机器学习-信号处理--基于DEAP数据集的情绪分类的典型深度学习模型构建
推荐 原创关于
本实验采用DEAP情绪数据集进行数据分类任务。使用了三种典型的深度学习网络:2D 卷积神经网络;1D卷积神经网络+GRU; LSTM网络。
工具



数据集
DEAP数据

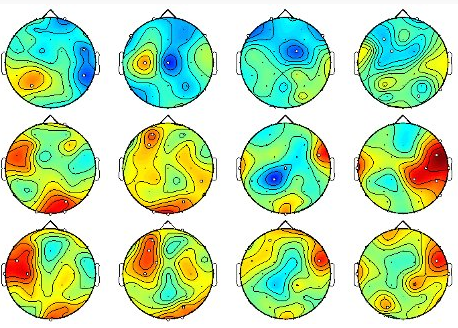
图片来源: DEAP: A Dataset for Emotion Analysis using Physiological and Audiovisual Signals
方法实现
2D-CNN网络
加载必要库函数
import pandas as pd
import keras.backend as K
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.models import Sequential
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from tensorflow.keras.utils import to_categorical
from keras.layers import Flatten
from keras.layers import Dense
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras import backend as K
from keras.models import Model
import timeit
from keras.models import Sequential
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution1D, MaxPooling1D, ZeroPadding1D
from tensorflow.keras.optimizers import SGD
#import cv2, numpy as np
import warnings
warnings.filterwarnings('ignore')加载DEAP数据集
data_training = []
label_training = []
data_testing = []
label_testing = []
for subjects in subjectList:
with open('/content/drive/My Drive/leading_ai/try/s' + subjects + '.npy', 'rb') as file:
sub = np.load(file,allow_pickle=True)
for i in range (0,sub.shape[0]):
if i % 5 == 0:
data_testing.append(sub[i][0])
label_testing.append(sub[i][1])
else:
data_training.append(sub[i][0])
label_training.append(sub[i][1])
np.save('/content/drive/My Drive/leading_ai/data_training', np.array(data_training), allow_pickle=True, fix_imports=True)
np.save('/content/drive/My Drive/leading_ai/label_training', np.array(label_training), allow_pickle=True, fix_imports=True)
print("training dataset:", np.array(data_training).shape, np.array(label_training).shape)
np.save('/content/drive/My Drive/leading_ai/data_testing', np.array(data_testing), allow_pickle=True, fix_imports=True)
np.save('/content/drive/My Drive/leading_ai/label_testing', np.array(label_testing), allow_pickle=True, fix_imports=True)
print("testing dataset:", np.array(data_testing).shape, np.array(label_testing).shape)数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)定义训练超参数
batch_size = 256
num_classes = 10
epochs = 200
input_shape=(x_train.shape[1], 1)定义模型
from keras.layers import Convolution1D, ZeroPadding1D, MaxPooling1D, BatchNormalization, Activation, Dropout, Flatten, Dense
