spring-springboot第46集:Nginx,Sentinel,计算机硬件的介绍
推荐 原创

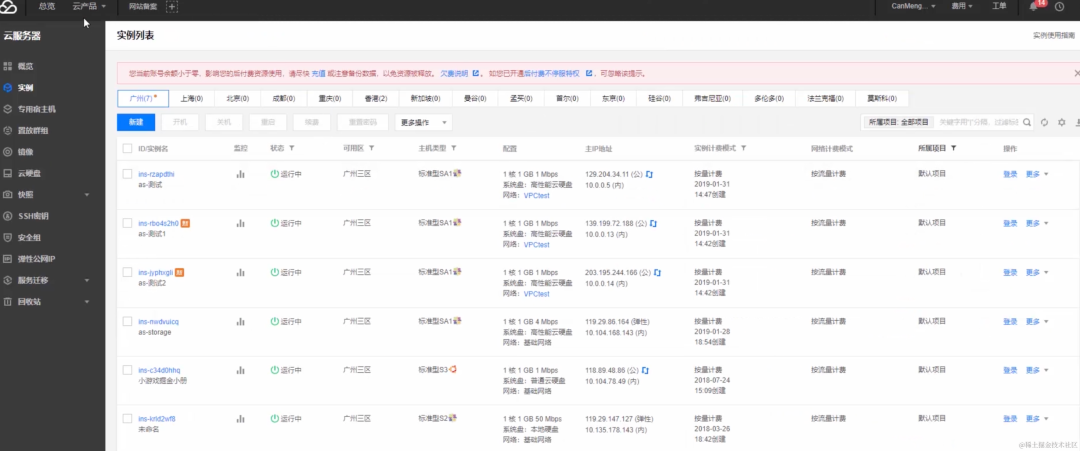
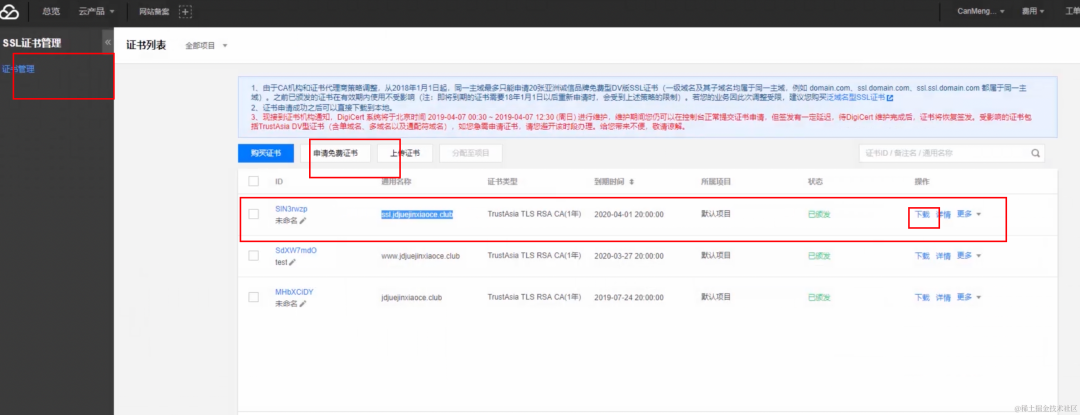
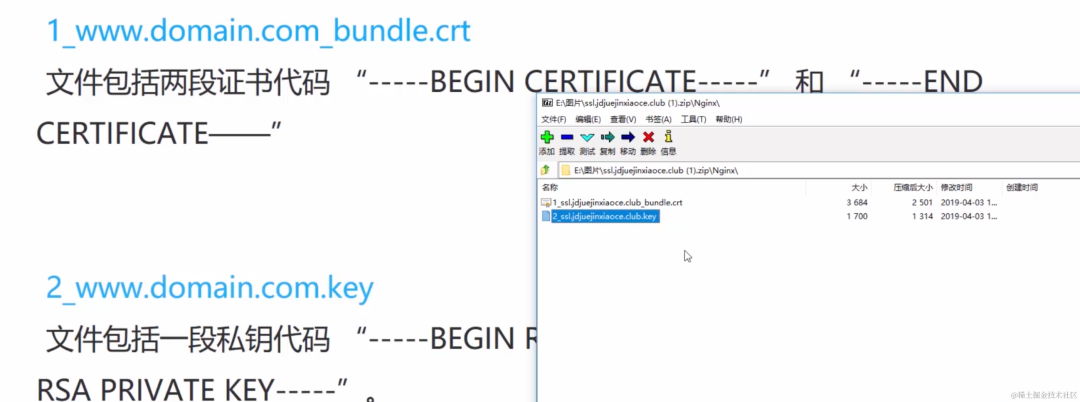
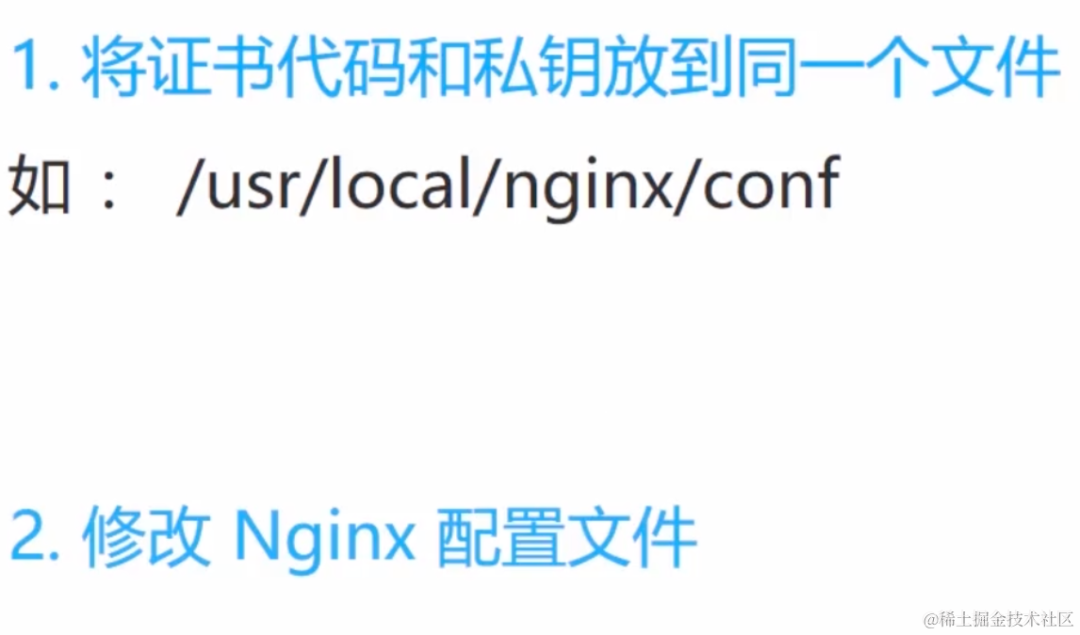
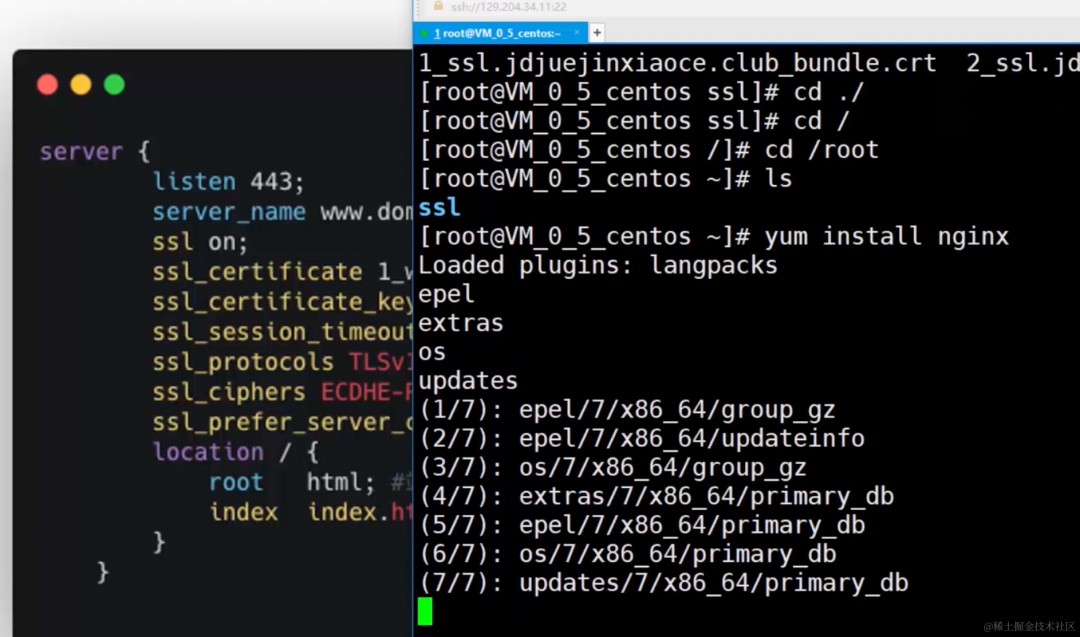
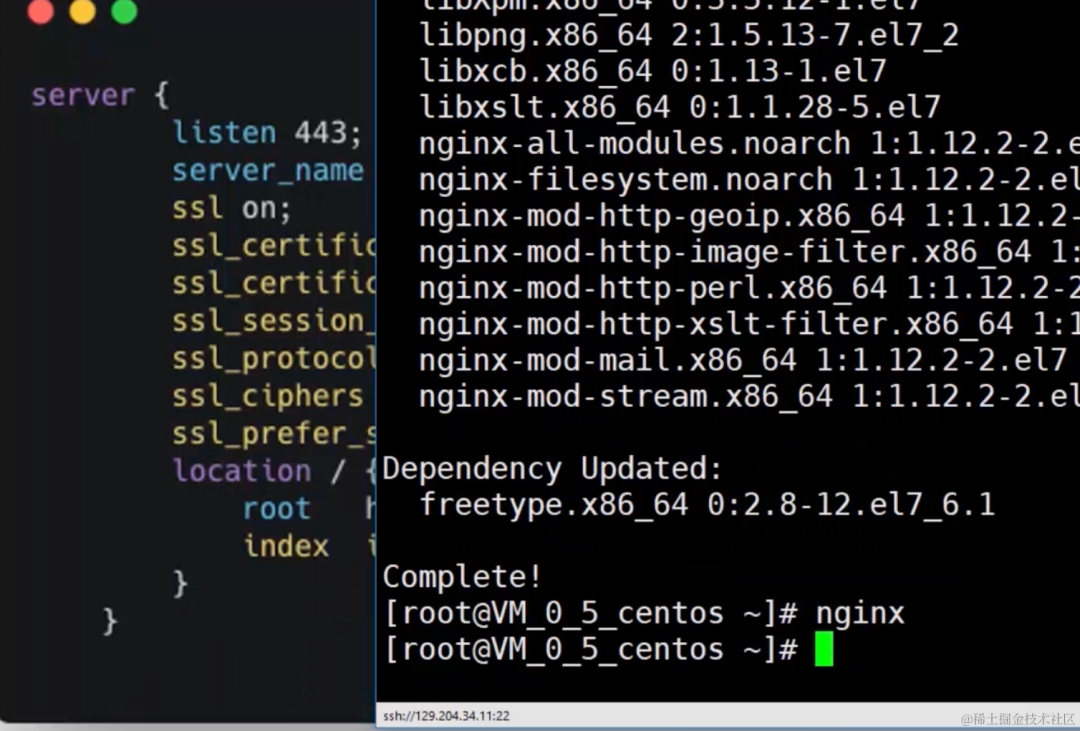
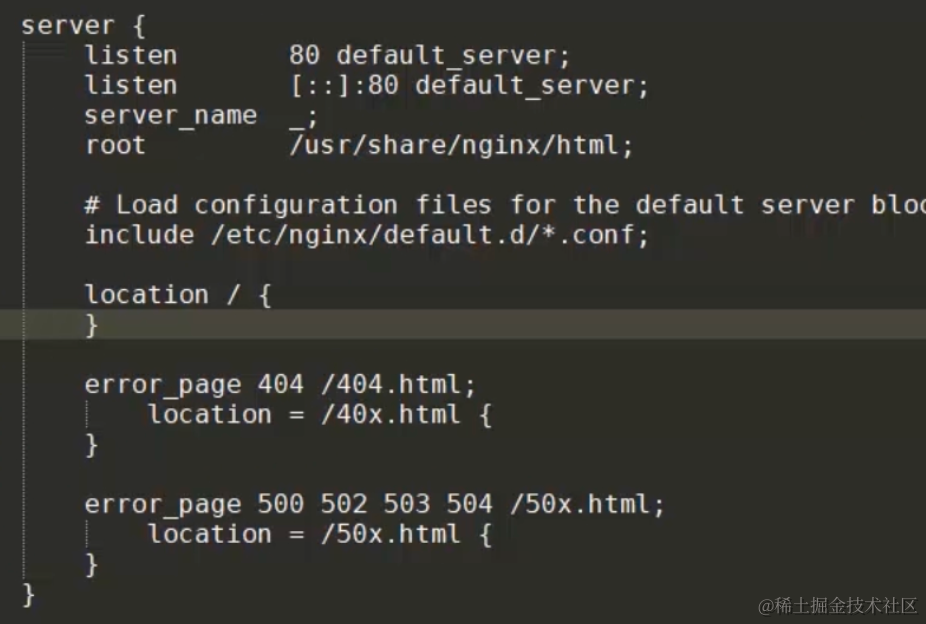
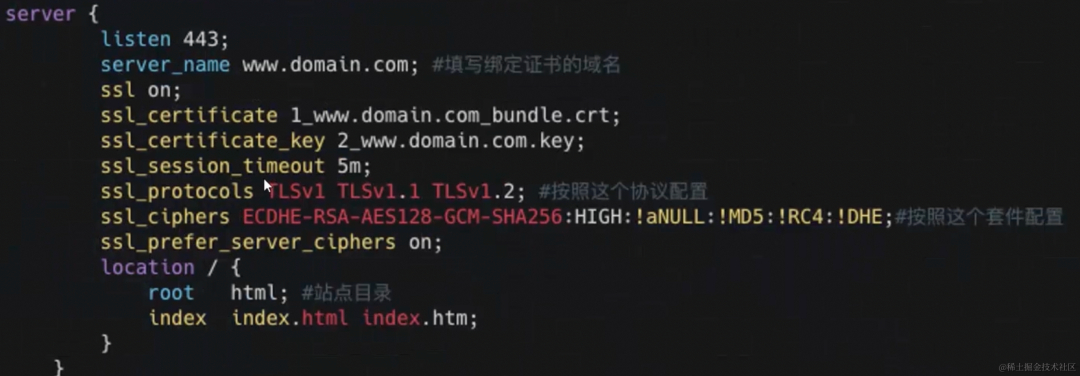




什么是单点容错率低: 单点容错率低指的是系统中存在某个关键节点,一旦这个节点发生故障或崩溃,整个系统的容错能力会显著下降。这可能导致系统无法正常运行,因为系统的其他部分可能会依赖于该节点。
什么场景无法针对不同模块进行针对性优化和水平扩展: 在某些场景中,系统的不同模块之间存在强耦合或复杂的依赖关系,导致无法对单独的模块进行优化和水平扩展。例如,如果一个系统的各个模块之间紧密耦合,修改其中一个模块可能会影响其他模块,使得无法独立扩展或优化某个特定功能。
什么是系统间耦合度变高: 系统间耦合度变高表示不同系统之间的依赖关系增加,一个系统的改动可能会对其他系统产生较大影响。这可能导致系统难以维护、升级,降低了系统的灵活性和可维护性。
如何操作使用一个调度中心对集群进行实时管理: 使用调度中心,可以通过集中管理和监控集群中的各个节点,实时获取节点的状态、资源利用率等信息。操作包括节点的动态伸缩、任务的调度与分配,以确保集群中的各项任务高效运行。
如何资源调度和治理中心(SOA Service Oriented Architecture): 在SOA中,资源调度和治理中心负责协调和管理各个服务,包括服务的注册与发现、负载均衡、流量控制等。通过中心化的资源调度和治理,可以更好地维护和监控整个服务架构。
