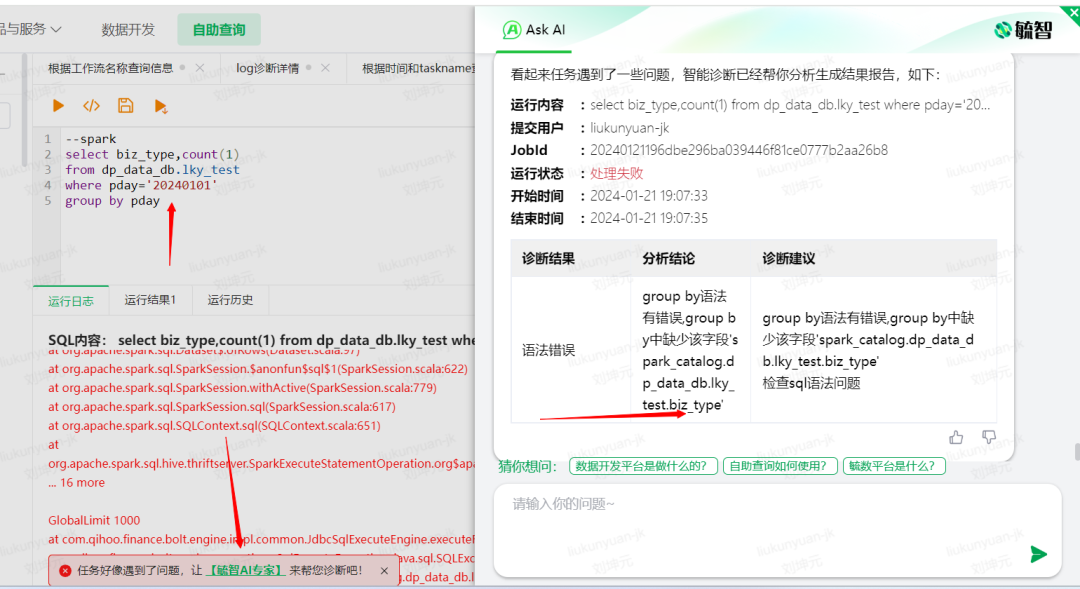
 而用户点击诊断按钮,会看见我们诊断引擎给出的诊断报告:“group by语法有错误,group by中缺少该字段'spark_catalog.dp_data_db.lky_test.biz_type'”。在sql语句非常复杂时,该诊断能让用户快速定位语法错误问题。
而用户点击诊断按钮,会看见我们诊断引擎给出的诊断报告:“group by语法有错误,group by中缺少该字段'spark_catalog.dp_data_db.lky_test.biz_type'”。在sql语句非常复杂时,该诊断能让用户快速定位语法错误问题。
我们暂时只实现了14种“语法错误”诊断规则,后续还可以继续覆盖语法异常情况。
(四)内存溢出规则
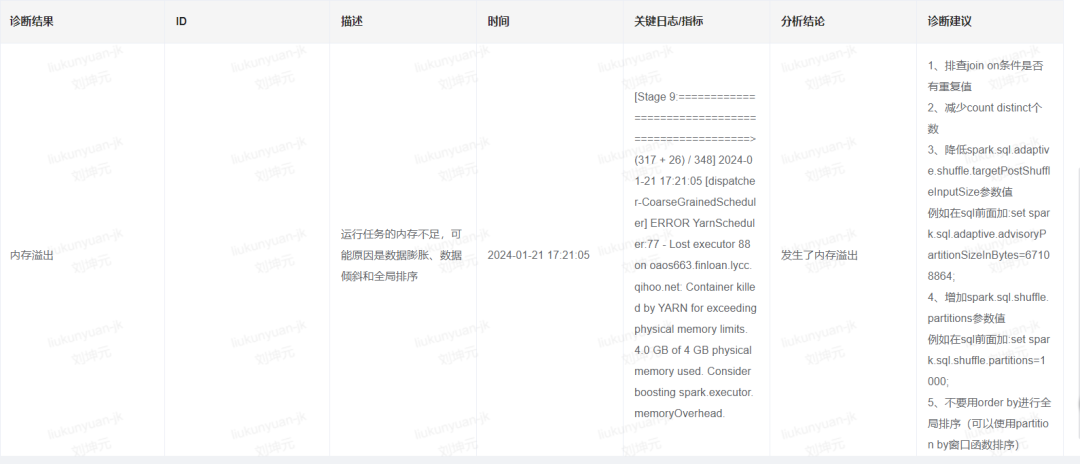
Spark运行经常会遇到内存溢出,而我们也通过诊断规则判断log或者metric中是否有内存溢出相关关键字判断是否发生了内存溢出。
我们对“内存溢出”这种情况,我们会给一下spark参数调优建议,例如“降低spark.sql.adaptive.shuffle.targetPostShuffleInputSize参数值.例如在sql前面加:set spark.sql.adaptive.advisoryPartitionSizeInBytes=67108864;”,或者“增加spark.sql.shuffle.partitions参数值.例如在sql前面加:set spark.sql.shuffle.partitions=1000;”等。