from keras.regularizers import l2
model = Sequential()
intput_shape=(x_train.shape[1], 1)
model.add(Conv1D(164, kernel_size=3,padding = 'same',activation='relu', input_shape=input_shape))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=(2)))
model.add(Conv1D(164,kernel_size=3,padding = 'same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling1D(pool_size=(2)))
model.add(Conv1D(82,kernel_size=3,padding = 'same', activation='relu'))
model.add(MaxPooling1D(pool_size=(2)))
model.add(Flatten())
model.add(Dense(82, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(42, activation='tanh'))
model.add(Dropout(0.2))
model.add(Dense(21, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()模型配置和训练
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer='adam',
metrics=['accuracy'])
history=model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,validation_data=(x_test,y_test))
模型测试集验证
score = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
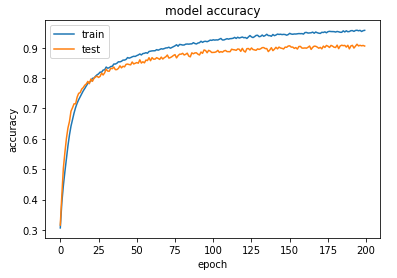
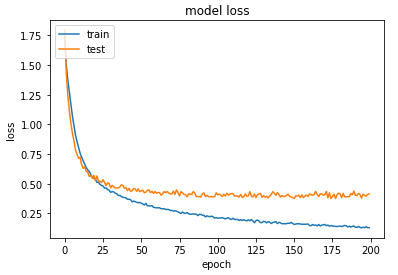
模型训练过程可视化
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
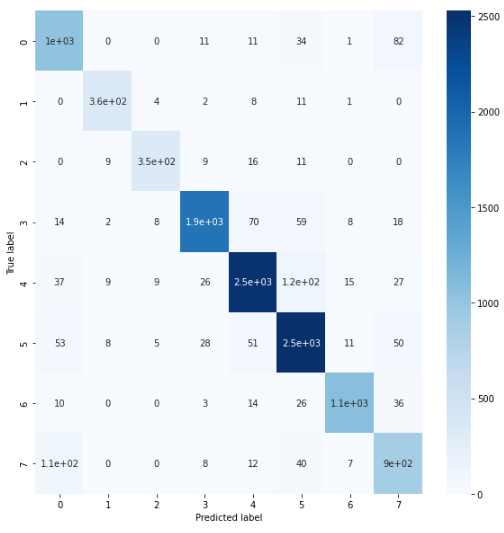
模型测试集分类混沌矩阵
cmatrix=confusion_matrix(y_test1, y_pred)
import seaborn as sns
figure = plt.figure(figsize=(8, 8))
sns.heatmap(cmatrix, annot=True,cmap=plt.cm.Blues)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
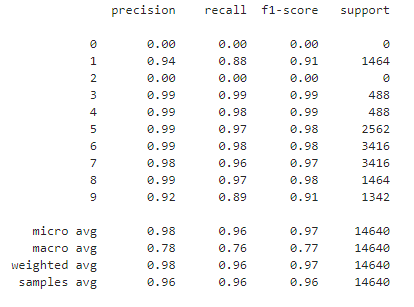
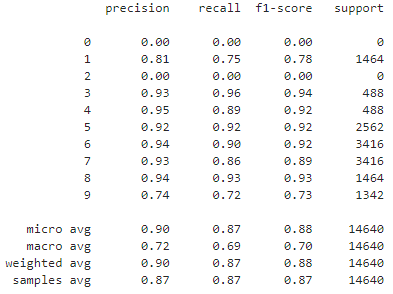
模型测试集分类report
from sklearn import metrics
y_pred = np.around(model.predict(x_test))
print(metrics.classification_report(y_test,y_pred))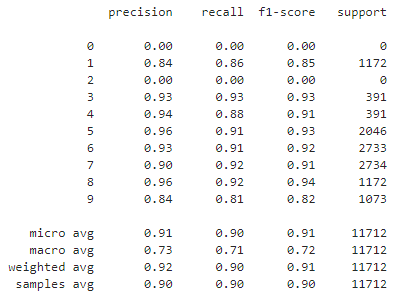
1D-CNN+GRU网络
数据预处理
必要库函数加载,数据加载预处理,同2D CNN一样,不在赘述。
!pip install git+https://github.com/forrestbao/pyeeg.git
import numpy as np
import pyeeg as pe
import pickle as pickle
import pandas as pd
import matplotlib.pyplot as plt
import math
import os
import time
import timeit
import keras
import keras.backend as K
from keras.models import Model
from keras.layers import Flatten
from keras.datasets import mnist
from keras.models import Sequential
from sklearn.preprocessing import normalize
from tensorflow.keras.optimizers import SGD
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.convolutional import ZeroPadding1D
