破解某大厂安全方案代码混淆算法1-字符串加密
推荐 原创简介
本文主要介绍如何破解多款知名游戏内使用的某大厂安全组件内的字符串加密算法:包括其字符串加密的具体算法,以及如何找到所有的加密字符串及其引用地址,最终还原成完整的字符串表,以便于定位关键代码的具体逻辑。
还原的字符串表部分截图如下(完整字符串列表详见附件:libtersafe2_strings.txt):
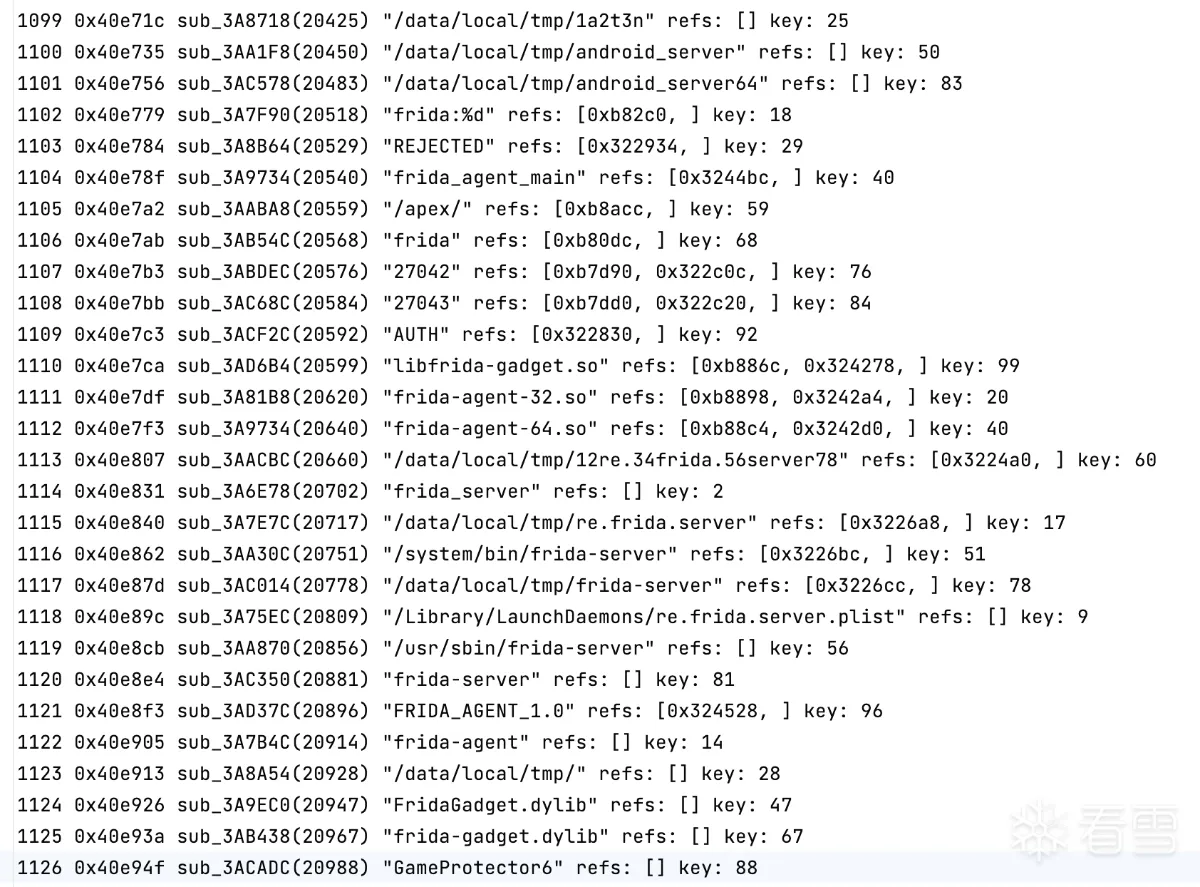
从上图中的字符串表我们能大概看到其检测frida相关逻辑使用的一些字符串,根据这些字符串的引用地址,我们就能对其具体的检测逻辑进行更进一步的深入分析。
字符串加密算法
首先我们在代码中能看到使用这些加密字符串的特征如下:

其中 sub_3AB54C(20568) 函数的返回值就是解密后字符串 char*的指针 ,该指针指向的值为字符串: frida 。并且通过上图我们可以得知加密字符串的解密算法就在 sub_3AB54C 这个函数内,另外我们也需要意识到这种字符串解密函数并不止一个,例如上图的另一个函数 sub_3ACF2C 也是用于解密字符串的变种函数,为了能解密所有的字符串,我们需要在破解了某一个函数内的字符串加密具体算法以后,还需要找到其他所有的字符串解密函数,并且从中总结出一个通用的解密算法,以便实现我们的目标:批量的解密所有的字符串。
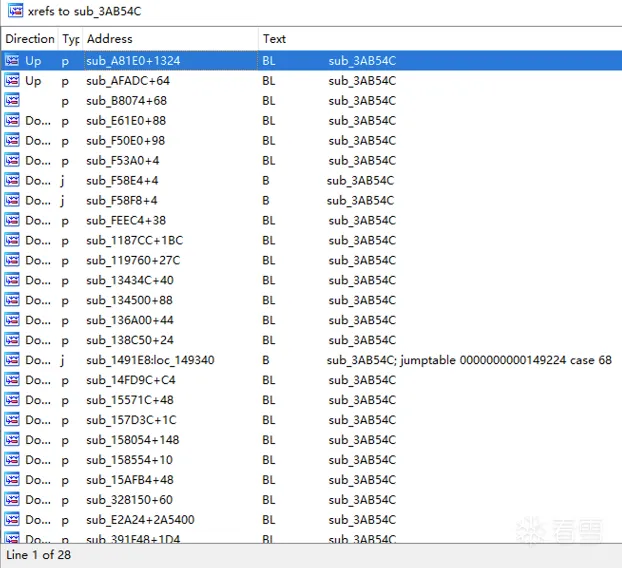
这里我们的策略是先分析第一个字符串解密函数:sub_3AB54C ,从上图我们可以得到该函数有一个 int 型的传参 a1 ,即这里的:20568 ,并且我们查看该函数的引用列表,可以看到该函数一共有28处调用:
并且每次调用该函数时的该传参的值都不一样:
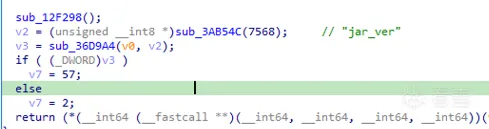
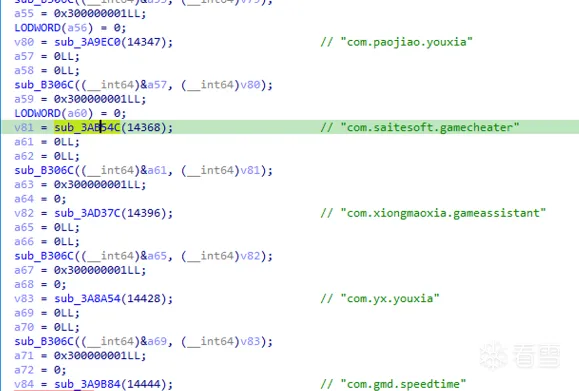
这里因为我已经把解密后的字符串patch到IDA的注释里面了,因此你很容易就看出了根据该传参的不同,该函数返回的字符串也不同,这里我们建立了这个认知就够了,至于具体该传参 a1 是什么含义,我们在分析该函数内代码时自然能明白。
接下来我们来具体分析一些这个函数内的代码逻辑,伪代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
char
*__fastcall sub_3AB54C(
int
a1)
{
_BYTE *v2;
// x19
_BYTE *v3;
// x0
_BYTE *v4;
// x10
__int64
v5;
// x8
__int64
v6;
// x11
unsigned
__int8
v7;
// w9
int
v8;
// w13
__int64
i;
// x14
int
v10;
// w2
char
*v11;
// x20
int
v12;
// w11
char
v13;
// w10
char
*v14;
// x12
char
v15;
// t1
int
v16;
