tidb-【TiDB理论知识09】TiFlash
推荐 原创一 TiFlash架构
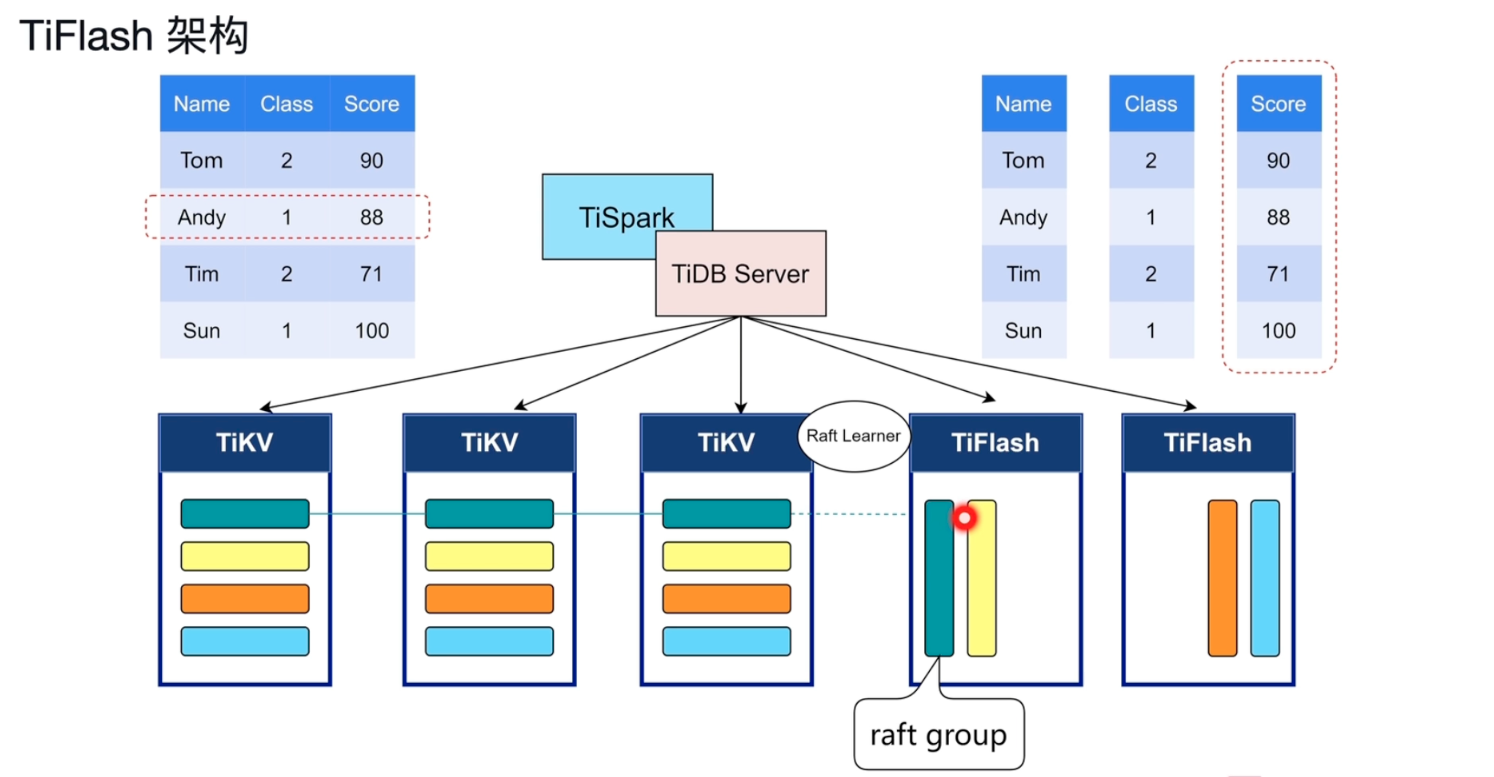
二 TiFlash 核心特性
TiFlash 主要有
- 异步复制、
- 一致性、
- 智能选择、
- 计算加速
等几个核心特性。
1 异步复制
TiFlash 中的副本以特殊角色 (Raft Learner) 进行异步的数据复制,这表示当 TiFlash 节点宕机或者网络高延迟等状况发生时,TiKV 的业务仍然能确保正常进行。
