首页/文章/软件逆向/入门编译原理之前端对接LLVM IR/
入门编译原理之前端对接LLVM IR
推荐 原创接上篇,本篇将前端解析到的AST对接到LLVM IR。本文目标明确,就直贴代码了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
|
import
llvmlite.ir as ir
import
llvmlite.binding as llvm
# 初始化LLVM
llvm.initialize()
llvm.initialize_native_target()
llvm.initialize_native_asmprinter()
# 创建LLVM模块
module
=
ir.Module(name
=
"my_module"
)
# 创建一个LLVM上下文和函数
context
=
ir.Context()
function
=
None
# 创建LLVM IR构建器
builder
=
None
# 创建一个LLVM上下文和函数
# context = llvm.getGlobalContext()
# function = None
# Token 类用于表示词法分析器生成的令牌
class
Token:
def
__init__(
self
,
type
, value
=
None
):
self
.
type
=
type
self
.value
=
value
# Lexer 类负责将输入文本解析成令牌流
class
Lexer:
def
__init__(
self
, text):
self
.text
=
text
# 要解析的文本
self
.pos
=
0
# 当前解析位置
# 获取下一个令牌
def
get_next_token(
self
):
if
self
.pos >
=
len
(
self
.text):
return
Token(
"EOF"
)
# 如果已经到达文本末尾,返回一个表示结束的令牌
current_char
=
self
.text[
self
.pos]
# 如果当前字符是字母,则解析标识符
if
current_char.isalpha():
identifier
=
""
while
self
.pos <
len
(
self
.text)
and
self
.text[
self
.pos].isalnum():
identifier
+
=
self
.text[
self
.pos]
self
.pos
+
=
1
return
Token(
"IDENTIFIER"
, identifier)
# 如果当前字符是数字,则解析数字
if
current_char.isdigit():
self
.pos
+
=
1
return
Token(
"NUMBER"
,
int
(current_char))
# 如果当前字符是运算符,则解析运算符
if
current_char
in
"+-*/"
:
self
.pos
+
=
1
return
Token(
"OPERATOR"
, current_char)
# 如果当前字符是等号,则解析为赋值符号
if
current_char
=
=
"="
:
self
.pos
+
=
1
return
Token(
"ASSIGN"
,
"="
)
# 如果当前字符是分号,则解析为分号
if
current_char
=
=
";"
:
self
.pos
+
=
1
return
Token(
"SEMICOLON"
,
";"
)
# 如果当前字符是左括号,则解析为左括号
if
current_char
=
=
"("
:
self
.pos
+
=
1
return
Token(
"LPAREN"
,
"("
)
# 如果当前字符是右括号,则解析为右括号
if
current_char
=
=
")"
:
self
.pos
+
=
1
return
Token(
"RPAREN"
,
")"
)
# 如果当前字符是空格或制表符,则忽略并获取下一个令牌
if
current_char
in
" \t"
:
self
.pos
+
=
1
return
self
.get_next_token()
raise
ValueError(
"Invalid character"
)
# 如果遇到无法识别的字符,引发异常
# Parser 类负责解析令牌流并计算结果
class
Parser:
def
__init__(
self
, lexer):
self
.lexer
=
lexer
# 词法分析器
self
.current_token
=
self
.lexer.get_next_token()
# 当前令牌
self
.variables
=
{}
# 存储变量名和值的字典
# 解析整个表达式并生成LLVM IR
def
parse(
self
):
global
builder, function
results
=
[]
# 创建主函数
main_function_type
=
ir.FunctionType(ir.IntType(
32
), ())
function
=
ir.Function(module, main_function_type, name
=
"main"
)
block
=
function.append_basic_block(name
=
"entry"
)
builder
=
ir.IRBuilder(block)
while
self
.current_token.
type
!
=
"EOF"
:
result
=
self
.parse_statement()
results.append(result)
if
self
.current_token.
type
=
=
"SEMICOLON"
:
self
.eat(
"SEMICOLON"
)
builder.ret(results[
-
1
])
return
results
# 解析表达式并生成LLVM IR
def
parse_expression(
self
, min_precedence
=
0
):
left
=
self
.parse_atom()
while
self
.current_token.
type
=
=
"OPERATOR"
and
self
.precedence(
self
.current_token.value) >
=
min_precedence:
operator
=
self
.current_token.value
self
.eat(
"OPERATOR"
)
right
=
self
.parse_expression(
self
.precedence(operator)
+
1
)
if
operator
=
=
"+"
:
result
=
builder.add(left, right, name
=
"addtmp"
)
elif
operator
=
=
"-"
:
result
=
builder.sub(left, right, name
=
"subtmp"
)
elif
operator
=
=
"*"
:
result
=
builder.mul(left, right, name
=
"multmp"
)
elif
operator
=
=
"/"
:
result
=
builder.sdiv(left, right, name
=
"divtmp"
)
left
=
result
return
left
# 解析原子表达式并生成LLVM IR
def
parse_atom(
self
):
if
self
.current_token.
type
=
=
"NUMBER"
:
value
=
self
.current_token.value
self
.eat(
"NUMBER"
)
return
ir.Constant(ir.IntType(
32
), value)
elif
self
.current_token.