// w10
__pid_t v17;
// w0
v2 = sub_3A46D0();
v3 = sub_3A46DC();
v4 = &v3[a1];
v5 = a1;
v6 = a1 + 1LL;
if
( *v4 )
{
v7 = v3[v6];
}
else
{
v8 = (unsigned
__int8
)v2[a1];
v7 = v2[v6] ^ v8;
if
( v7 )
{
for
( i = 0LL; i != v7; ++i )
{
v10 = (v8 + i) ^ 0x44;
v4[i + 2] = v2[a1 + 2 + i] ^ v8;
v8 = v10 + 2;
}
}
v3[a1 + 2 + (unsigned
__int64
)v7] = 0;
v3[v6] = v7;
v3[a1] = 1;
}
v11 = v4 + 2;
if
( v7 )
{
v12 = 0;
v13 = -1;
v14 = v11;
do
{
v15 = *v14++;
++v12;
v13 ^= v15;
}
while
( (unsigned
__int8
)v12 < (unsigned
int
)v7 );
v16 = (unsigned
__int8
)~v13;
}
else
{
v16 = 0;
}
if
( v16 != ((unsigned
__int8
)v2[v5] ^ (unsigned
__int8
)v2[v5 + 2 + v7]) )
{
v17 = j__getpid();
j__kill(v17, 9);
}
return
v11;
}
|
这个函数一看就不像一个正经的函数,明显就是解密什么东西,这里我们简单分析一下它的具体算法是什么。首先我们来看前面两句代码,它分别调用了2个函数,分别返回了两个地址:
|
1
2
|
v2 = sub_3A46D0();
// .rodata:0000000000409753
v3 = sub_3A46DC();
// .bss:000000000051F258
|
这里我们将这两个地址分别称为 .rodata_A 和 .bss_A 两个地址,熟悉字符串混淆算法的同学基本上已经大概能猜出它的算法了,很明显该字符串加密算法的逻辑和大部分的字符串加密算法差不多,其字符串的密文存放在 .rodata 段,然后通过该函数解密后,其解密后的字符串明文存放到了 .bss 段。因为这段代码逻辑太简单,这里我就不一行行的解释其逻辑了,直接用图文的形式来描述其字符串的具体加密/解密算法,因为我们的目的是用python直接从ELF文件中提取出所有的加密字符串,因此我们在看懂该加密算法后基本上都是用python重写一遍。
首先该函数的第一个参数 a1 其实是一个地址偏移值,我们将其称为 offset ,然后解密函数一开始就计算出了两个地址:
- 加密的字符串的密文在存放在
.rodata_A + offset的地址 - 解密后的字符串将存放在
.bss_A + offset的地址。
因此我们先来看密文,即.rodata_A + offset 地址的数据,二进制如下:
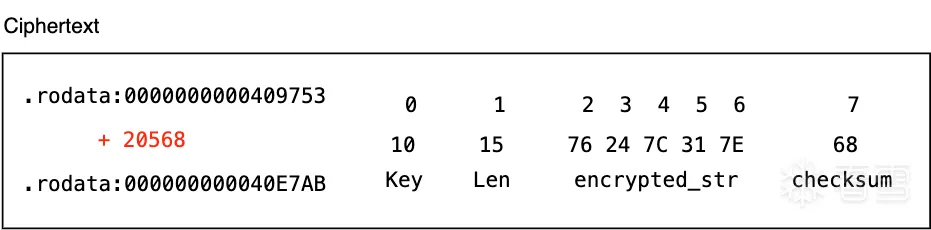
上图中 .rodata_A:0000000000409753 是所有字符串密文的起始地址, 每个加密的字符串的地址计算方式都为该起始地址加上offset。
在该密文地址的第0个字节是一个用于解密的 Key:
|
1
|
key
=
0x10
|
第1个字节为该加密字符串的长度 Len, 其具体的值需要使用 Key 进行解密,即:
|
1
|
str_len
=
0x15
^ key
=
5
|
解密后我们可以看到该加密字符串的长度为5,即接下来的5个bytes就是字符串的内容,我们需要使用如下的算法对每个字符进行解密:
|
1
2
3
4
|
for
i, c
in
enumerate
(str_bytes):
step
=
(key
+
i) ^ step_key
str_buf[i]
=
c ^ key
key
=
(step
+
step_num)
%
256
|
这里我们可以发现这里有一个对抗的算法,就是对每个加密字节进行异或解密的时候,用来异或的密钥并不仅仅是 key ,而是根据 key 和 当前的 index ,以及2个常量:step_key , step_num 计算而成的,这2个常量的值在一定程度增加了逆向的门槛,但也可以轻松解决,因为它存在一定规律,后面我们会具体来讨论,这里只需要知道每个解密字符串的变种函数内都存在不同的这2个常量,在目前我们分析的这个函数内,这两个常量分为是:
|
1
2
|
step_key
=
0x44
step_num
=
2
|
将这两个常量带入解密的算法中,我们就能对该字符串的每个字节进行解密,得到字符串的明文:
|
1
2
3
4
5
|
i
=
0
:
76
^
10
=
66
/
/
'f'
i
=
1
:
24
^
56
=
72
/
/
'r'
i
=
2
:
7c
^
15
=
69
/
/
'i'
i
=
3
:
31
^
55
=
64
/
/
'd'
i
=
4
:
7f
^
1e
=
61
/
/
'a'
|
解密后的字符串会写入到 .bss_A + offset 的地址以便后续复用,解密后的二进制数据如下:
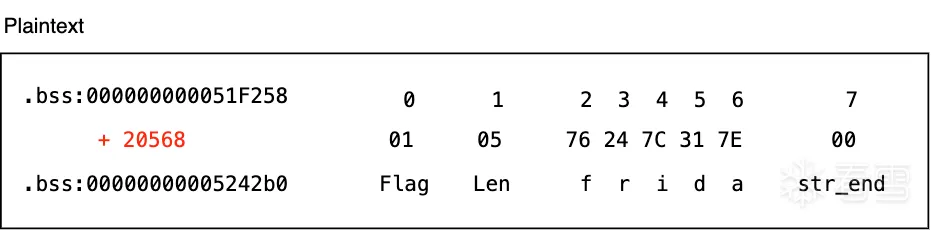
解密后的第0个字节是一个 Flag,用于标记该字符串是否被解密(0:未解密,1:已解密),如果已经解密过的字符串则无需重复解密(为了效率),直接从该内存地址读取即可,第1个字节是该字符串的长度 Len ,从第2个字节开始则是解密后的字符串明文,并且最后1个字节会增加一个C风格字符串的结束符 \0 。
另外值得注意的是:在加密字符串密文中的最后一个字节是这个字符串明文的一个 checksum ,用于校验解密字符串的结果是否正确,checksum 的算法如下:
|
1
2
3
4
5
|
def
checksum(data: bytes):
sum
=
-
1
for
c
in
data:
sum
^
=
c
return
~
sum
|
最后该解密字符串函数的返回值是解密后的字符串的地址:即:.bss_A + offset + 2 (前面2个字节不是字符串本身的内容,需要跳过)。