只从leader中接受raft log ,不参与 投票 选举 等。
基于主键快速更新 ,和TiKV 不会有过大的延迟 。
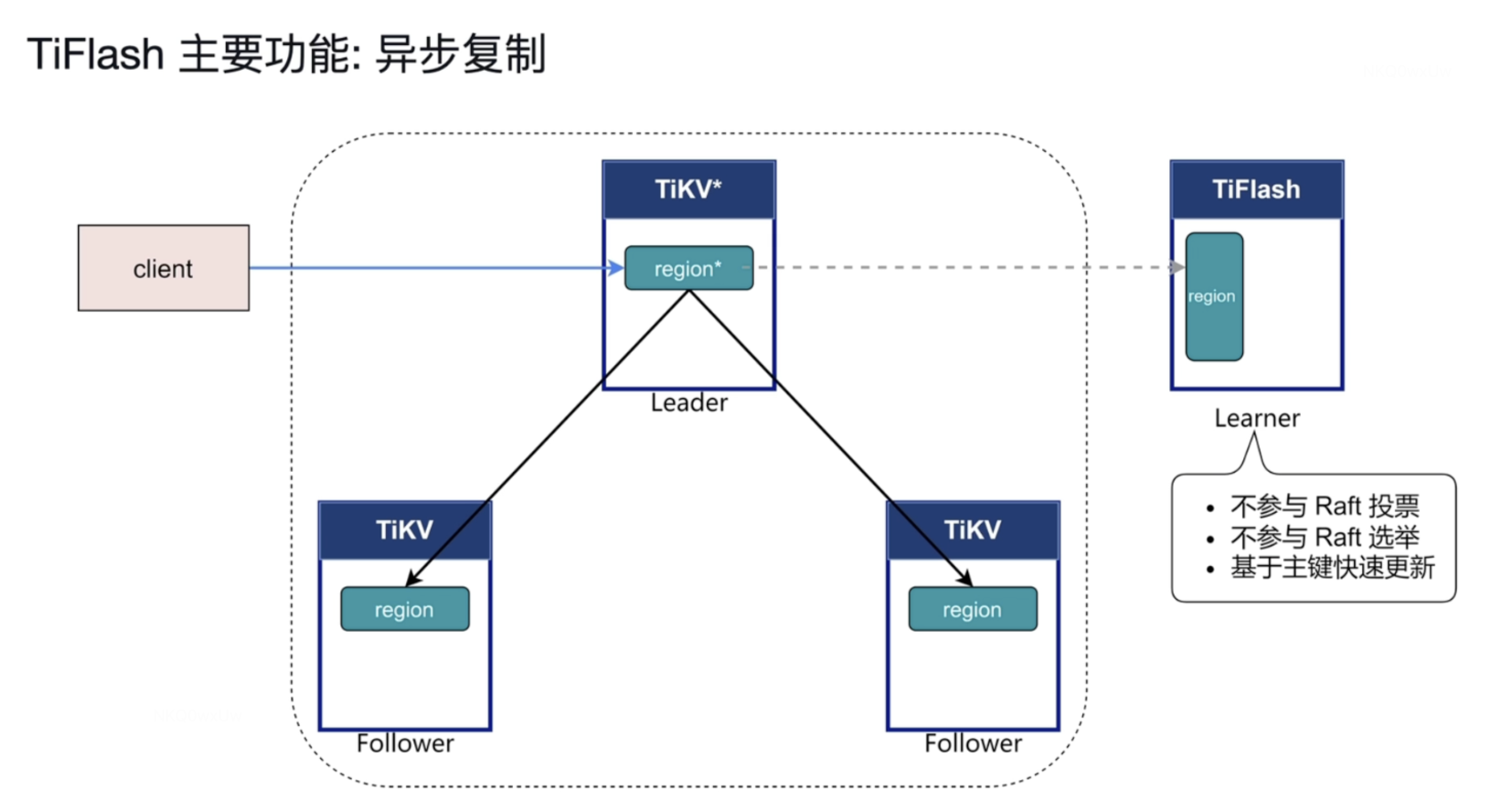
2 一致性读取
图解 :
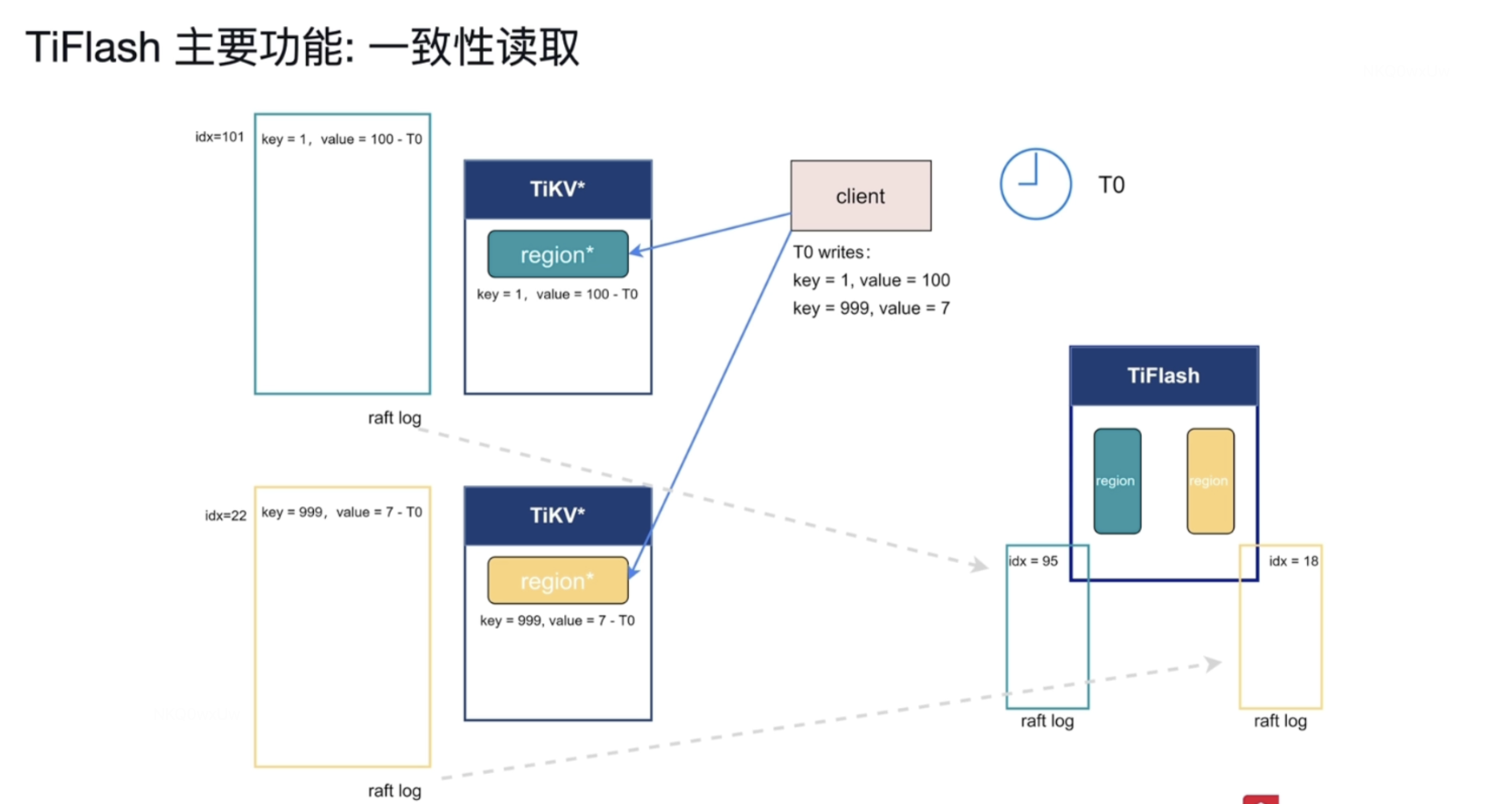
T0 时刻 客户端写入两条数据 分别为 key = 1 value = 100 ,key = 999 value =7,这两条数据分别存在两个TiKV的Region 上,写入数据会有Raft log,这两条数据写入日志的序列号分别为 101 和 22 。TiFlash的region通过 Raft Log 同步数据,此刻 同步到TiFlash的Raft Log日志索引号分别为95 和 18的日志。即数据还没有同步到TiFlash.
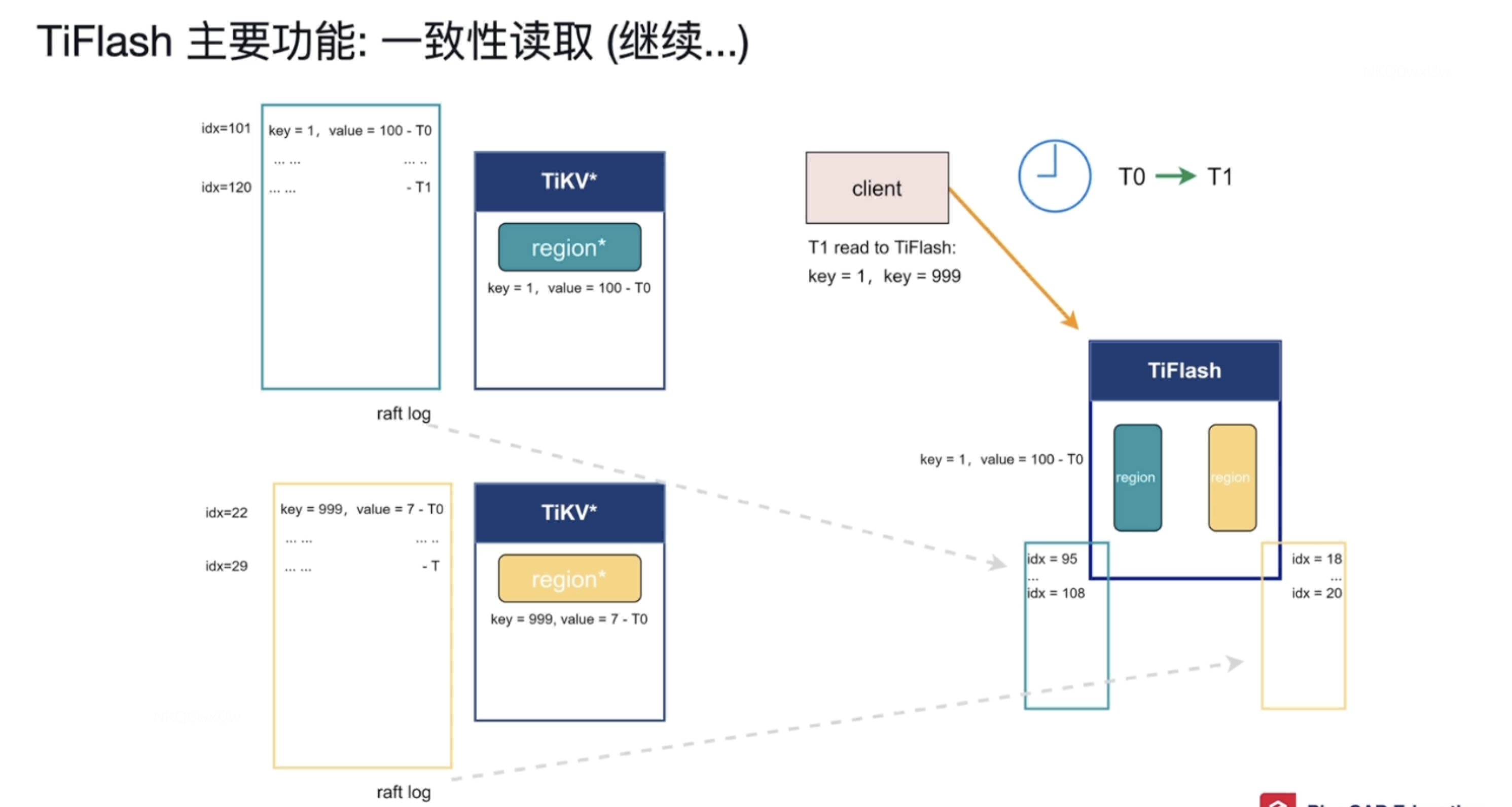
在T1 时刻客户端请求TiFlash 读取数据,T1时刻 ,TIKV的region数据已经写到日志序列号分别为 120 和 29的数据了 。