是否有过服务间会有依赖关系,一旦某个环节出错会影响较大(服务雪崩): 是的,服务雪崩是指系统中的多个服务之间存在依赖关系,当其中一个服务出现故障时,可能引起整个系统的级联故障,导致大范围的服务不可用。为了避免服务雪崩,需要采取合适的容错机制、熔断策略和限流措施。
如何理解服务关系复杂,运维、测试部署困难 & 微服务架构比较,什么是微服务,如何做到微服务集群架构,如何做到每个服务于服务之间互不影响: 微服务是一种架构风格,将一个大型的应用程序拆分为一组小型、独立、可独立开发、部署和扩展的服务。微服务集群架构通过独立的服务单元组成整个应用,每个服务都有自己的数据库,通过轻量级的通信机制进行交互。互不影响的关键在于服务之间的独立性,服务应该定义明确的接口,通过API进行通信,使得修改一个服务不会影响其他服务。
如何理解SOA架构粒度会更加精细,SOA 架构中可能数据库存储会发生共享: SOA(面向服务的架构)的粒度较微服务更加粗,服务可能包含多个功能模块。在SOA中,服务的设计和划分更注重业务过程和功能模块的组织,数据库存储可能会共享。SOA通常采用企业服务总线(ESB)来协调和整合各个服务。
微服务强调每个服务都是单独数据库,保证每个服务于服务之间互不影响,如何做到: 为了保证每个微服务的独立性,每个服务都应该有自己的数据存储,不直接共享数据库。服务之间通过定义清晰的API进行通信,而不是直接访问数据库。这样做可以确保修改一个服务不会影响其他服务,提高了系统的可维护性和独立性。
讲解你对nacos,restful rpc dubbo feign,gateway,sentinel,skywalking的理解:
Nacos: Nacos是一个开源的服务发现、配置管理和服务管理平台,可以实现动态配置管理、服务发现和服务健康监测。
RESTful: RESTful是一种基于HTTP协议的Web服务架构风格,强调使用标准的HTTP方法和状态码进行通信。
RPC(远程过程调用): RPC是一种通过网络调用远程计算机上的程序或服务的协议,Dubbo是一种常见的RPC框架。
Feign: Feign是一个声明式的Web Service客户端,可以简化HTTP API的调用。