定位所有解密函数
从上一节的字符串加密算法中,我们已经得到如下几个信息:
- 有
N个变种的字符串解密函数 - 每个字符串解密函数中都存在一个用于生成解密字符串数据密钥的2个常量:我们暂时将其称为:
step_key,step_num
现在我们根据这些信息,可以很明确下一步就是找到所有这些字符串解密的变种函数,这里我们通过观察,可以总结出这些变种函数的特征:
- 函数开始的头2条指令是2个调用函数的指令,每个函数都会返回一个地址,其中1个指向
.rodata段,1个指向.bss段。 - 函数末尾,在校验字符串
checksum失败的时候会调用j__getpid和j__kill2个函数来退出程序。 - 函数存在1个loop,其中loop的主体中会使用异或
^的指令来生成密钥,并且解密字符串。
我们根据这些明显的函数特征,可以编写IDA的脚本并使用启发式算法来遍历所有函数,并定位到所有这些解密字符串的变种函数,例如:
|
1
2
3
4
5
6
7
8
9
10
11
|
(
"sub_384E24"
, step_key
=
0x0A
, step_num
=
4
),
(
"sub_38ACC4"
, step_key
=
0x62
, step_num
=
7
),
(
"sub_386A08"
, step_key
=
0x24
, step_num
=
6
),
(
"sub_387E80"
, step_key
=
0x37
, step_num
=
1
),
(
"sub_3883E0"
, step_key
=
0x3C
, step_num
=
3
),
(
"sub_387D6C"
, step_key
=
0x36
, step_num
=
2
),
(
"sub_389624"
, step_key
=
0x4D
, step_num
=
7
),
(
"sub_38AAA0"
, step_key
=
0x60
, step_num
=
2
),
(
"sub_384F38"
, step_key
=
0x0B
, step_num
=
3
),
(
"sub_3865BC"
, step_key
=
0x20
, step_num
=
3
),
...
|
下面我们提取出每个变种函数中的2个常量,观察一下 (step_key, step_num) 的集合的生成规则:
|
1
2
3
4
5
6
7
8
9
10
|
(
0
,
7
)(
1
,
6
)(
2
,
5
)(
3
,
4
)(
4
,
3
)(
5
,
2
)(
6
,
1
)(
7
,
7
)(
8
,
6
)(
9
,
5
)
(
10
,
4
)(
11
,
3
)(
12
,
2
)(
13
,
1
)(
14
,
7
)(
15
,
6
)(
16
,
5
)(
17
,
4
)(
18
,
3
)(
19
,
2
)
(
20
,
1
)(
21
,
7
)(
22
,
6
)(
23
,
5
)(
24
,
4
)(
25
,
3
)(
26
,
2
)(
27
,
1
)(
28
,
7
)(
29
