聚类-无监督学习的集成方法:相似性矩阵的聚类
推荐 原创在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。
这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样非常成功的算法。通常应用一些投票/加权系统,将每个单独模型的输出组合成最终的、更健壮的和一致的输出。
在无监督学习领域,这项任务变得更加困难。首先,因为它包含了该领域本身的挑战,我们对数据没有先验知识,无法将自己与任何目标进行比较。其次,因为找到一种合适的方法来结合所有模型的信息仍然是一个问题,而且对于如何做到这一点还没有达成共识。
在本文中,我们讨论关于这个主题的最佳方法,即相似性矩阵的聚类。
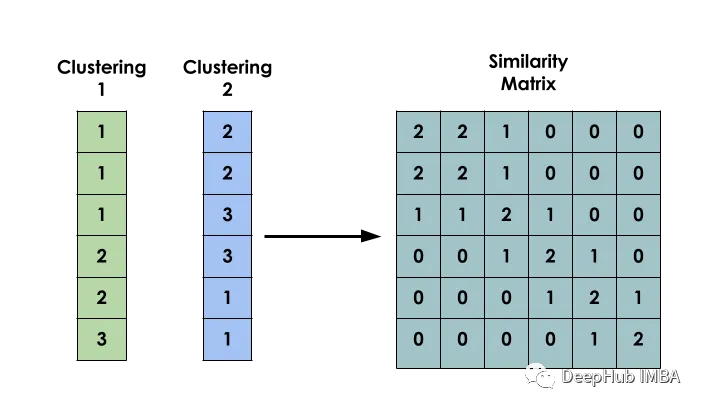
该方法的主要思想是:给定一个数据集X,创建一个矩阵S,使得Si表示xi和xj之间的相似性。该矩阵是基于几个不同模型的聚类结果构建的。
二元共现矩阵
构建模型的第一步是创建输入之间的二元共现矩阵。

它用于指示两个输入i和j是否属于同一个簇。
import numpy as np
from scipy import sparse
def build_binary_matrix( clabels ):
data_len = len(clabels)
matrix=np.zeros((data_len,data_len))
for i in range(data_len):
matrix[i,:] = clabels == clabels[i]
return matrix
labels = np.array( [1,1,1,2,3,3,2,4] )
build_binary_matrix(labels)
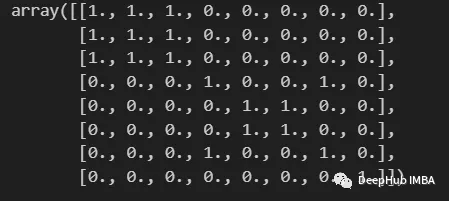
用KMeans构造相似矩阵
我们已经构造了一个函数来二值化我们的聚类,下面可以进入构造相似矩阵的阶段。
我们这里介绍一个最常见的方法,只包括计算M个不同模型生成的M个共现矩阵之间的平均值。定义为:

这样,落在同一簇中的条目的相似度值将接近于1,而落在不同组中的条目的相似度值将接近于0。
我们将基于K-Means模型创建的标签构建一个相似矩阵。使用MNIST数据集进行。为了简单和高效,我们将只使用10000张经过PCA降维的图像。
from sklearn.datasets import fetch_openml
from sklearn.decomposition import PCA
from sklearn.cluster import MiniBatchKMeans, KMeans
from sklearn.model_selection import train_test_split
mnist = fetch_openml('mnist_784')
X = mnist.data
y = mnist.target
X, _, y, _ = train_test_split(X,y, train_size=10000, stratify=y, random_state=42 )
pca = PCA(n_components=0.99)
X_pca = pca.fit_transform(X)
为了使模型之间存在多样性,每个模型都使用随机数量的簇实例化。
NUM_MODELS = 500
MIN_N_CLUSTERS = 2
MAX_N_CLUSTERS = 300
np.random.seed(214)
model_sizes = np.random.randint(MIN_N_CLUSTERS, MAX_N_CLUSTERS+1, size=NUM_MODELS)
clt_models = [KMeans(n_clusters=i, n_init=4, random_state=214)
for i in model_sizes]
for i, model in enumerate(clt_models):
print( f"Fitting - {i+1}/{NUM_MODELS}" )
model.fit(X_pca)
下面的函数就是创建相似矩阵
def build_similarity_matrix( models_labels ):
n_runs, n_data = models_labels.shape[0], models_labels.shape[1]
