外文翻译-【BlackHat】结构化模糊测试,议题学习
推荐 原创
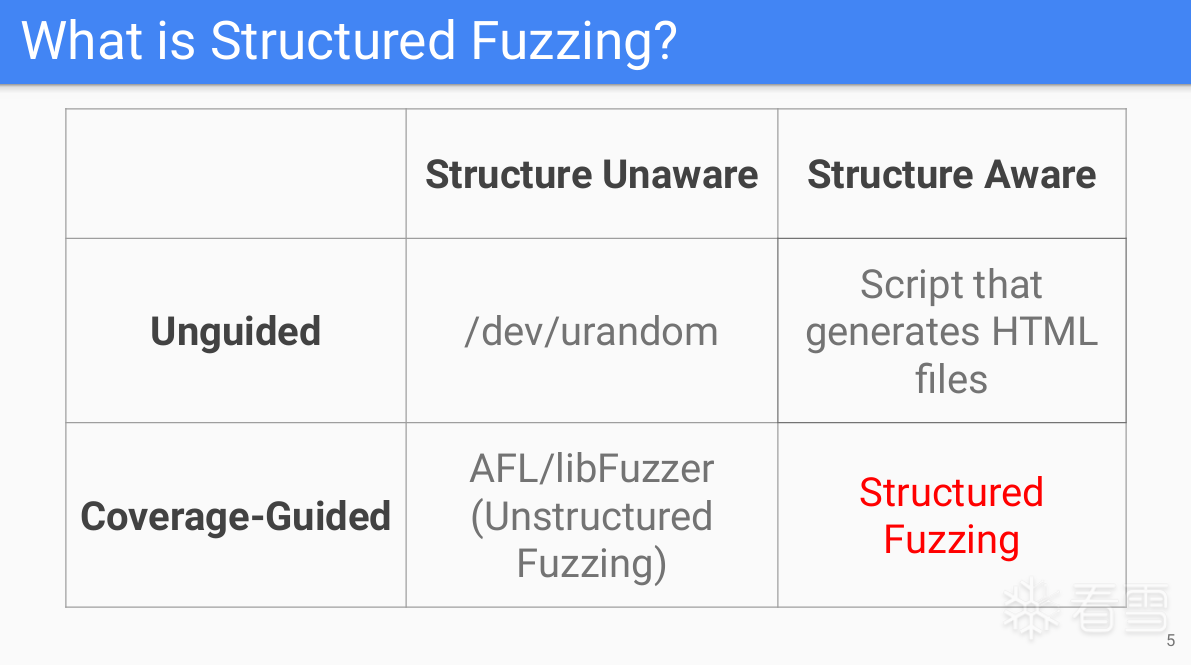
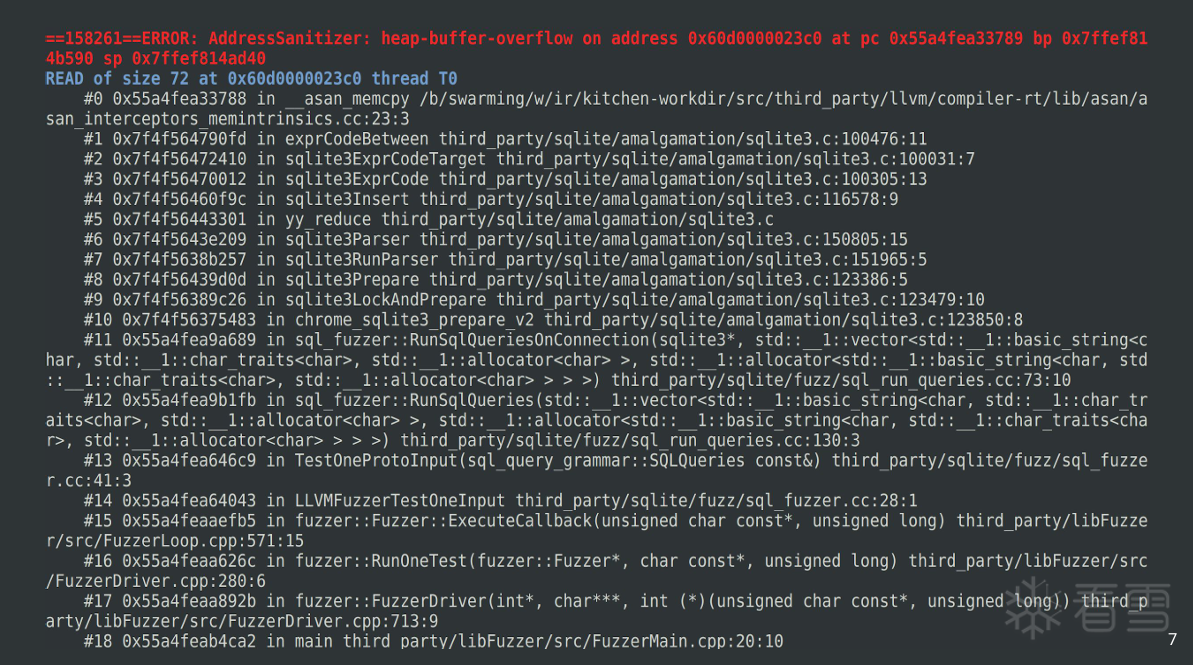
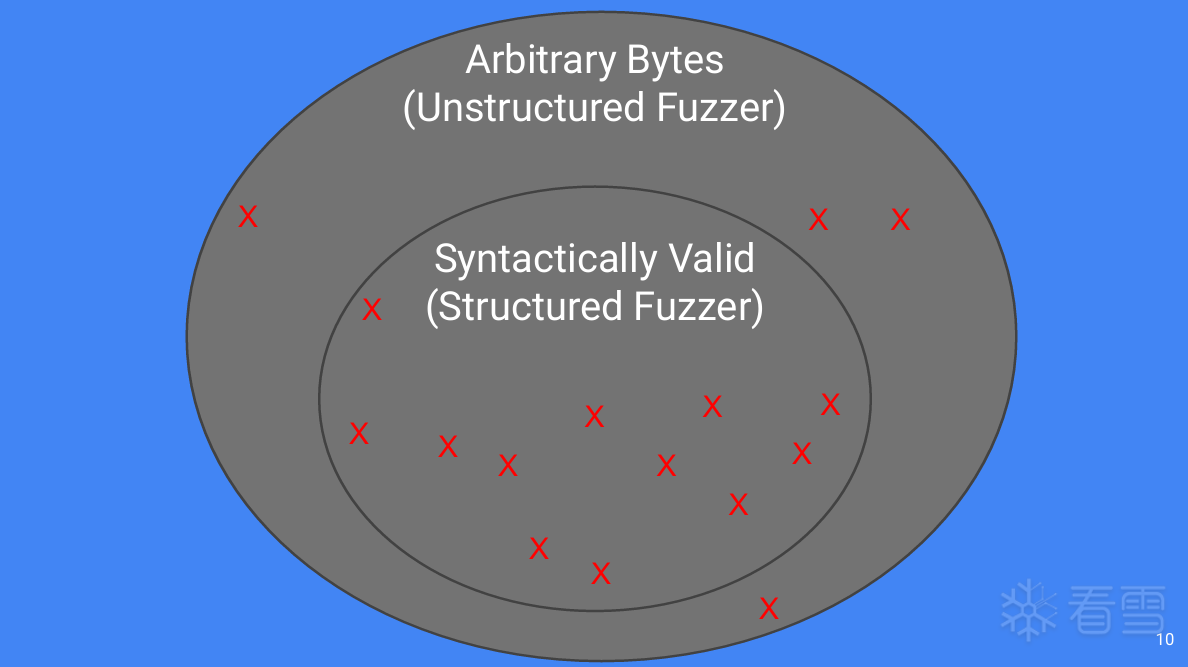
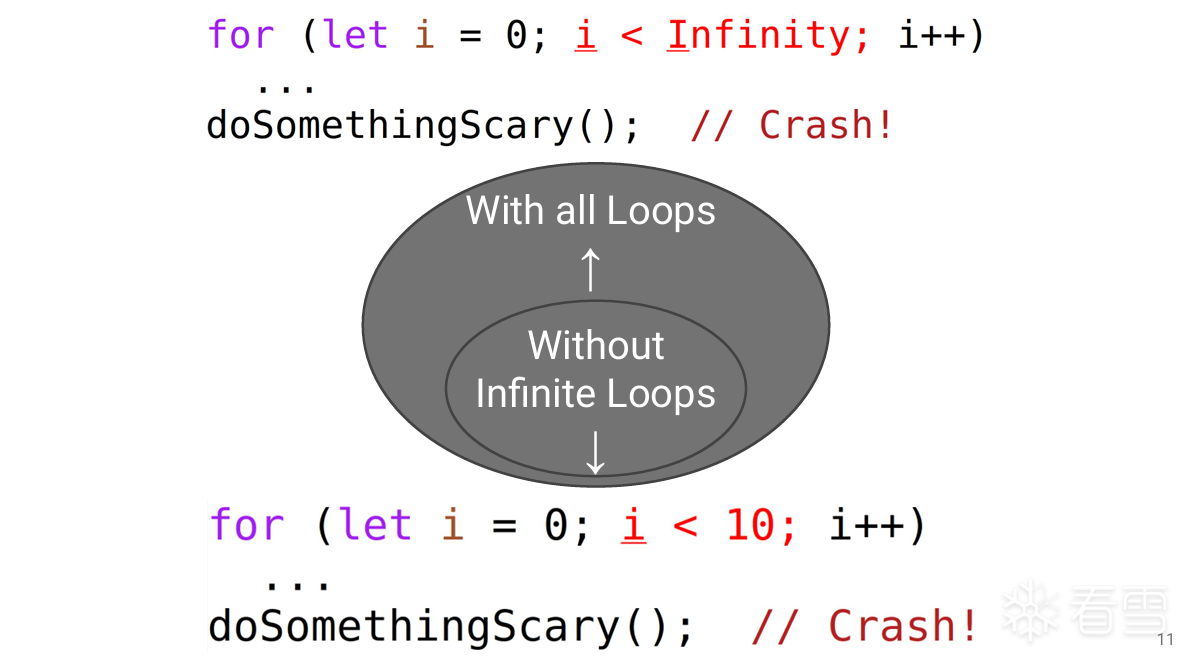