用户根据诊断建议,也多次解决了spark的内存溢出问题。内存溢出诊断规则对于调度任务自愈也是必备的前置条件。后面我们会讲如何根据内存溢出结论对调度任务做自愈的。
(五)数据膨胀规则
在开发spark任务中,用户也经常因为数据产生膨胀导致运行失败问题。因此我们根据spark的metric输入和输出指标,判断数据膨胀倍数,并给用户解决数据膨胀情况的诊断报告。

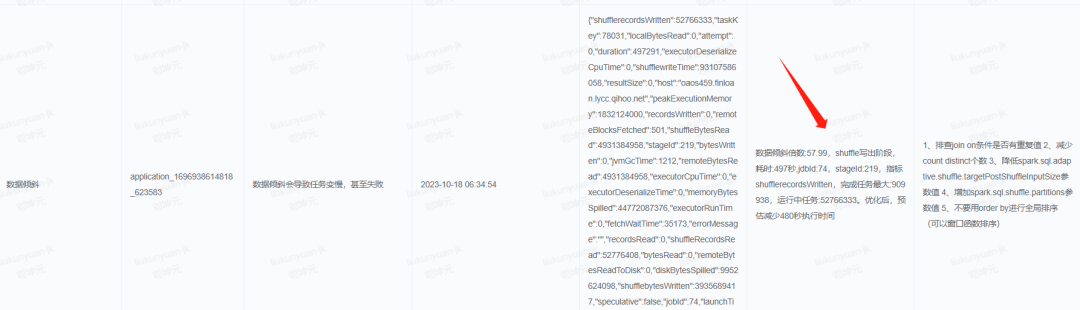
通过spark metric计算数据膨胀比根据log正则匹配复杂很多,以下是我们数据膨胀诊断规则流程图。
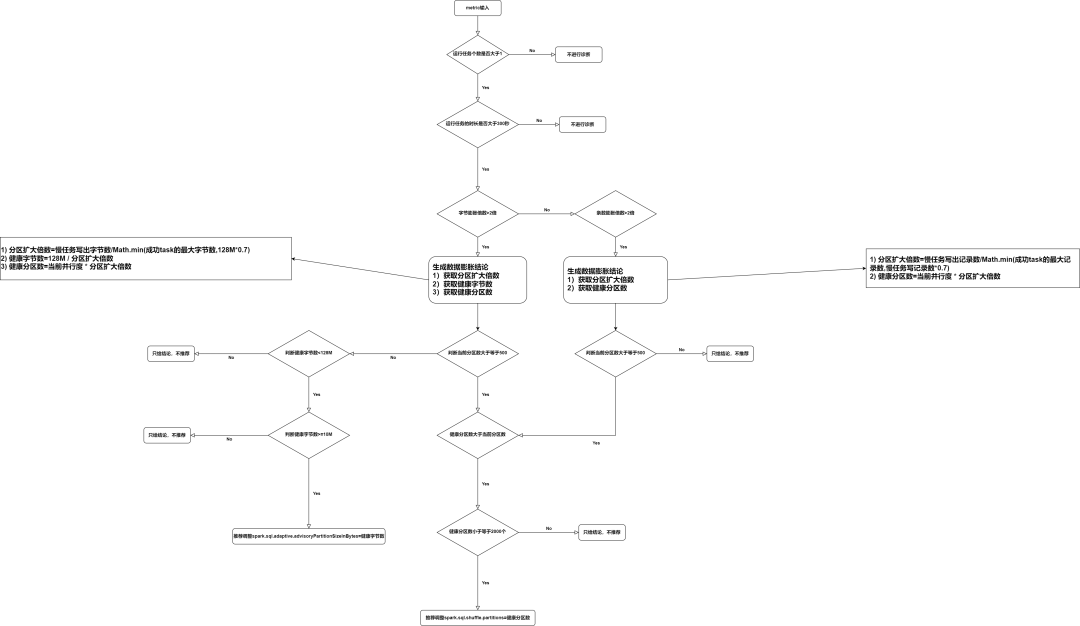
可以发现我们诊断数据膨胀是非常复杂的,而通过Janino实现的诊断规则兼容java语法,因此可以非常方便的实现一些非常复杂的诊断规则。
、
(六)数据倾斜规则
同样在开发spark任务过程中,我们也会经常遇到数据倾斜问题。我们也通过诊断规则实现了数据倾斜异常诊断并给出参数缓解该问题。 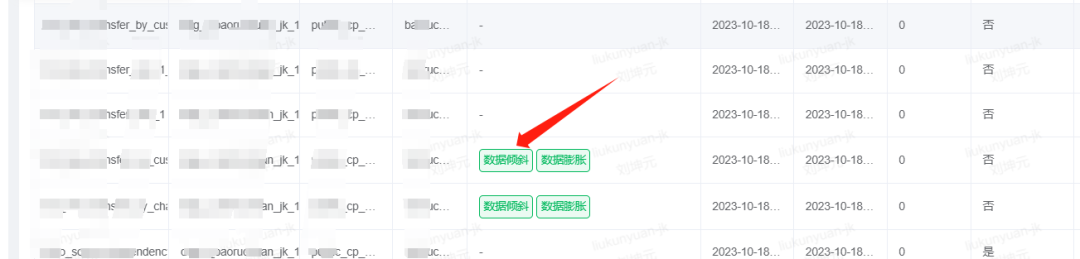
六、大数据任务自愈应用
(一)任务自愈目标