type
=
=
"IDENTIFIER"
:
variable_name
=
self
.current_token.value
self
.eat(
"IDENTIFIER"
)
if
variable_name
in
self
.variables:
return
self
.variables[variable_name]
else
:
raise
ValueError(f
"Undefined variable: {variable_name}"
)
elif
self
.current_token.
type
=
=
"LPAREN"
:
self
.eat(
"LPAREN"
)
expression
=
self
.parse_expression()
self
.eat(
"RPAREN"
)
return
expression
else
:
raise
ValueError(
"Invalid syntax"
)
def
parse_statement(
self
):
if
self
.current_token.
type
=
=
"IDENTIFIER"
:
variable_name
=
self
.current_token.value
self
.eat(
"IDENTIFIER"
)
self
.eat(
"ASSIGN"
)
expression_value
=
self
.parse_expression()
self
.eat(
"SEMICOLON"
)
self
.variables[variable_name]
=
expression_value
return
expression_value
else
:
return
self
.parse_expression()
def
eat(
self
, token_type):
if
self
.current_token.
type
=
=
token_type:
self
.current_token
=
self
.lexer.get_next_token()
else
:
raise
ValueError(
"Unexpected token"
)
def
precedence(
self
, operator):
precedence
=
{
"+"
:
1
,
"-"
:
1
,
"*"
:
2
,
"/"
:
2
}
return
precedence.get(operator,
0
)
def
apply_operator(
self
, left, operator, right):
if
operator
=
=
"+"
:
return
left
+
right
elif
operator
=
=
"-"
:
return
left
-
right
elif
operator
=
=
"*"
:
return
left
*
right
elif
operator
=
=
"/"
:
return
left
/
right
# 计算函数,接受一个表达式并返回计算结果
def
calculate(expression):
lexer
=
Lexer(expression)
parser
=
Parser(lexer)
results
=
parser.parse()
# 使用 str 方法将 LLVM IR 内部表示转换为格式化的LLVM IR 汇编代码
formatted_ir
=
str
(module)
# 打印格式化的 LLVM IR 汇编代码
# print(formatted_ir)
return
results, formatted_ir
'''
# 测试代码
expression = "x = 3 * (4-1); y = 2*x + 2;"
# expression = "7"
results = calculate(expression)
print(results) # 输出结果为 [12, 14, None]
'''
# 测试代码
expression
=
"x = 3 * (4-1); y = 2*x + 2;"
llvm_ir
=
calculate(expression)
print
(
"\n------------------------------------------"
)
print
(
"LLVM IR的内部表示:\n"
, llvm_ir[
0
])
print
(
"\n------------------------------------------"
)
print
(
"LLVM IR的内部表示格式化和排版的LLVM IR汇编代码:\n"
, llvm_ir[
1
])
|
输出结果:
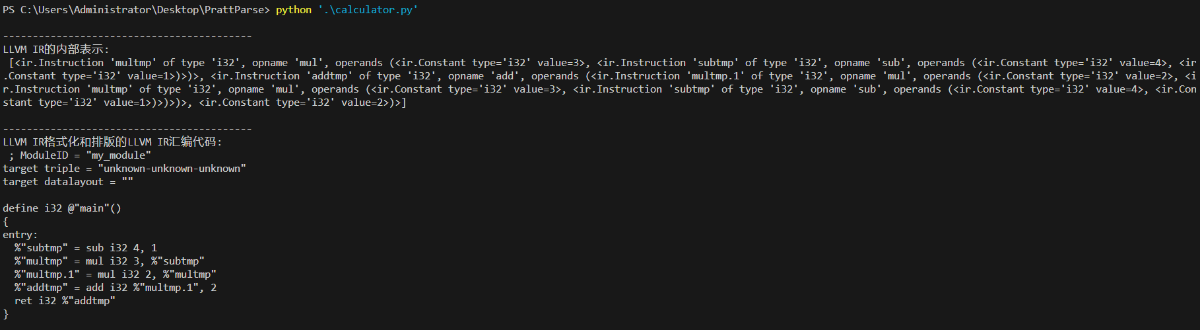
下篇就是将IR转成汇编语言了... ...
更多【入门编译原理之前端对接LLVM IR】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向-3CX供应链攻击样本分析 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞- AFL 源代码速通笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-DynamoRIO源码分析(一)--劫持进程 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-通用shellcode开发原理与实践 - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-server运行报错问题的解决 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次中联X科的试岗实战项目 - PwnHarmonyOSWeb安全软件逆向
- Android安全-对SM-P200平板的root记录 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞- AFL 源代码速通笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-DynamoRIO源码分析(一)--劫持进程 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-通用shellcode开发原理与实践 - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-server运行报错问题的解决 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次中联X科的试岗实战项目 - PwnHarmonyOSWeb安全软件逆向
- Android安全-对SM-P200平板的root记录 - PwnHarmonyOSWeb安全软件逆向
- 编程技术- 从应用层到MCU,看Windows处理键盘输入 [1.在应用层调试Notepad.exe (按键消费者)] - PwnHarmonyOSWeb安全软件逆向
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多