Gateway: Gateway是一个API网关服务,用于处理和路由请求,提供负载均衡、安全性和监控等功能。
Sentinel: Sentinel是一款开源的流量控制和服务保护框架,用于应对分布式系统中的流量突增和服务异常。
SkyWalking: SkyWalking
网页是通过 HTTPS 加密协议加载的,但是尝试连接到不安全的 WebSocket 地址 'ws://',而不是安全的 WebSocket 地址 'wss:///r'。
浏览器强制执行同源策略,要求在加载通过 HTTPS 加密协议的网页时,所有的资源请求也必须通过 HTTPS。由于 WebSocket 连接是通过 JavaScript 代码发起的,浏览器会阻止不安全的 WebSocket 连接,以确保安全性。
解决方法是确保 WebSocket 连接也使用安全的 'wss' 协议,而不是 'ws'。确保你的服务器支持安全的 WebSocket 连接,同时确保在代码中使用的 WebSocket 地址是 ''。这样就能解决混合内容错误。
DOMException: Failed to construct 'WebSocket':不安全的WebSocket连接可能无法从通过HTTPS加载的页面启动。

使用GIF上报的原因
向服务器端上报数据,可以通过请求接口,请求普通文件,或者请求图片资源的方式进行。只要能上报数据,无论是请求GIF文件还是请求js文件或者是调用页面接口,服务器端其实并不关心具体的上报方式。那为什么所有系统都统一使用了请求GIF图片的方式上报数据呢?
防止跨域
一般而言,打点域名都不是当前域名,所以所有的接口请求都会构成跨域。而跨域请求很容易出现由于配置不当被浏览器拦截并报错,这是不能接受的。但图片的src属性并不会跨域,并且同样可以发起请求。(排除接口上报)
防止阻塞页面加载,影响用户体验
通常,创建资源节点后只有将对象注入到浏览器DOM树后,浏览器才会实际发送资源请求。反复操作DOM不仅会引发性能问题,而且载入js/css资源还会阻塞页面渲染,影响用户体验。