TiFlash的数据刚到 106 和 20 。此刻TiFlash读取不到最新的数据
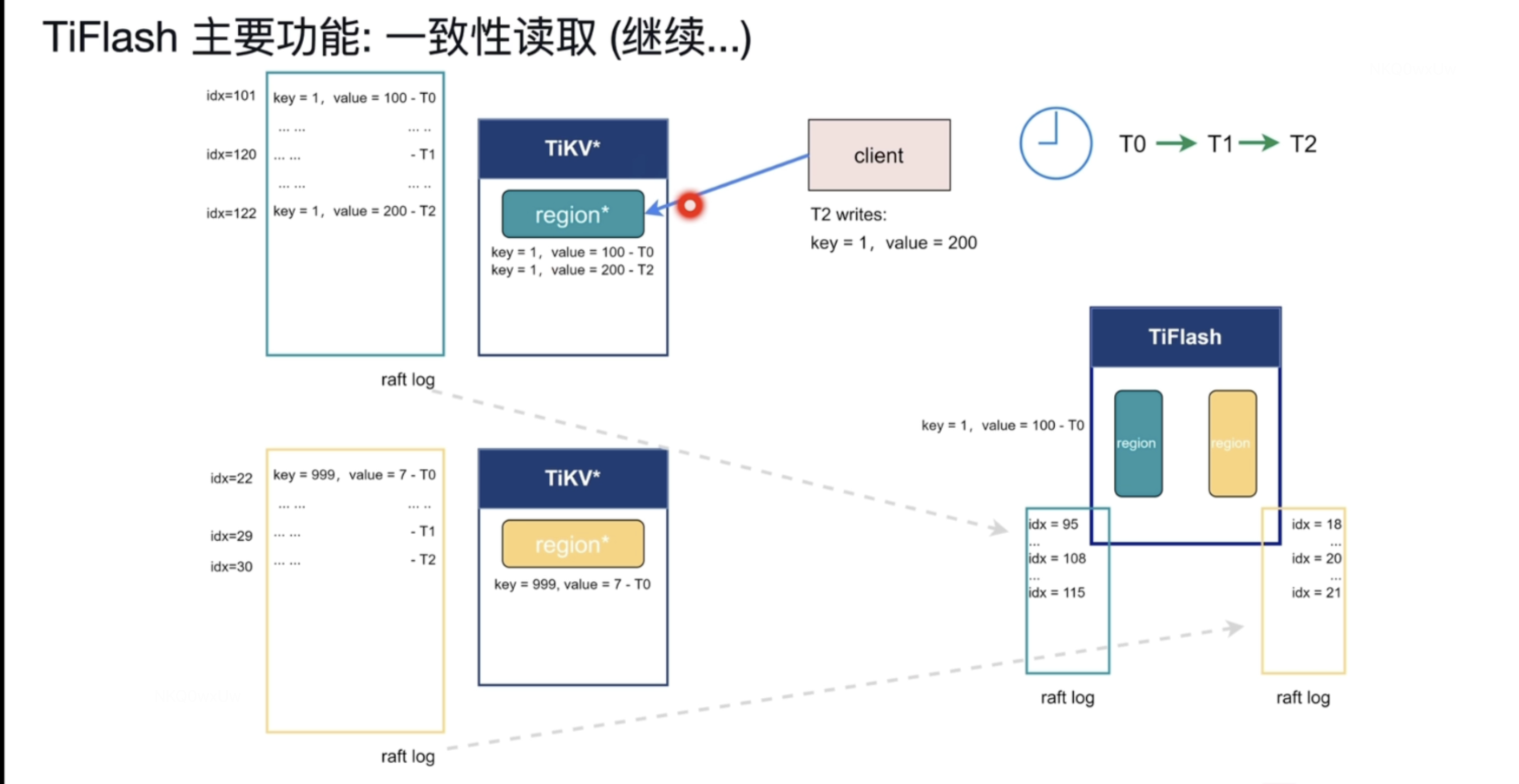
T2时刻 又有客户端向TiKV 写入数据,将key=1的数据 value cong 100改为了 200。写到了日志索引号分别为 122 和 30的日志了。那么问题来了 TiFlash 如何 确认我能读取到此刻TiKV 写入的最新数据同步到了TiFlash 呢 ?