from tensorflow.keras.utils import to_categorical
from keras.layers import Dense, Dropout, Flatten,GRU
import warnings
warnings.filterwarnings('ignore')模型搭建
from keras.layers import Convolution1D, ZeroPadding1D, MaxPooling1D, BatchNormalization, Activation, Dropout, Flatten, Dense,GRU,LSTM
from keras.regularizers import l2
from keras.models import load_model
from keras.layers import Lambda
import tensorflow as tf
model_2 = Sequential()
model_2.add(Conv1D(128, 3, activation='relu', input_shape=input_shape))
model_2.add(MaxPooling1D(pool_size=2))
model_2.add(Dropout(0.2))
model_2.add(Conv1D(128, 3, activation='relu'))
model_2.add(MaxPooling1D(pool_size=2))
model_2.add(Dropout(0.2))
model_2.add(GRU(units = 256, return_sequences=True))
model_2.add(Dropout(0.2))
model_2.add(GRU(units = 32))
model_2.add(Dropout(0.2))
model_2.add(Flatten())
model_2.add(Dense(units = 128, activation='relu'))
model_2.add(Dropout(0.2))
model_2.add(Dense(units = num_classes))
model_2.add(Activation('softmax'))
model_2.summary()

模型编译和训练
model_2.compile(
optimizer ="adam",
loss = 'categorical_crossentropy',
metrics=["accuracy"]
)
history_2 = model_2.fit(
x_train,
y_train,
epochs=epochs,
batch_size=batch_size,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[
keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=20,
restore_best_weights=True
)
]
)
模型训练过程可视化
# summarize history for accuracy
plt.plot(history_2.history['accuracy'],color='green',linewidth=3.0)
plt.plot(history_2.history['val_accuracy'],color='red',linewidth=3.0)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig("/content/drive/My Drive/GRU/model accuracy.png")
plt.show()
# summarize history for loss
plt.plot(history_2.history['loss'],color='green',linewidth=2.0)
plt.plot(history_2.history['val_loss'],color='red',linewidth=2.0)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig("/content/drive/My Drive/GRU/model loss.png")
plt.show()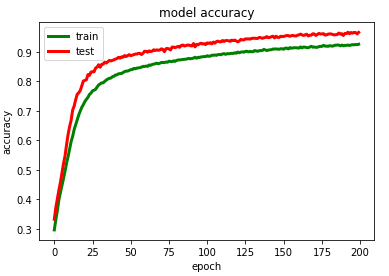
模型测试集分类混沌矩阵和分类report
LSTM网络
数据加载/预处理
同上
模型搭建和训练
from keras.regularizers import l2
from keras.layers import Bidirectional
from keras.layers import LSTM
model = Sequential()
model.add(Bidirectional(LSTM(164, return_sequences=True), input_shape=input_shape))
model.add(Dropout(0.6))