我们公司的核心大数据任务必须保证按时产出,而大数据任务高峰期又是在凌晨。因此很多用户会在凌晨值班时被告警电话叫起来处理问题。因此,我们想针对失败任务做自愈功能,比如数据质量校验不通过自愈、spark oom任务凌晨自愈。举例,在用户感知不到情况下,DolphinScheduler的worker通过对spark oom失败任务添加内存从而自愈,最终减少用户凌晨起夜率。而白天的oom任务,我们暂时没有开启自愈功能。
**(二)任务自愈实现流程**
以spark oom自愈举例,以下是我们调度根据诊断引擎生成的诊断报告对oom任务进行自愈的流程图。
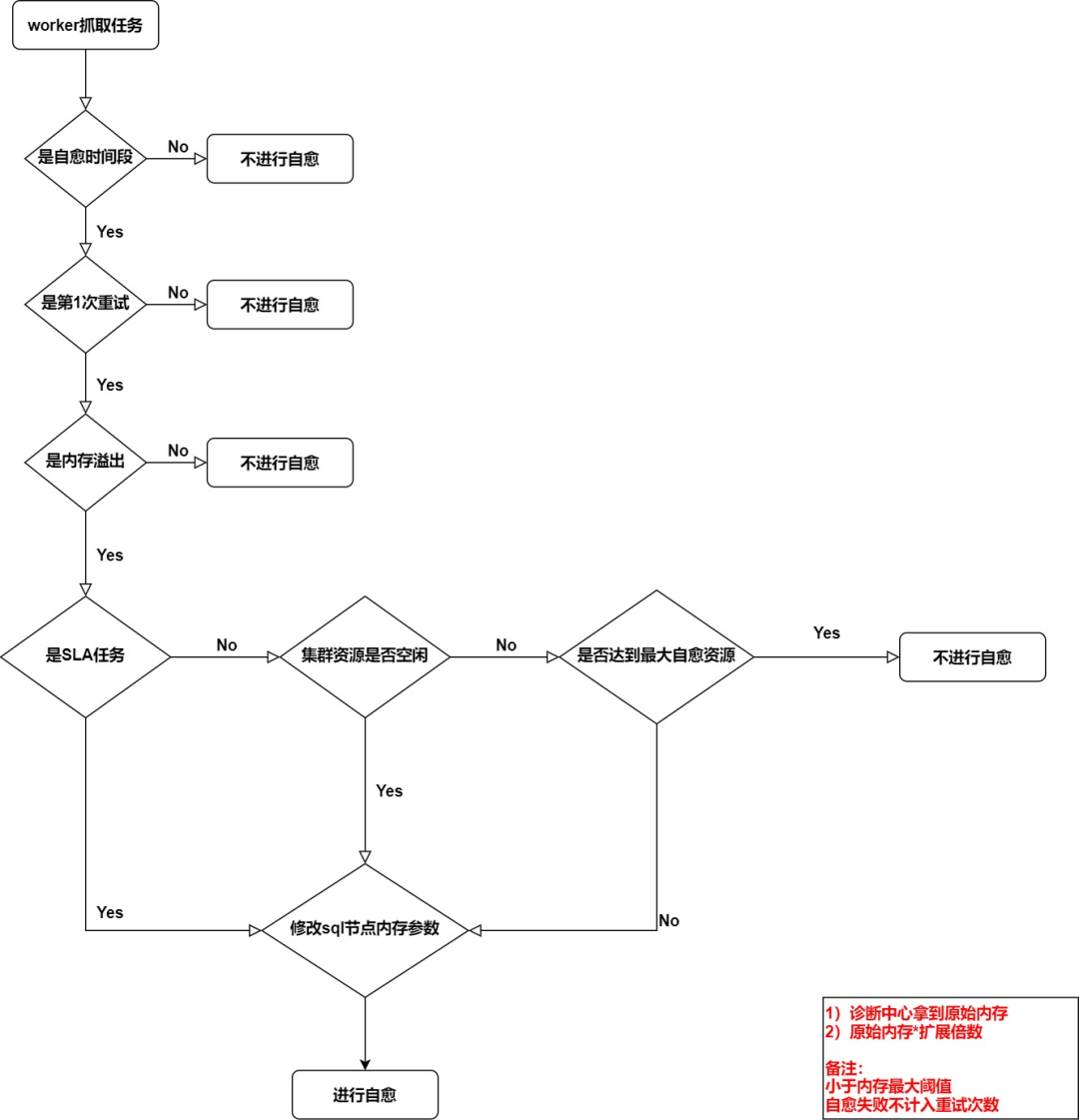
调度系统对oom自愈会限制时间段、是否SLA(核心)任务、上一次是否因为oom导致失败、集群资源是否空闲、资源资源是否充足等进行判断。从而实现了在资源可控状态下对oom任务进行内存资源扩容,从而让任务尝试自愈。
调度系统默默做了自愈,虽然让用户凌晨不用处理。但是,我们还是希望提示给用户,让用户白天处理,避免后续任务自愈失败。因此我们写了一个“尝试自愈”的诊断规则在用户查看工作流实例时提示给用户,后续也会在白天直接通过告警方式提示给用户。

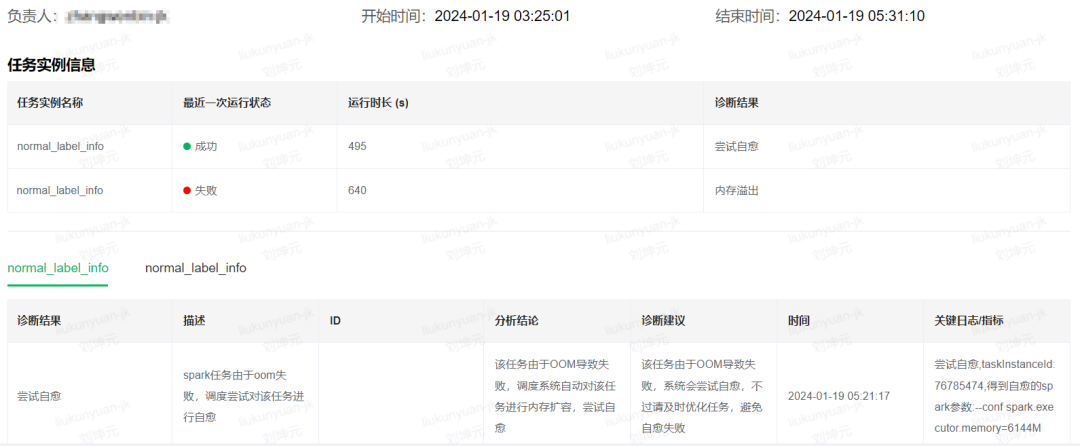
从诊断报告中我们可以看出该任务在凌晨3点前命中了“内存溢出”诊断规则,而调度系统自动对该任务的executor内存扩容到6144M,从而在05:31分运行成功。