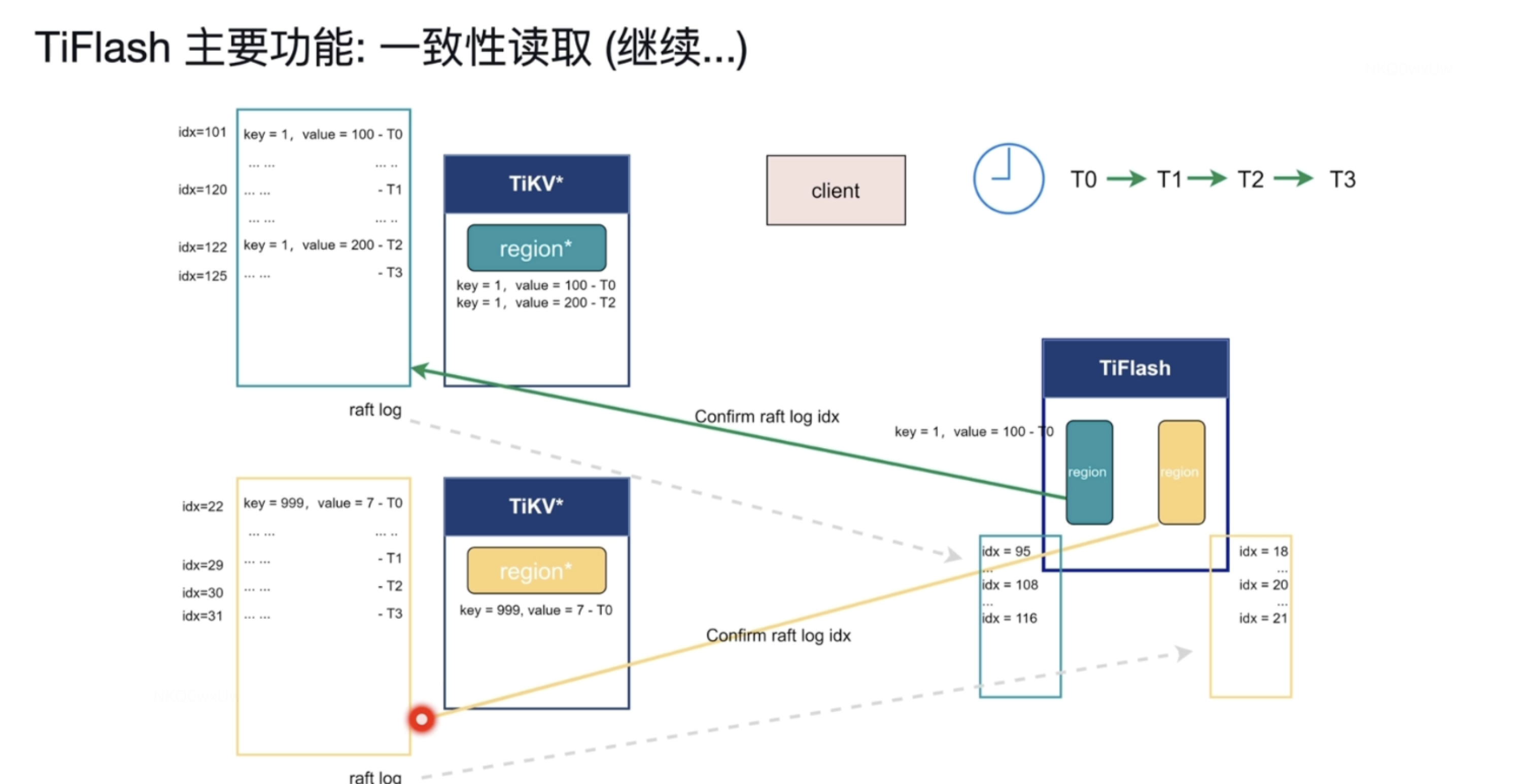
解决 :会做个轻量级的确认 ,T3时刻 TiKV 的数据 已经写到了 125和 31 ,TiFlash 写到了 116 和 21 。 那么TiFlash 会等待日志序列号分别为125和 31日志复制过来。
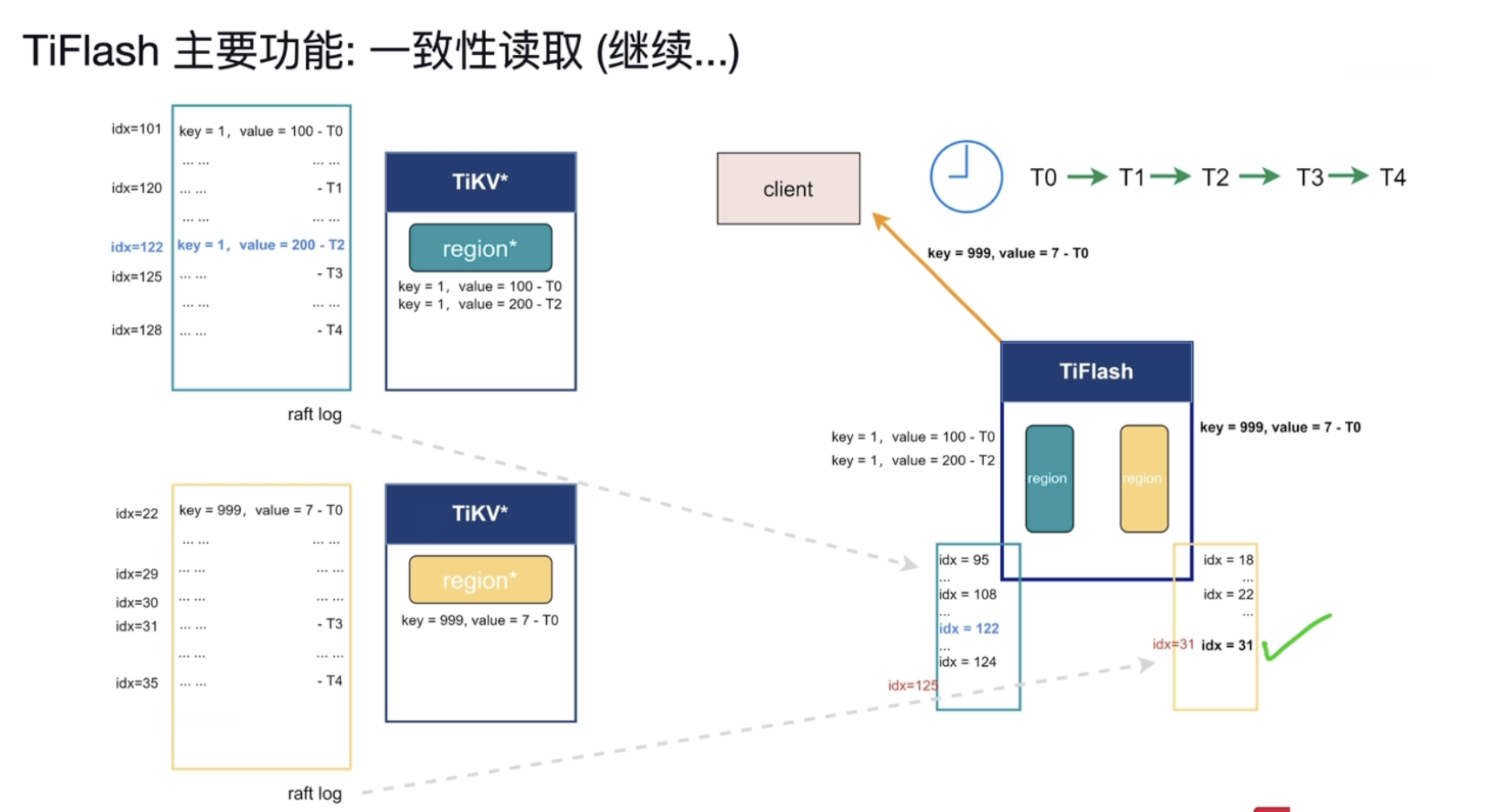
T4时刻 日志还没完全复制过来。
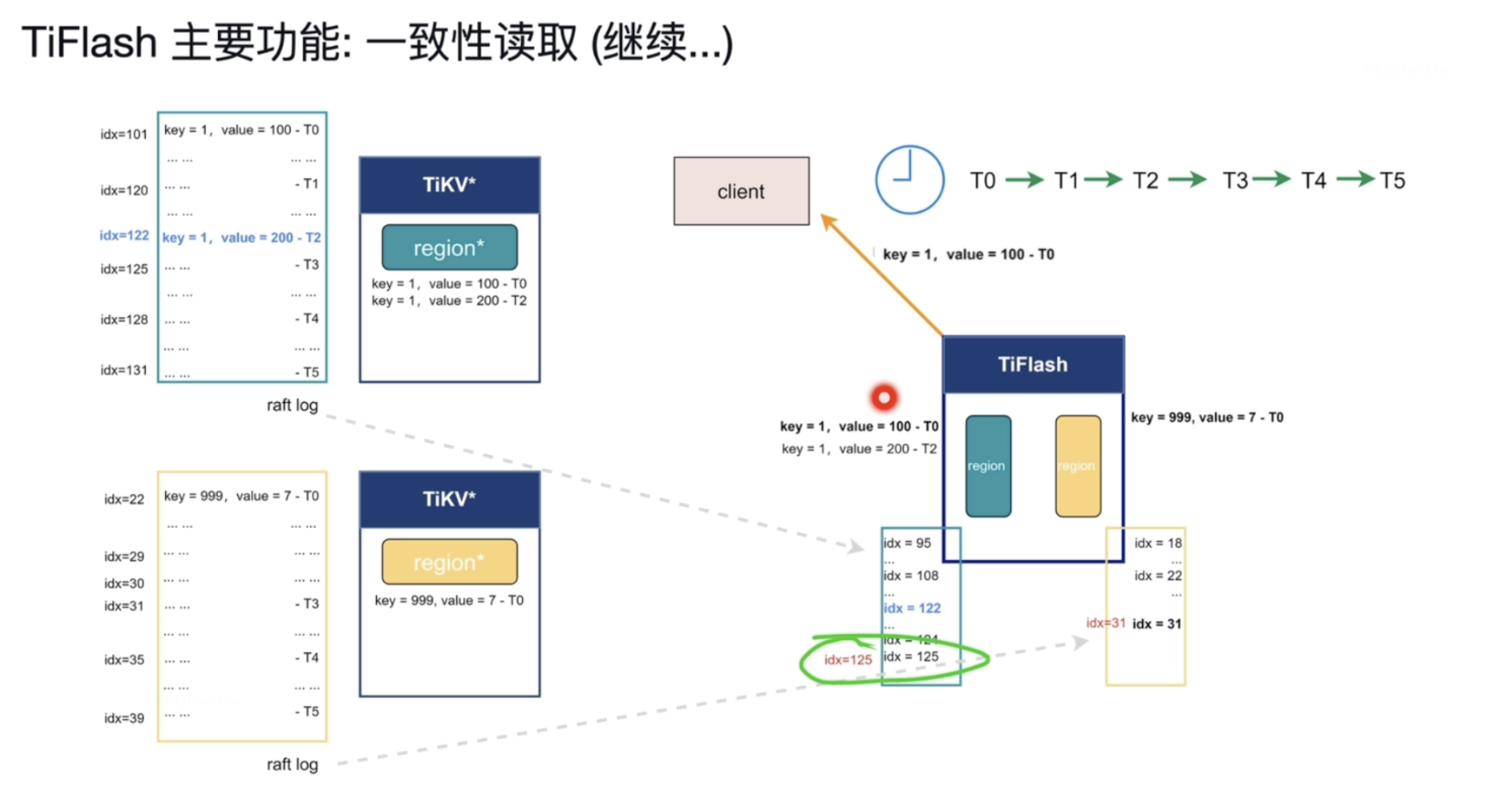
T5 时刻日志已经复制过来 ,但是查询请求是T1时刻发出,只能看到T1时刻之前的数据,所以读到的key=1的值为100;
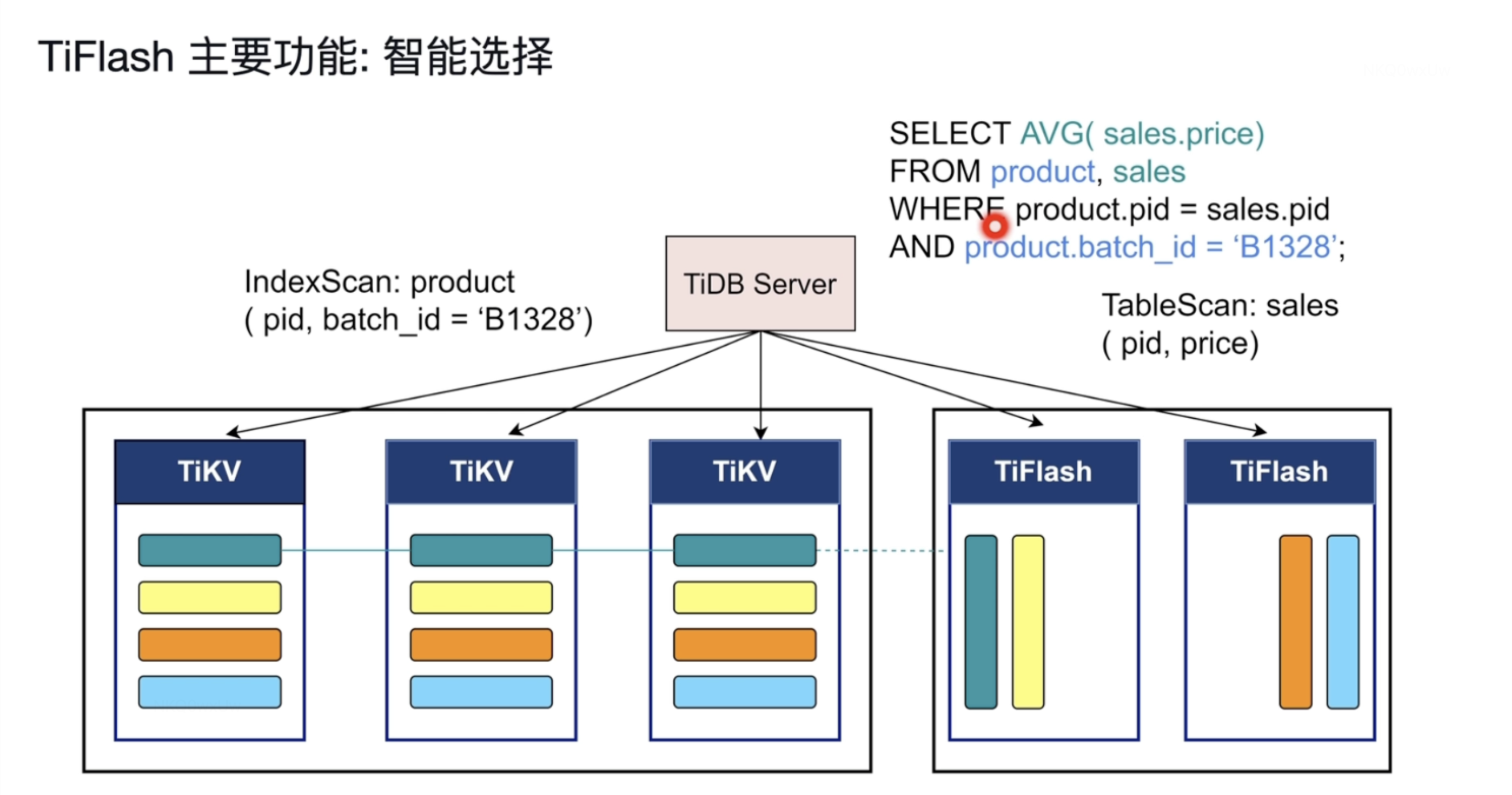
智能选择
TiDB 可以自动选择使用 TiFlash 列存或者 TiKV 行存,甚至在同一查询内混合使用提供最佳查询速度。这个选择机制与 TiDB 选取不同索引提供查询类似:根据统计信息判断读取代价并作出合理选择。