model.add(LSTM(units = 256, return_sequences = True))
model.add(Dropout(0.6))
model.add(LSTM(units = 82, return_sequences = True))
model.add(Dropout(0.6))
model.add(LSTM(units = 82, return_sequences = True))
model.add(Dropout(0.4))
model.add(LSTM(units = 42))
model.add(Dropout(0.4))
model.add(Dense(units = 21))
model.add(Activation('relu'))
model.add(Dense(units = num_classes))
model.add(Activation('softmax'))
model.compile(optimizer ="adam", loss =keras.losses.categorical_crossentropy,metrics=["accuracy"])
model.summary()
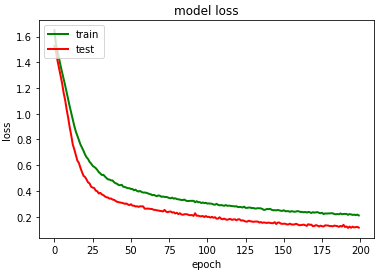
m=model.fit(x_train, y_train,epochs=200,batch_size=256,verbose=1,validation_data=(x_test, y_test))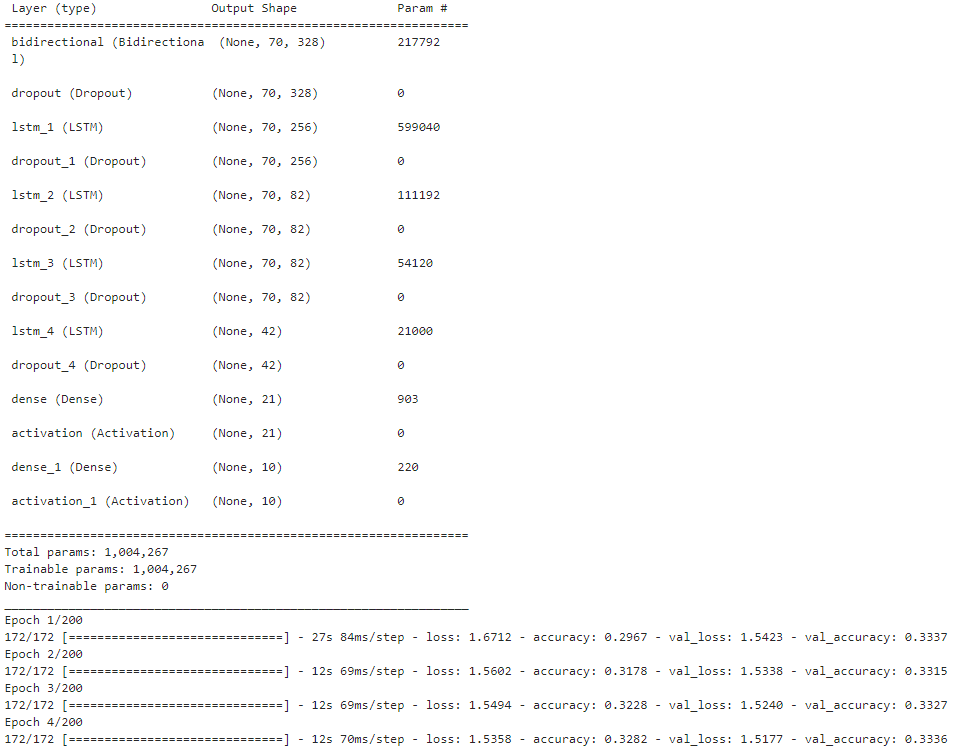
模型训练过程可视化
import matplotlib.pyplot as plt
print(m.history.keys())
# summarize history for accuracy
plt.plot(m.history['accuracy'],color='green',linewidth=3.0)
plt.plot(m.history['val_accuracy'],color='red',linewidth=3.0)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig("./Bi- LSTM/model accuracy.png")
plt.show()
import imageio
plt.plot(m.history['loss'],color='green',linewidth=2.0)
plt.plot(m.history['val_loss'],color='red',linewidth=2.0)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
#to save the image
plt.savefig("./Bi- LSTM/model loss.png")
plt.show()
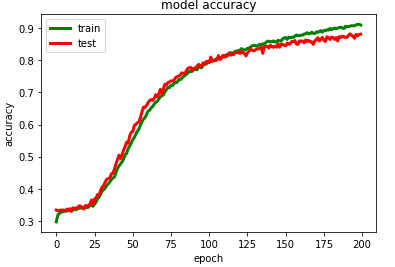
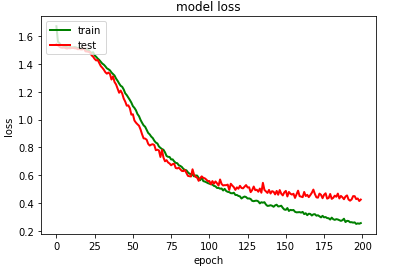
模型测试集分类性能
代码获取
后台私信,请注明文章题目(数据需要自己下载和处理)
相关项目和代码问题,欢迎交流。
更多【机器学习-信号处理--基于DEAP数据集的情绪分类的典型深度学习模型构建】相关视频教程:www.yxfzedu.com
相关文章推荐
- python-【PyTorch教程】如何使用PyTorch分布式并行模块DistributedDataParallel(DDP)进行多卡训练 - 其他
- 编辑器-Linux编辑器---vim的使用 - 其他
- 矩阵-软文推广中媒体矩阵的优势在哪儿 - 其他
- 运维-CentOS 中启动 Jar 包 - 其他
- c#-C#中Linq AsEnumeralbe、DefaultEmpty和Empty的使用 - 其他
- jvm-JVM关键指标监控(调优) - 其他
- 编程技术-JavaScript + setInterval实现简易数据轮播效果 - 其他
- 编程技术-Datawhale智能汽车AI挑战赛 - 其他
- 编程技术-针对CSP-J/S的每日一练:Day 6 - 其他
- 编程技术-【vue实战项目】通用管理系统:api封装、404页 - 其他
- 云计算-软考 系统架构设计师系列知识点之云计算(3) - 其他
- 编程技术-排查Windows内存泄漏问题的详细记录 - 其他
- pdf-ReportLab创建合同PDF - 其他
- 编程技术-应用协议安全:Rsync-common 未授权访问. - 其他
- 编程技术-十九章总结 - 其他
- 编程技术-实用干货丨Eolink Apikit 配置和告警规则的各种用法 - 其他
- 系统架构-垂直领域对话系统架构 - 其他
- python-pycharm pro v2023.2.4(Python编辑开发) - 其他
- 云原生-修炼k8s+flink+hdfs+dlink(七:flinkcdc) - 其他
- 算法-《深入浅出进阶篇》洛谷P4147 玉蟾宫——悬线法dp - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