但是图片请求例外。构造图片打点不仅不用插入DOM,只要在js中new出Image对象就能发起请求,而且还没有阻塞问题,在没有js的浏览器环境中也能通过img标签正常打点,这是其他类型的资源请求所做不到的。(排除文件方式)
相比PNG/JPG,GIF的体积最小
最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节。
同样的响应,GIF可以比BMP节约41%的流量,比PNG节约35%的流量。
PerformanceTiming.navigationStart是一个无符号long long 型的毫秒数,表征了从同一个浏览器上下文的上一个文档卸载(unload)结束时的UNIX时间戳。如果没有上一个文档,这个值会和PerformanceTiming.fetchStart相同。
PerformanceTiming.unloadEventStart是一个无符号long long 型的毫秒数,表征了
unload事件抛出时的UNIX时间戳。如果没有上一个文档,or if the previous document, or one of the needed redirects, is not of the same origin, 这个值会返回0.PerformanceTiming.unloadEventEnd是一个无符号long long 型的毫秒数,表征了
unload事件处理完成时的UNIX时间戳。如果没有上一个文档,or if the previous document, or one of the needed redirects, is not of the same origin, 这个值会返回0.PerformanceTiming.redirectStart是一个无符号long long 型的毫秒数,表征了第一个HTTP重定向开始时的UNIX时间戳。如果没有重定向,或者重定向中的一个不同源,这个值会返回0.
PerformanceTiming.redirectEnd是一个无符号long long 型的毫秒数,表征了最后一个HTTP重定向完成时(也就是说是HTTP响应的最后一个比特直接被收到的时间)的UNIX时间戳。如果没有重定向,或者重定向中的一个不同源,这个值会返回0.