sim_matrix = np.zeros( (n_data, n_data) )
for i in range(n_runs):
sim_matrix += build_binary_matrix( models_labels[i,:] )
sim_matrix = sim_matrix/n_runs
return sim_matrix
调用这个函数:
models_labels = np.array([ model.labels_ for model in clt_models ])
sim_matrix = build_similarity_matrix(models_labels)
最终结果如下:
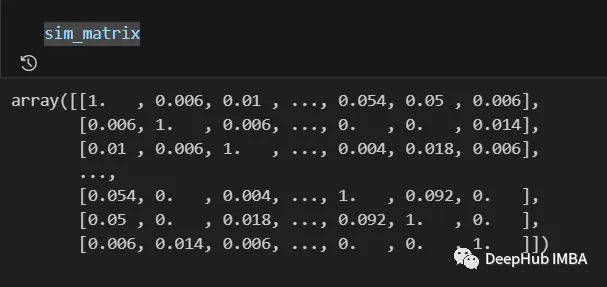
来自相似矩阵的信息在最后一步之前仍然可以进行后处理,例如应用对数、多项式等变换。
在我们的情况下,我们将不做任何更改。
Pos_sim_matrix = sim_matrix
对相似矩阵进行聚类
相似矩阵是一种表示所有聚类模型协作所建立的知识的方法。
通过它,我们可以直观地看到哪些条目更有可能属于同一个簇,哪些不属于。但是这些信息仍然需要转化为实际的簇。
这是通过使用可以接收相似矩阵作为参数的聚类算法来完成的。这里我们使用SpectralClustering。
from sklearn.cluster import SpectralClustering
spec_clt = SpectralClustering(n_clusters=10, affinity='precomputed',
n_init=5, random_state=214)
final_labels = spec_clt.fit_predict(pos_sim_matrix)
与标准KMeans模型的比较
我们来与KMeans进行性对比,这样可以确认我们的方法是否有效。
我们将使用NMI, ARI,集群纯度和类纯度指标来评估标准KMeans模型与我们集成模型进行对比。此外我们还将绘制权变矩阵,以可视化哪些类属于每个簇。
from seaborn import heatmap
import matplotlib.pyplot as plt
def data_contingency_matrix(true_labels, pred_labels):
fig, (ax) = plt.subplots(1, 1, figsize=(8,8))
n_clusters = len(np.unique(pred_labels))
n_classes = len(np.unique(true_labels))
label_names = np.unique(true_labels)
label_names.sort()
contingency_matrix = np.zeros( (n_classes, n_clusters) )
for i, true_label in enumerate(label_names):
for j in range(n_clusters):
contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label))
heatmap(contingency_matrix.astype(int), ax=ax,
annot=True, annot_kws={"fontsize":14}, fmt='d')
ax.set_xlabel("Clusters", fontsize=18)
ax.set_xticks( [i+0.5 for i in range(n_clusters)] )
ax.set_xticklabels([i for i in range(n_clusters)], fontsize=14)
ax.set_ylabel("Original classes", fontsize=18)
ax.set_yticks( [i+0.5 for i in range(n_classes)] )
ax.set_yticklabels(label_names, fontsize=14, va="center")
ax.set_title("Contingency Matrix\n", ha='center', fontsize=20)