,
6
)
(
30
,
5
)(
31
,
4
)(
32
,
3
)(
33
,
2
)(
34
,
1
)(
35
,
7
)(
36
,
6
)(
37
,
5
)(
38
,
4
)(
39
,
3
)
(
40
,
2
)(
41
,
1
)(
42
,
7
)(
43
,
6
)(
44
,
5
)(
45
,
4
)(
46
,
3
)(
47
,
2
)(
48
,
1
)(
49
,
7
)
(
50
,
6
)(
51
,
5
)(
52
,
4
)(
53
,
3
)(
54
,
2
)(
55
,
1
)(
56
,
7
)(
57
,
6
)(
58
,
5
)(
59
,
4
)
(
60
,
3
)(
61
,
2
)(
62
,
1
)(
63
,
7
)(
64
,
6
)(
65
,
5
)(
66
,
4
)(
67
,
3
)(
68
,
2
)(
69
,
1
)
(
70
,
7
)(
71
,
6
)(
72
,
5
)(
73
,
4
)(
74
,
3
)(
75
,
2
)(
76
,
1
)(
77
,
7
)(
78
,
6
)(
79
,
5
)
(
80
,
4
)(
81
,
3
)(
82
,
2
)(
83
,
1
)(
84
,
7
)(
85
,
6
)(
86
,
5
)(
87
,
4
)(
88
,
3
)(
89
,
2
)
(
90
,
1
)(
91
,
7
)(
92
,
6
)(
93
,
5
)(
94
,
4
)(
95
,
3
)(
96
,
2
)(
97
,
1
)(
98
,
7
)(
99
,
6
)
|
这里我们可以观察得知,一共存在100个解密函数的变种,并且每个函数只有对应的1个常量(即我们称为的 step_key), 而我们之前提到的所谓的 step_num 其实可能只是编译器做常量折叠优化的结果,其值完全可以根据 step_key 计算可得:
|
1
|
step_num
=
7
-
(step_key
%
7
)
|
现在我们成功找到了这100个解密字符串的变种函数,接下来编写IDA脚本获取这些函数的引用地址,并提取所有调用这些函数时的第1个传参(即我们需要的加密字符串的偏移 offset ),我们就基本上能获取如下所有信息:
- 解密字符的具体算法,包括解密字符串需要的密钥生成算法。
- 100个解密字符串变种函数的地址及其引用(我们将该解密字符串函数的引用地址可视为该字符串的引用地址)
在拥有这些信息后,就足以让我们编写出python脚本,直接从ELF文件中将这些加密的字符串中批量解密提取出来了。
结语
到此,你几乎可以解密并看到很多加密的字符串,可窥见该安全组件内一部分功能,并且根据这些字符串的引用地址,逐个去分析具体感兴趣的代码逻辑。
但不要高兴太早,从测试数据来看,其中还有至少一半的字符串是无法通过这种方法来解密出来的,因为虽然我们知道了其字符串解密的具体算法,和大部分的字符串密文的偏移和密钥,但因为我们是根据IDA分析出来的函数引用关系来提取字符串的,因此我们只能提取出IDA能正常分析的函数内使用的字符串,而这个安全组件内除了字符串加密的混淆算法以外,还有函数的混淆算法会导致IDA根本无法正常识别出这些加密的函数,因此这些加密函数内的字符串,本文提到的方式就暂时就无法提取出。