PerformanceTiming.fetchStart是一个无符号long long 型的毫秒数,表征了浏览器准备好使用HTTP请求来获取(fetch)文档的UNIX时间戳。这个时间点会在检查任何应用缓存之前。
PerformanceTiming.domainLookupStart是一个无符号long long 型的毫秒数,表征了域名查询开始的UNIX时间戳。如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和
PerformanceTiming.fetchStart一致。PerformanceTiming.domainLookupEnd是一个无符号long long 型的毫秒数,表征了域名查询结束的UNIX时间戳。如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和
PerformanceTiming.fetchStart一致。PerformanceTiming.connectStart是一个无符号long long 型的毫秒数,返回HTTP请求开始向服务器发送时的Unix毫秒时间戳。如果使用持久连接(persistent connection),则返回值等同于fetchStart属性的值。
PerformanceTiming.connectEnd是一个无符号long long 型的毫秒数,返回浏览器与服务器之间的连接建立时的Unix毫秒时间戳。如果建立的是持久连接,则返回值等同于fetchStart属性的值。连接建立指的是所有握手和认证过程全部结束。
PerformanceTiming.secureConnectionStart是一个无符号long long 型的毫秒数,返回浏览器与服务器开始安全链接的握手时的Unix毫秒时间戳。如果当前网页不要求安全连接,则返回0。
PerformanceTiming.requestStart是一个无符号long long 型的毫秒数,返回浏览器向服务器发出HTTP请求时(或开始读取本地缓存时)的Unix毫秒时间戳。
PerformanceTiming.responseStart是一个无符号long long 型的毫秒数,返回浏览器从服务器收到(或从本地缓存读取)第一个字节时的Unix毫秒时间戳。如果传输层在开始请求之后失败并且连接被重开,该属性将会被数制成新的请求的相对应的发起时间。
PerformanceTiming.responseEnd是一个无符号long long 型的毫秒数,返回浏览器从服务器收到(或从本地缓存读取,或从本地资源读取)最后一个字节时(如果在此之前HTTP连接已经关闭,则返回关闭时)的Unix毫秒时间戳。
PerformanceTiming.domLoading是一个无符号long long 型的毫秒数,返回当前网页DOM结构开始解析时(即
Document.readyState属性变为“loading”、相应的readystatechange事件触发时)的Unix毫秒时间戳。PerformanceTiming.domInteractive是一个无符号long long 型的毫秒数,返回当前网页DOM结构结束解析、开始加载内嵌资源时(即
Document.readyState属性变为“interactive”、相应的readystatechange事件触发时)的Unix毫秒时间戳。PerformanceTiming.domContentLoadedEventStart是一个无符号long long 型的毫秒数,返回当解析器发送
DOMContentLoaded事件,即所有需要被执行的脚本已经被解析时的Unix毫秒时间戳。PerformanceTiming.domContentLoadedEventEnd是一个无符号long long 型的毫秒数,返回当所有需要立即执行的脚本已经被执行(不论执行顺序)时的Unix毫秒时间戳。
PerformanceTiming.domComplete是一个无符号long long 型的毫秒数,返回当前文档解析完成,即
Document.readyState变为'complete'且相对应的``readystatechange被触发时的Unix毫秒时间戳。PerformanceTiming.loadEventStart是一个无符号long long 型的毫秒数,返回该文档下,
load事件被发送时的Unix毫秒时间戳。如果这个事件还未被发送,它的值将会是0。PerformanceTiming.loadEventEnd是一个无符号long long 型的毫秒数,返回当
load事件结束,即加载事件完成时的Unix毫秒时间戳。如果这个事件还未被发送,或者尚未完成,它的值将会是0.
1.区间阶段耗时
DNS 解析耗时
dns: timing.domainLookupEnd - timing.domainLookupStartTCP 连接耗时
tcp: timing.connectEnd - timing.connectStartSSL 安全连接耗时
ssl: timing.connectEnd - timing.secureConnectionStartTime to First Byte(TTFB),网络请求耗时 TTFB 有多种计算方式,ARMS 以 Google Development 定义为准
ttfb: timing.responseStart - timing.requestStart数据传输耗时
trans: timing.responseEnd - timing.responseStartDOM 解析耗时
dom: timing.domInteractive - timing.responseEnd资源加载耗时
res: timing.loadEventStart - timing.domContentLoadedEventEnd2.关键性能指标
首包时间
firstbyte: timing.responseStart - timing.domainLookupStartFirst Paint Time, 首次渲染时间 / 白屏时间
fpt: timing.responseEnd - timing.fetchStartTime to Interact,首次可交互时间
tti: timing.domInteractive - timing.fetchStartHTML 加载完成时间, 即 DOM Ready 时间
ready: timing.domContentLoadedEventEnd - timing.fetchStart页面完全加载时间
load:timing.loadEventEnd - timing.fetchStart<template>
<input
type="file"
id="myFile"
ref="file"
@change="handleUpload($event)"
accept=".pdf" <!-- 限制文件类型为 PDF -->
/>
</template>
<script>
export default {
methods: {
handleUpload(event) {
const fileInput = event.target;
const file = fileInput.files[0];
if (!file) {
return; // 用户取消选择文件
}
// 检查文件类型
if (file.type !== "application/pdf") {
alert("请选择 PDF 文件");
fileInput.value = ""; // 清空文件选择框
return;
}
// 检查文件大小
const maxSize = 5 * 1024 * 1024; // 5MB
if (file.size > maxSize) {
alert("文件大小不能超过 5MB");
fileInput.value = ""; // 清空文件选择框
return;
}
// 执行上传文件的操作
// 这里可以调用你的上传文件的函数
// this.uploadFile(file);
},
},
};