计算加速
TiFlash 对 TiDB 的计算加速分为两部分:列存本身的读取效率提升以及为 TiDB 分担计算。其中分担计算的原理和 TiKV 的协处理器一致:TiDB 会将可以由存储层分担的计算下推。
参考
更多【tidb-【TiDB理论知识09】TiFlash】相关视频教程:www.yxfzedu.com
相关文章推荐
- python-【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练 - 其他
- 编辑器-Linux编辑器---vim的使用 - 其他
- 矩阵-软文推广中媒体矩阵的优势在哪儿 - 其他
- 运维-CentOS 中启动 Jar 包 - 其他
- c#-C#中Linq AsEnumeralbe、DefaultEmpty和Empty的使用 - 其他
- jvm-JVM关键指标监控(调优) - 其他
- 编程技术-JavaScript + setInterval实现简易数据轮播效果 - 其他
- 编程技术-Datawhale智能汽车AI挑战赛 - 其他
- 编程技术-针对CSP-J/S的每日一练:Day 6 - 其他
- 编程技术-【vue实战项目】通用管理系统:api封装、404页 - 其他
- 云计算-软考 系统架构设计师系列知识点之云计算(3) - 其他
- 编程技术-排查Windows内存泄漏问题的详细记录 - 其他
- pdf-ReportLab创建合同PDF - 其他
- 编程技术-应用协议安全:Rsync-common 未授权访问. - 其他
- 编程技术-十九章总结 - 其他
- 编程技术-实用干货丨Eolink Apikit 配置和告警规则的各种用法 - 其他
- 系统架构-垂直领域对话系统架构 - 其他
- python-pycharm pro v2023.2.4(Python编辑开发) - 其他
- 云原生-修炼k8s+flink+hdfs+dlink(七:flinkcdc) - 其他
- 算法-《深入浅出进阶篇》洛谷P4147 玉蟾宫——悬线法dp - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 算法-“目标值排列匹配“和“背包组合问题“的区别和leetcode例题详解
- java-一个轻量级 Java 权限认证框架——Sa-Token
- 运维-RK3568平台 查看内存的基本命令
- 算法-深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明
- apache-Apache Doris 是什么
- list-Redis数据结构七之listpack和quicklist
- css-HTML CSS JS 画的效果图
- python-Win10系统下torch.cuda.is_available()返回为False的问题解决
- python-定义无向加权图,并使用Pytorch_geometric实现图卷积
- git-如何使用git-credentials来管理git账号
