spark-Spark DAG
推荐 原创Spark DAG
什么是DAG
DAG 是一组顶点和边的组合。顶点代表了 RDD, 边代表了对 RDD 的一系列操作。
DAG Scheduler 会根据 RDD 的 transformation 动作,将 DAG 分为不同的 stage,每个 stage 中分为多个 task,这些 task 可以并行运行。
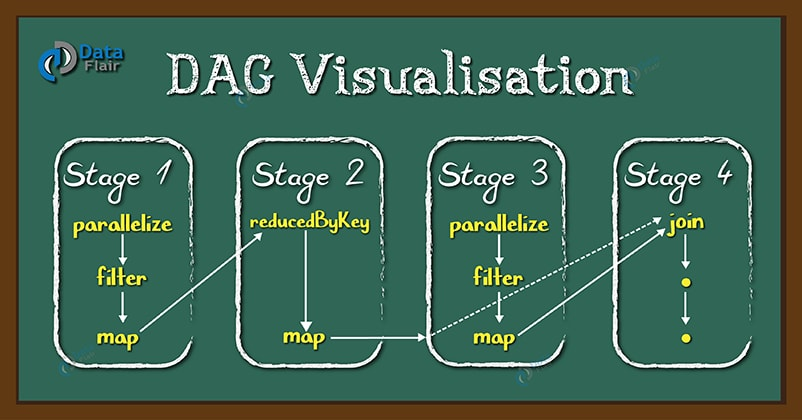
DAG 解决了什么问题
DAG 的出现主要是为了解决 Hadoop MapReduce 框架的局限性。那么 MapReduce 有什么局限性呢?
主要有两个:
- 每个 MapReduce 操作都是相互独立的,HADOOP不知道接下来会有哪些Map Reduce。
- 每一步的输出结果,都会持久化到硬盘或者 HDFS 上。
当以上两个特点结合之后,我们就可以想象,如果在某些迭代的场景下,MapReduce 框架会对硬盘和 HDFS 的读写造成大量浪费。
而且每一步都是堵塞在上一步中,所以当我们处理复杂计算时,会需要很长时间,但是数据量却不大。
所以 Spark 中引入了 DAG,它可以优化计算计划,比如减少 shuffle 数据。
DAG 是怎么工作的
DAG的工作流程:
- 解释器是第一层。Spark 通过使用Scala解释器,来解释代码,并会对代码做一些修改。
- 在Spark控制台中输入代码时,Spark会创建一个 operator graph, 来记录各个操作。
- 当一个 RDD 的 Action 动作被调用时, Spark 就会把这个 operator graph 提交到 DAG scheduler 上。
- DAG Scheduler 会把 operator graph 分为各个 stage。 一个 stage 包含基于输入数据分区的task。DAG scheduler 会把各个操作连接在一起。
- 这些 Stage 将传递给 Task Scheduler。Task Scheduler 通过 cluster manager 启动任务。Stage 任务的依赖关系, task scheduler 是不知道的。
- 在 slave 机器上的 Worker 们执行 task。
注意:
RDD 的 transformation 分为两种:窄依赖(如map、filter),宽依赖(如reduceByKey)。
窄依赖不需要对分区数据进行 shuffle ,而宽依赖需要。所以窄依赖都会在一个 stage 中, 而宽依赖会作为 stage 的交界处。
每个 RDD 都维护一个 metadata 来指向一个或多个父节点的指针以及记录有关它与父节点的关系类型。
更多【spark-Spark DAG】相关视频教程:www.yxfzedu.com
相关文章推荐
- python-定义无向加权图,并使用Pytorch_geometric实现图卷积 - 其他
- git-如何使用git-credentials来管理git账号 - 其他
- prompt-Anaconda Powershell Prompt和Anaconda Prompt的区别 - 其他
- python-Dhtmlx Event Calendar 付费版使用 - 其他
- gpt-ChatGPT、GPT-4 Turbo接口调用 - 其他
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- junit-Lua更多语法与使用 - 其他
- prompt-Presentation Prompter 5.4.2(mac屏幕提词器) - 其他
- css-CSS 网页布局 - 其他
- spring-idea中搭建Spring boot项目(借助Spring Initializer) - 其他
- 网络-# 深度解析 Socket 与 WebSocket:原理、区别与应用 - 其他
- prompt-屏幕提词软件Presentation Prompter mac中文版使用方法 - 其他
- java-AVL树详解 - 其他
- spring-在Spring Boot中使用JTA实现对多数据源的事务管理 - 其他
- 3d-原始html和vue中使用3dmol js展示分子模型,pdb文件 - 其他
- ddos-DDoS攻击剧增,深入解析抗DDoS防护方案 - 其他
- spring boot-AI 辅助学习:Spring Boot 集成 PostgreSQL 并设置最大连接数 - 其他
- golang-go中的rune类型 - 其他
- python-深度学习之基于Python+OpenCV(DNN)性别和年龄识别系统 - 其他
- 运维-Linux-Docker的基础命令和部署code-server - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