</script>QPS 是 "Queries Per Second"(每秒查询数)的缩写。它是衡量系统性能的一个指标,表示系统每秒能够处理的查询或请求的数量。QPS 常用于衡量一个服务、系统或网络设备的性能,特别是在涉及到大量请求的网络服务中,QPS 是一个重要的性能指标。
高 QPS 值通常表示系统能够高效地处理大量请求,而低 QPS 值可能意味着系统性能不足,无法满足用户或客户端的需求。QPS 的具体值取决于系统的设计、硬件性能、网络状况等多个因素。
在一些场景中,特别是在互联网服务、数据库、缓存等领域,QPS 是评估系统性能的重要标准之一。维护一个较高的 QPS 对于确保系统的高可用性和稳定性至关重要。
<project.build.sourceEncoding>指定了项目的源代码编码为 UTF-8。<project.reporting.outputEncoding>指定了项目报告的输出编码为 UTF-8。<java.version>指定了项目使用的 Java 版本为 1.8。
这是 Maven 项目的 pom.xml 文件中的 <parent> 元素,用于指定 Spring Boot 项目的父级。Spring Boot 提供了一个用于简化构建的 Maven POM 文件,称为 "spring-boot-starter-parent"。
具体来说:
<groupId>指定了 Maven 组织的标识符,这里是 "org.springframework.boot",表示 Spring Boot 组织。<artifactId>指定了 Maven 构件的标识符,这里是 "spring-boot-starter-parent",表示 Spring Boot 父级构建。<version>指定了 Spring Boot 父级构建的版本号,这里是 "2.3.2.RELEASE",表示使用的 Spring Boot 版本。
通过引入 Spring Boot 父级,你可以继承其配置和依赖管理,使得构建 Spring Boot 项目更加简便。
<dependencyManagement>元素用于集中管理项目的依赖版本,以确保项目中的所有模块使用相同的依赖版本。<dependencies>元素包含了需要进行版本管理的依赖项。对于 Spring Cloud,通过
<dependency>元素引入了 "spring-cloud-dependencies" POM,用于管理 Spring Cloud 相关的依赖。<groupId>指定了 Maven 组织的标识符,这里是 "org.springframework.cloud"。<artifactId>指定了 Maven 构件的标识符,这里是 "spring-cloud-dependencies"。<version>指定了 Spring Cloud 的版本号,这里是 "Hoxton.SR9"。<type>指定了依赖的类型,这里是 "pom",表示引入的是一个 POM 文件。<scope>指定了依赖的范围,这里是 "import",表示引入的 POM 文件仅用于版本管理,不会导入实际的依赖。
同样,对于 Spring Cloud Alibaba,通过
<dependency>元素引入了 "spring-cloud-alibaba-dependencies" POM,用于管理 Spring Cloud Alibaba 相关的依赖。<groupId>指定了 Maven 组织的标识符,这里是 "com.alibaba.cloud"。<artifactId>指定了 Maven 构件的标识符,这里是 "spring-cloud-alibaba-dependencies"。<version>指定了 Spring Cloud Alibaba 的版本号,这里是 "2.2.6.RELEASE"。<type>指定了依赖的类型,这里同样是 "pom"。<scope>指定了依赖的范围,这里同样是 "import"。
这是 Maven 项目的 pom.xml 文件中的一些依赖配置,主要包括 Spring Boot、Spring Web、Spring Kafka 和 Spring Boot Starter for Redis 的依赖。
<dependency>元素用于定义项目的依赖。<groupId>指定了 Maven 组织的标识符,表示依赖的组织。<artifactId>指定了 Maven 构件的标识符,表示依赖的具体模块或库。没有指定
<version>元素的情况下,Maven 会使用<dependencyManagement>中的版本管理进行版本控制。
具体来说:
<dependency>元素引入了 Spring Boot 项目的核心依赖,spring-boot模块。<dependency>元素引入了 Spring Boot Starter for Web,用于支持构建 Web 应用。<dependency>元素引入了 Spring Kafka,用于支持与 Apache Kafka 集成。<dependency>元素引入了 Spring Boot Starter for Redis,用于支持与 Redis 数据库集成。<dependency>元素引入了 Spring Boot Starter for AOP,用于支持面向切面编程(AOP)。<dependency>元素引入了 Spring Boot Starter for Logging,用于支持日志功能。通常情况下,它会包括 Spring Boot 默认的日志实现,例如 Logback。<dependency>元素引入了 Spring Cloud Starter for OpenFeign,用于支持声明式的 HTTP 客户端(Feign)。<dependency>元素引入了 Spring Cloud Starter Netflix Ribbon,用于支持客户端负载均衡(Ribbon)。<dependency>元素引入了 Spring Cloud Alibaba Nacos Discovery 的 Starter,用于支持基于 Nacos 的服务注册和发现。在这里,通过<exclusions>元素排除了对com.alibaba.nacos下的nacos-client的传递性依赖。这可能是因为项目中已经有自定义的版本或是其他原因。<dependency>元素引入了 Alibaba 的 EasyExcel 库,版本为 3.1.1。EasyExcel 是一个用于操作 Excel 文件的 Java 库,它提供了方便的 API,支持读取、写入 Excel 文件,并且易于使用。<dependency>元素引入了 MyBatis Spring Boot Starter,版本为 2.1.0。这是 MyBatis 框架与 Spring Boot 集成的 Starter,简化了 MyBatis 在 Spring Boot 项目中的配置。<dependency>元素引入了 PageHelper,版本为 5.1.3。PageHelper 是一个用于 MyBatis 的分页插件,能够方便地对查询结果进行分页处理。<dependency>元素引入了通用 Mapper,版本为 3.4.6。通用 Mapper 是一个 MyBatis 插件,它提供了一种简单的方式来处理 MyBatis 的 CRUD 操作,无需手动编写 SQL。<dependency>元素引入了 Druid 数据库连接池,版本为 1.1.12。Druid 是一个开源的、高性能的数据库连接池,支持监控和扩展功能。<dependency>元素引入了 Jedis,该库是 Redis 的 Java 客户端。通过 Jedis,你可以在 Java 项目中方便地与 Redis 数据库进行交互。<dependency>元素引入了 springfox-swagger2,版本为 2.7.0。Swagger 是一个用于设计、构建、文件和使用 RESTful API 的工具。Springfox 是 Swagger 在 Spring Boot 项目中的实现,可以生成 API 文档,方便进行 API 的测试和文档查看。<dependency>元素引入了 springfox-swagger-ui,版本为 2.7.0。