from sklearn.metrics import normalized_mutual_info_score, adjusted_rand_score
def purity( true_labels, pred_labels ):
n_clusters = len(np.unique(pred_labels))
n_classes = len(np.unique(true_labels))
label_names = np.unique(true_labels)
purity_vector = np.zeros( (n_classes) )
contingency_matrix = np.zeros( (n_classes, n_clusters) )
for i, true_label in enumerate(label_names):
for j in range(n_clusters):
contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label))
purity_vector = np.max(contingency_matrix, axis=1)/np.sum(contingency_matrix, axis=1)
print( f"Mean Class Purity - {np.mean(purity_vector):.2f}" )
for i, true_label in enumerate(label_names):
print( f" {true_label} - {purity_vector[i]:.2f}" )
cluster_purity_vector = np.zeros( (n_clusters) )
cluster_purity_vector = np.max(contingency_matrix, axis=0)/np.sum(contingency_matrix, axis=0)
print( f"Mean Cluster Purity - {np.mean(cluster_purity_vector):.2f}" )
for i in range(n_clusters):
print( f" {i} - {cluster_purity_vector[i]:.2f}" )
kmeans_model = KMeans(10, n_init=50, random_state=214)
km_labels = kmeans_model.fit_predict(X_pca)
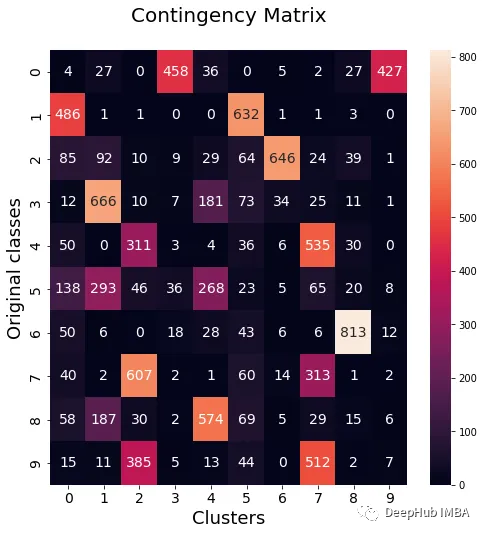
data_contingency_matrix(y, km_labels)
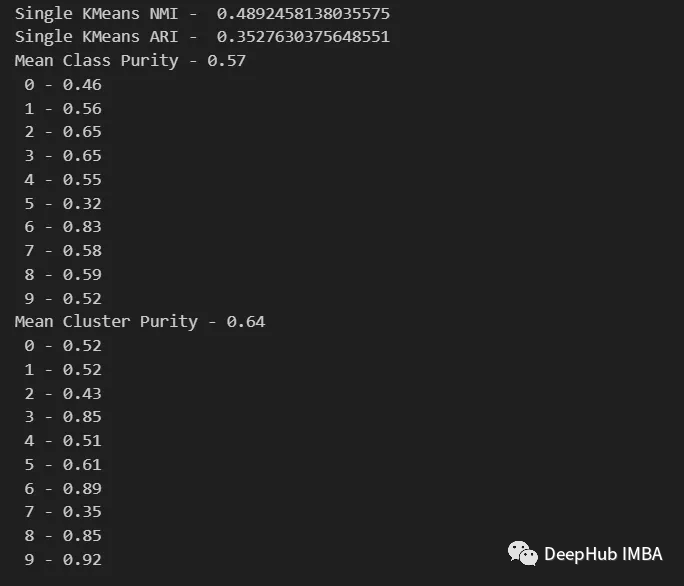
print( "Single KMeans NMI - ", normalized_mutual_info_score(y, km_labels) )
print( "Single KMeans ARI - ", adjusted_rand_score(y, km_labels) )
purity(y, km_labels)
data_contingency_matrix(y, final_labels)
print( "Ensamble NMI - ", normalized_mutual_info_score(y, final_labels) )
print( "Ensamble ARI - ", adjusted_rand_score(y, final_labels) )
purity(y, final_labels)
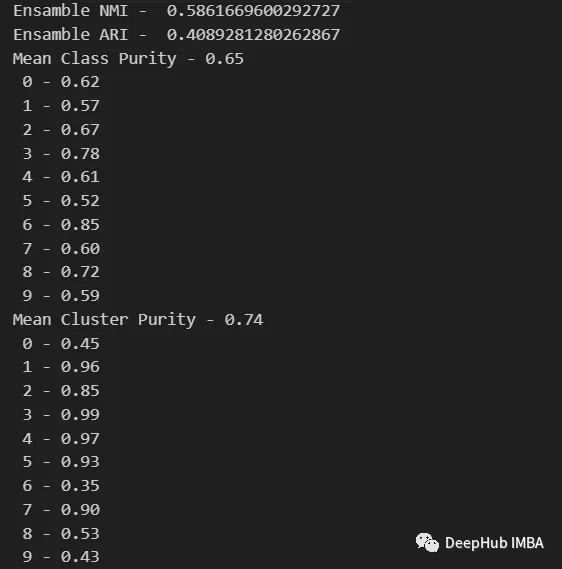
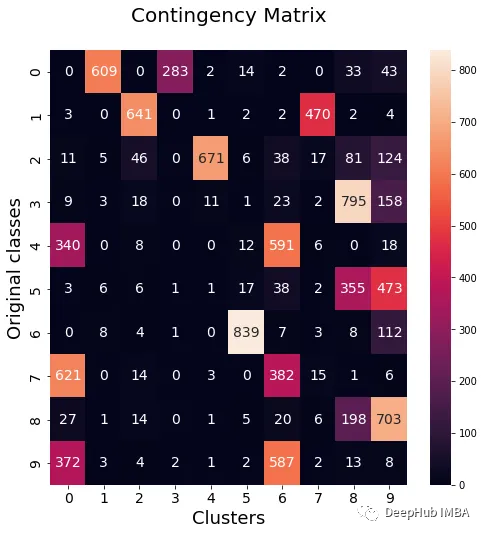
从上面的值可以看出,Ensemble方法确实能够提高聚类的质量。我们还可以在权变矩阵中看到更一致的行为,具有更好的分布类和更少的“噪声”。
本文引用
Strehl, Alexander, and Joydeep Ghosh. “Cluster ensembles — -a knowledge reuse framework for combining multiple partitions.” Journal of machine learning research 3.Dec (2002): 583–617.