(三)任务自愈落地效果
自从我们上线了oom任务自愈功能后,在生产环境取得了比较好的效果。对SLA(核心)任务和普通任务都开启自愈功能后,调度系统每天凌晨会进行10次左右“尝试自愈”操作。而只统计SLA(核心)任务,调度系统每周平均进行6次“尝试自愈”操作,减少了数仓同学67%的凌晨值班告警电话。
七、诊断引擎展望
(一)提升诊断覆盖率
目前工作流异常诊断覆盖率能达到85%,自助查询异常覆盖率能达到88%。后续可以继续新增诊断规则提升异常覆盖率。理论上工作流异常诊断覆盖率可以很容易达到95%,自助查询异常覆盖率达到98%。
(二)诊断分级
目前异常诊断没有分级功能,用户在查看诊断时不知道哪些诊断是“严重”,需要立即解决,哪些诊断属于“警告”,可以晚一点解决。我们可以添加诊断分级功能,甚至评分功能,让诊断有优先级能力。
(三)一键参数优化
目前对于数据膨胀、数据倾斜、内存异常,我们有spark参数推荐。不过还需要用户手动修改工作流进行设置,后面我们想用户点击“一键优化”能够自动将优化参数应用到任务中。
本文由 白鲸开源科技 提供发布支持!
更多【科技-奇富科技:大数据任务从诊断到自愈的实践之路】相关视频教程:www.yxfzedu.com
相关文章推荐
- hive-【Python大数据笔记_day06_Hive】 - 其他
- 算法-【C++入门】构造函数&&析构函数 - 其他
- unity-Unity地面交互效果——4、制作地面凹陷轨迹 - 其他
- python-Django如何创建表关系,Django的请求声明周期流程图 - 其他
- 算法-力扣21:合并两个有序链表 - 其他
- 算法-Leetcode2833. 距离原点最远的点 - 其他
- node.js-Node.js中的回调地狱 - 其他
- 人工智能-AIGC(生成式AI)试用 11 -- 年终总结 - 其他
- sqlite-计算机基础知识49 - 其他
- stable diffusion-AI 绘画 | Stable Diffusion 高清修复、细节优化 - 其他
- spring-SpringBoot中的桥接模式 - 其他
- 编程技术-Halcon WPF 开发学习笔记(2):Halcon导出c#脚本 - 其他
- mysql-【MySQL】视图 - 其他
- 编程技术-1994-2021年分行业二氧化碳排放量数据 - 其他
- 编程技术-SFTP远程终端访问 - 其他
- spring-【Spring】SpringBoot配置文件 - 其他
- 算法-“目标值排列匹配“和“背包组合问题“的区别和leetcode例题详解 - 其他
- java-一个轻量级 Java 权限认证框架——Sa-Token - 其他
- 运维-RK3568平台 查看内存的基本命令 - 其他
- 算法-深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