Swagger UI 是 Swagger 生成的 API 文档的用户界面,它允许用户直观地查看和测试 API。<dependency>元素引入了 knife4j-spring-boot-starter,版本为 2.0.4。Knife4j 是 Swagger 的增强工具,提供了更多的界面展示和交互功能,使 API 文档更加友好。<dependency>元素引入了 mysql-connector-java,版本为 5.1.48。这是 MySQL 数据库的 Java 连接器,用于在 Java 项目中与 MySQL 数据库进行连接和交互。<dependency>元素引入了org.apache.httpcomponents:httpclient,版本为 4.5.12。这是 Apache HttpClient 库,用于在 Java 中进行 HTTP 请求和处理响应。<dependency>元素引入了org.apache.httpcomponents:httpmime,版本为 4.5.12。这是 Apache HttpClient 的 MIME 扩展,提供了对 MIME 类型的支持,通常用于处理文件上传等场景。<dependency>元素引入了com.google.code.gson:gson,版本为 2.8.5。Gson 是 Google 提供的用于在 Java 对象和 JSON 数据之间进行转换的库。在项目中,它常用于处理 JSON 数据的序列化和反序列化。<dependency>元素引入了 Lombok(org.projectlombok:lombok,版本 1.18.8)。Lombok 是一个 Java 库,通过注解简化了 Java 代码,提供了诸如自动生成 Getter/Setter、构造函数等功能,从而减少了冗长的代码。在使用 Lombok 的项目中,你可以使用注解来自动生成一些常用的 Java 代码,提高代码的简洁性和可读性。<dependency>元素引入了 Apache Commons Lang3(org.apache.commons:commons-lang3,版本 3.9)。这是 Apache Commons 中的一个项目,提供了许多用于操作字符串、集合、日期等的工具类。Commons Lang3 为 Java 开发人员提供了许多实用的工具方法,用于简化常见任务。<dependency>元素引入了 DataStax Cassandra 驱动(com.datastax.cassandra:cassandra-driver-core,版本 3.1.2)。这是与 Apache Cassandra 数据库交互的 Java 驱动程序。它允许 Java 应用程序与 Cassandra 数据库进行通信,执行查询并处理结果。<dependency>元素引入了 Codahale Metrics(com.codahale.metrics:metrics-core,版本 3.0.2)。Codahale Metrics 是一个用于度量应用程序性能的 Java 库。它提供了一组度量工具和报告工具,用于监视应用程序的各个方面,例如吞吐量、延迟、错误率等。<dependency>元素引入了 Google Guava(com.google.guava:guava,版本 18.0)。Guava 是 Google 提供的一个开源 Java 核心库,包含许多实用的工具类和数据结构。它提供了诸如集合框架、并发工具、缓存、字符串处理等功能,以帮助开发者更轻松地编写高效且可读性强的 Java 代码。<dependency>元素引入了 Elasticsearch 客户端 Transport 模块(org.elasticsearch.client:transport,版本 7.11.2)。这是与 Elasticsearch 服务器进行通信的 Java 客户端库。它使 Java 应用程序能够执行与 Elasticsearch 集群的交互,包括索引、搜索等操作。在这个依赖中,<exclusions>元素用于排除与commons-logging相关的传递性依赖。<dependency>元素引入了 Apache Commons Lang(org.apache.commons:commons-lang3,版本 3.9)。Commons Lang 提供了许多用于处理字符串、集合、异常等的实用工具类,以简化 Java 编程。<dependency>元素引入了 Apache Commons Collections(commons-collections:commons-collections,版本 3.2.1)。Commons Collections 提供了一组扩展了 Java 标准集合框架的实用类,例如列表、映射、队列等。<dependency>元素引入了 Nacos 客户端库(com.alibaba.nacos:nacos-client)。Nacos 是一个动态服务发现和配置管理工具,用于构建和维护微服务架构中的服务注册、发现和配置的功能。<dependency>元素引入了 Elasticsearch 客户端库(org.elasticsearch:elasticsearch,版本 7.11.2)。这是 Elasticsearch 的官方 Java 客户端库,允许 Java 应用程序与 Elasticsearch 集群进行交互,执行索引、搜索等操作。
<groupId>:org.elasticsearch.client,指定依赖项的组织标识符,表示 Elasticsearch 客户端库的一部分。<artifactId>:transport,指定依赖项的项目标识符,表示 Elasticsearch 客户端库的transport模块,该模块用于与 Elasticsearch 集群进行通信。<version>:7.11.2,指定了依赖项的版本号,表示所使用的 Elasticsearch 客户端库的版本。<exclusions>:用于排除传递性依赖。在这里,排除了commons-logging这个传递性依赖,表示不引入commons-logging库。
Elasticsearch 相关依赖:
<groupId>:org.elasticsearch.plugin,这个依赖用于 Elasticsearch 的插件,特别是transport-netty4-client插件,提供与 Elasticsearch 集群的通信。<artifactId>:transport-netty4-client,指定了 Elasticsearch 插件的项目标识符。<version>:7.11.2,表示所使用的 Elasticsearch 插件的版本。<groupId>:org.elasticsearch.client,这个依赖用于 Elasticsearch 的 REST 客户端,提供与 Elasticsearch 集群的通信。<artifactId>:elasticsearch-rest-client,指定了 Elasticsearch REST 客户端的项目标识符。<version>:7.11.2,表示所使用的 Elasticsearch REST 客户端的版本。
ClickHouse 相关依赖:
<groupId>:ru.yandex.clickhouse,指定 ClickHouse JDBC 驱动的组织标识符。<artifactId>:clickhouse-jdbc,指定 ClickHouse JDBC 驱动的项目标识符。<version>:0.2.4,表示所使用的 ClickHouse JDBC 驱动的版本。
Elasticsearch REST 高级客户端依赖:
<groupId>:org.elasticsearch.client,这个依赖用于 Elasticsearch 的 REST 高级客户端,提供更高级别的抽象,以简化与 Elasticsearch 集群的交互。<artifactId>:elasticsearch-rest-high-level-client,指定了 Elasticsearch REST 高级客户端的项目标识符。<version>:7.11.2,表示所使用的 Elasticsearch REST 高级客户端的版本。
FastJSON 依赖:
<groupId>:com.alibaba,这个依赖用于 FastJSON,它是一个用于 Java 的 JSON 处理库,由阿里巴巴开发和维护。<artifactId>:fastjson,指定了 FastJSON 库的项目标识符。<version>:1.2.75,表示所使用的 FastJSON 库的版本。<scope>:compile,表示这个依赖在编译期和运行期都可用。
<plugin>:指定 Maven 插件的配置块。<groupId>:org.apache.maven.plugins,Maven 插件的 Group ID,表示插件的来源组织。<artifactId>:maven-jar-plugin,Maven 插件的 Artifact ID,标识插件的具体实现。<version>:2.4,Maven 插件的版本号,指定所使用的插件版本。<configuration>:用于指定插件的配置信息。<archive>:用于配置 JAR 文件的归档信息。<manifest>:用于配置 JAR 文件的 MANIFEST.MF 文件。<addClasspath>:设置为true,将构建的 JAR 文件的 MANIFEST.MF 文件中包含类路径信息。<classpathPrefix>:设置为lib/,指定类路径的前缀。<mainClass>:指定了应用程序的主类,即启动 JAR 文件时运行的主类。<plugin>:指定 Maven 插件的配置块。<groupId>:org.apache.maven.plugins,Maven 插件的 Group ID,表示插件的来源组织。<artifactId>:maven-jar-plugin,Maven 插件的 Artifact ID,标识插件的具体实现。<version>:2.4,Maven 插件的版本号,指定所使用的插件版本。<configuration>:用于指定插件的配置信息。<archive>:用于配置 JAR 文件的归档信息。<manifest>:用于配置 JAR 文件的 MANIFEST.MF 文件。<addClasspath>:设置为true,将构建的 JAR 文件的 MANIFEST.MF 文件中包含类路径信息。<classpathPrefix>:设置为lib/,指定类路径的前缀。<mainClass>:指定了应用程序的主类,即启动 JAR 文件时运行的主类。<plugin>:指定 Maven 插件的配置块。<groupId>:org.apache.maven.plugins,Maven 插件的 Group ID,表示插件的来源组织。<artifactId>:maven-dependency-plugin,Maven 插件的 Artifact ID,标识插件的具体实现。<version>:3.3.0,Maven 插件的版本号,指定所使用的插件版本。<executions>:用于配置插件执行的一系列任务。<execution>:表示一个具体的插件执行任务。<id>:copy,指定任务的唯一标识符。<phase>:package,指定了在 Maven 生命周期的哪个阶段执行该任务。在这里,是在打包阶段执行。<goals>:配置在指定阶段执行的目标(goal)。<goal>:copy-dependencies,表示执行 Dependency 插件的copy-dependencies目标。<configuration>:用于指定插件执行的配置信息。<outputDirectory>:指定依赖项复制的输出目录,这里是${project.build.directory}/lib,即 target 目录下的 lib 子目录。<excludeTransitive>:设置为false,表示不排除传递性依赖。<stripVersion>:设置为false,表示不剥离依赖项的版本信息。<includeScope>:runtime,表示只包括运行时(runtime)范围的依赖项。
一个处理 Microsoft Office 格式文件(如Word和Excel)的强大工具。"POI" 也可能指代 Apache POI
频繁的输入输出 (I/O) 操作可能导致性能问题的原因有几个:
阻塞:I/O 操作通常是阻塞的,即程序在等待数据读取或写入时会被阻塞。如果你的程序频繁进行 I/O 操作,可能会导致大量的等待时间,从而影响整体性能。
资源竞争:如果多个线程或进程同时竞争相同的 I/O 资源,可能会导致资源竞争问题,例如争夺文件读写锁。这会引起性能下降和潜在的数据一致性问题。
上下文切换:频繁的 I/O 操作可能导致系统频繁进行线程或进程的上下文切换,这是由于 I/O 操作的等待时间,切换上下文本身也会带来开销。
磁盘寻址延迟:对于磁盘 I/O,频繁的读写操作可能受到磁盘寻址延迟的影响。机械硬盘需要进行磁头寻址,而这个过程可能比较慢,尤其是在大量随机读写的情况下。
缓存未命中:如果数据无法从缓存中获取,每次都需要从磁盘或网络中读取数据,会增加访问时间。
解决频繁 I/O 操作导致性能问题的方法包括:
异步 I/O:使用异步 I/O 操作可以在等待数据就绪的同时执行其他任务,提高效率。
缓存:对于重复读取的数据,可以使用缓存来减少对外部存储的依赖。
优化文件操作:如果是文件 I/O,可以考虑对文件的读写进行优化,减少不必要的文件访问。
并发控制:合理地控制并发访问,避免资源竞争问题。
使用更高效的存储设备:使用固态硬盘等更快速的存储设备可以降低磁盘寻址延迟。
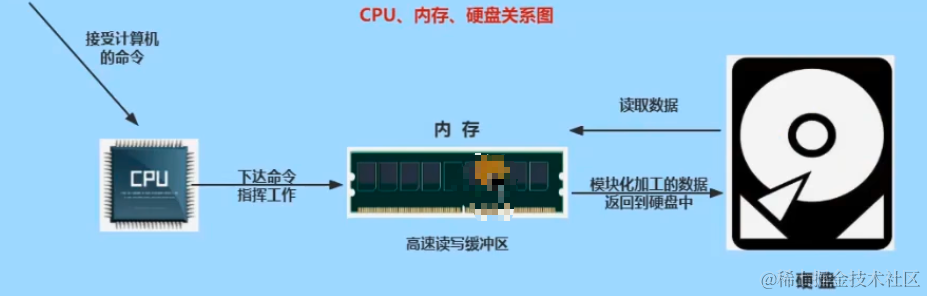
计算机组成:
物理层面:计算机硬件:CPU,内存,存储设备(磁盘,光盘,磁带),输入设备(键盘,鼠标),输出设备(显示器,打印机),通信设备(调制解调器,网卡)




加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview
更多【spring-springboot第46集:Nginx,Sentinel,计算机硬件的介绍】相关视频教程:www.yxfzedu.com
相关文章推荐
- python-前端面试题 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何合并多次的本地提交进行 Push - 其他
- 音视频-中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载 - 其他
- node.js-npm install:sill idealTree buildDeps - 其他
- 编辑器-vscode 访问本地或者远程docker环境 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何找回被 Drop Commit 的提交记录 - 其他
- 算法-力扣第1035题 不相交的线中等 c++ (最长公共子序列) 动态规划 附Java代码 - 其他
- java-JavaWeb课程复习资料——idea创建JDBC - 其他
- python-Python---列表的循环遍历,嵌套 - 其他
- python-Python的版本如何查询? - 其他
- java-IDEA 函数下边出现红色的波浪线,提示报错 - 其他
- 算法-算法通关村第八关|白银|二叉树的深度和高度问题【持续更新】 - 其他
- 算法-C现代方法(第19章)笔记——程序设计 - 其他
- git-IntelliJ Idea 撤回git已经push的操作 - 其他
- c#-html导出word - 其他
- excel-使用 AIGC ,ChatGPT 快速合并Excel工作薄 - 其他
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 - 其他
- 编程技术-鲁大师电动车智能化测评报告第二十三期:实测续航95km,九号Q90兼顾个性与实用 - 其他
- 数据库-进阶SQL——数据表中多列按照指定格式拼接,并将多行内容合并为map拼接 - 其他
- 小程序-社区团购小程序系统源码+各种快递代收+社区便利店 带完整的搭建教程 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