当然如果你需要看到所有的字符串也很简单,因为我们已知它只有100种变种的解密函数,而且我们也知道了密文的数据,并且因为每个加密的字符串都有一个 checksum 可用于验证,虽然我们无法得到每个字符串的具体偏移,但因为只有100种,我们完全可以直接用暴力破解的方法来用100种解密函数和密钥去遍历整个 .rodata 段的密文数据,然后就可以得到了所有的加密的字符串,但是这种暴力破解的方法有一个致命的缺点,因为它只能看到所有的字符串,但无法看到每个字符串的引用关系,而缺失字符串引用关系后,将无法定位使用这些字符串的代码位置,显然这并不是一个理想的解决方案,因为我们的目标不是去获取所有的字符串,而是希望形成一个完整的带引用关系的字符串表,用于定位关键代码的位置,以便更进一步的分析。
因此为了解决这个遗憾,我将会在下一篇文章《破解某大厂安全方案代码混淆算法2-控制流混淆》中详细阐述如何还原其加密函数的混淆算法,并让IDA能正常还原出其函数及CFG图,以便能将 所有 加密的字符串都全部提取出来,并且形成带每个字符串引用关系的完整字符串表,让我们能愉快的去分析感兴趣的具体代码的实现逻辑。
更多【破解某大厂安全方案代码混淆算法1-字符串加密】相关视频教程:www.yxfzedu.com
相关文章推荐
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全CTF对抗IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全CTF对抗IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全CTF对抗IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全CTF对抗IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全CTF对抗IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 集成学习-【Python机器学习】零基础掌握RandomForestRegressor集成学习
- java-LeetCode //C - 373. Find K Pairs with Smallest Sums
- 集成学习-【Python机器学习】零基础掌握StackingClassifier集成学习
- 编程技术-如何提高企业竞争力?CRM管理系统告诉你
- java-Java - Hutool 获取 HttpRequest:Header、Body、ParamMap 等利器
- c++-C++特殊类与单例模式
- 编辑器-vscode git提交
- 前端-WebGL的技术难点分析
- c++-【c++之设计模式】组合使用:抽象工厂模式与单例模式
- python-【JavaSE】基础笔记 - 类和对象(下)