Fred, Ana, and Anil K. Jain. “Combining multiple clusterings using evidence accumulation.” IEEE transactions on pattern analysis and machine intelligence 27.6 (2005): 835–850.
Topchy, Alexander, et al. “Combining multiple weak clusterings.” Third IEEE International Conference on Data Mining. IEEE, 2003.
Fern, Xiaoli Zhang, and Carla E. Brodley. “Solving cluster ensemble problems by bipartite graph partitioning.” Proceedings of the twenty-first international conference on Machine learning. 2004.
Gionis, Aristides, Heikki Mannila, and Panayiotis Tsaparas. “Clustering aggregation.” ACM Transactions on Knowledge Discovery from Data (TKDD) 1.1 (2007): 1–30.
https://avoid.overfit.cn/post/526bea5f183249008f77ccc479e2f555
作者:Nielsen Castelo Damasceno Dantas
更多【聚类-无监督学习的集成方法:相似性矩阵的聚类】相关视频教程:www.yxfzedu.com
相关文章推荐
- metersphere-社区分享|杭银消费金融基于MeterSphere开展接口自动化测试 - 其他
- uni-app-【uniapp】签名组件,兼容vue2vue3 - 其他
- 编程技术-【自然语言处理】基于python的问答系统实现 - 其他
- 编程技术-Bean作用域 - 其他
- lua-Unreal UnLua + Lua Protobuf - 其他
- python-【Python自学笔记】Flask调教方法Internel Server Error - 其他
- oracle-node插件MongoDB(二)——MongoDB的基本命令 - 其他
- 智能手机-手机怎么打包?三个方法随心选! - 其他
- 智能手机-香港金融科技周VERTU CSO Sophie谈Web3.0的下一个风口 手机虚拟货币移动支付 - 其他
- 搜索引擎-外贸网站优化常用流程和一些常识 - 其他
- 电脑-PHP分类信息网站源码系统 电脑+手机+微信端三合一 带完整前后端部署教程 - 其他
- 智能手机-手机是否能登陆国际腾讯云服务器? - 其他
- 智能手机-GD32单片机远程升级下载,手机在线升级下载程序,GD32在线固件下载升级,手机下载程序固件方法 - 其他
- 华为-漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案 - 其他
- 架构-LoRaWAN物联网架构 - 其他
- clickhouse-【总结卡】clickhouse数据库常用高级函数 - 其他
- java-深入理解ClickHouse跳数索引 - 其他
- 小程序-小程序发成绩 - 其他
- 运维-墨者学院 Ruby On Rails漏洞复现第一题(CVE-2018-3760) - 其他
- fpga开发-「Verilog学习笔记」多功能数据处理器 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- python-根据json生成Java类
- 运维-支撑企业数字化经营,《2023指标平台白皮书》正式发布
- safari-新的iLeakage攻击从Apple Safari窃取电子邮件和密码
- 网络-聊一聊 tcp/ip 在.NET故障分析的重要性
- .net-我的MQTT操作类(M2Mqtt.Net)
- 论文阅读-Count-based exploration with neural density models论文笔记
- 爬虫-在Kotlin中设置User-Agent以模拟搜索引擎爬虫
- elasticsearch-搜索引擎Elasticsearch基础与实践
- flink-flink1.18.0 macos sql-client.sh启动报错
- .net-Ubuntu安装.Net SDK