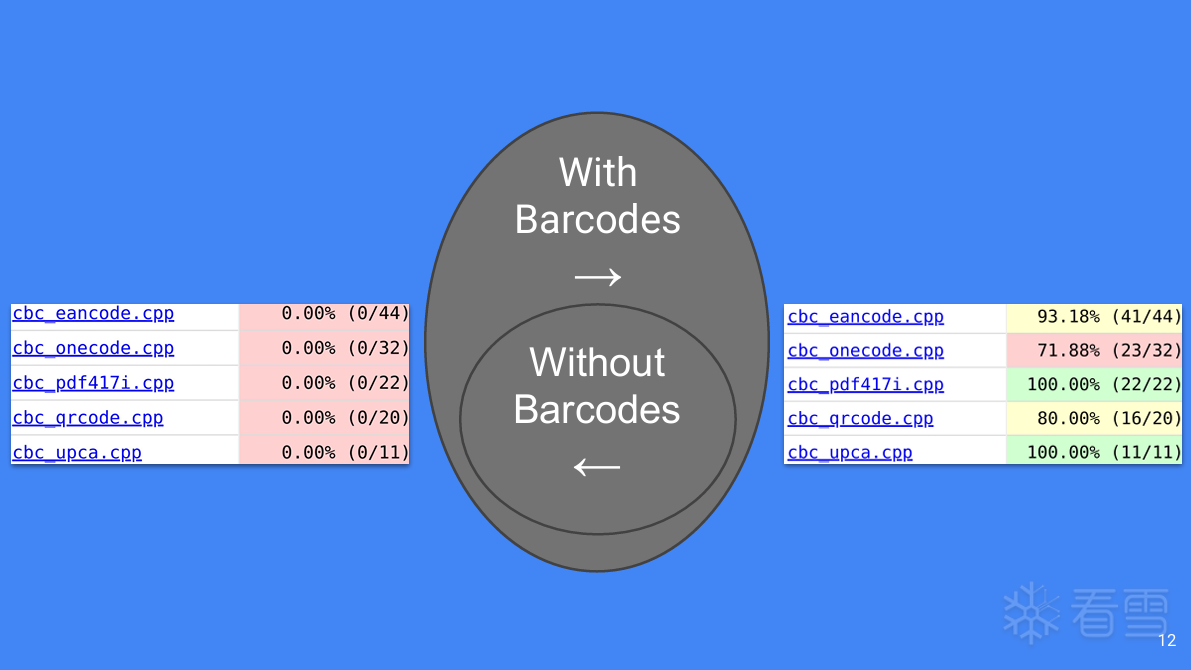

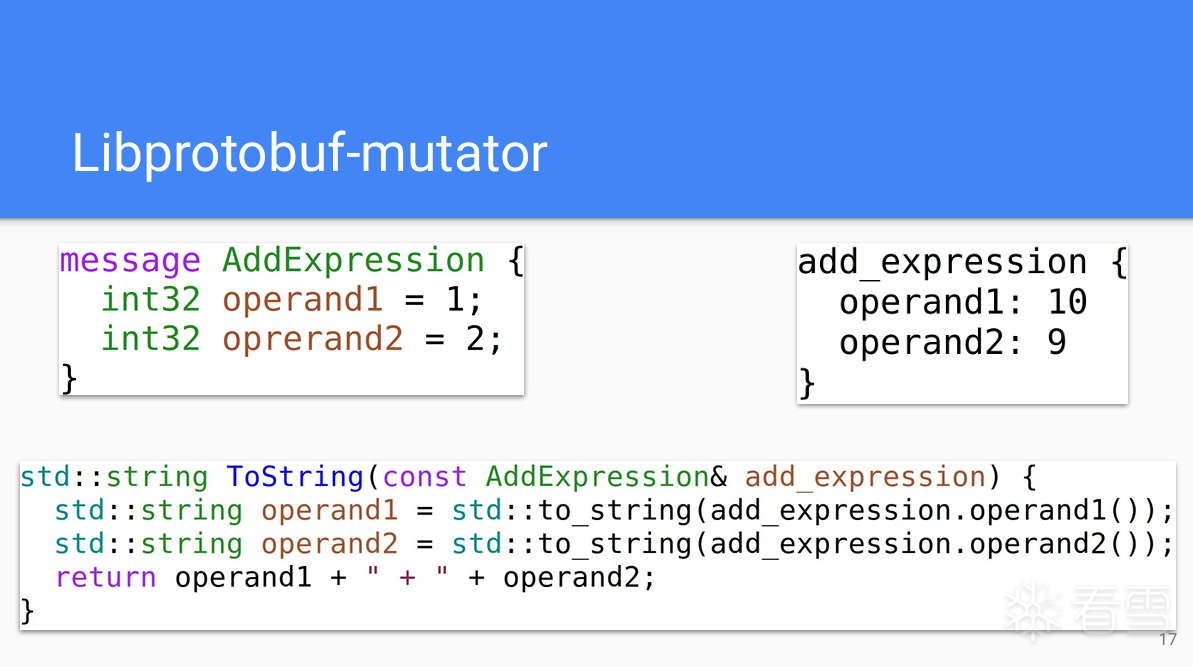
更多【外文翻译-【BlackHat】结构化模糊测试,议题学习】相关视频教程:www.yxfzedu.com
相关文章推荐
- 网络-工业自动化工厂PLC远程控制网关物联网应用 - 其他
- react.js-React Native自学笔记 - 其他
- android-【Android】Lombok for Android Studio 离线插件 - 其他
- android-Android Studio新建项目下载依赖慢,只需一个操作解决 - 其他
- 后端-使用 Ruby 的 Nokogiri 库来解析 - 其他
- 编程技术-一、配置环境 - 其他
- 算法-03 矩阵与线性变换 - 其他
- android-Android Studio(控件常用属性) - 其他
- 编程技术-ES使用ik分词器查看分词结果及自定义词汇 - 其他
- asp.net-asp.net水资源检测系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio - 其他
- 编程技术-jQuery中遍历元素each - 其他
- 编程技术-rabbitmq下载安装教程 - 其他
- 编程技术-Codeforces Round 908 - 其他
- 编程技术-Leetcode543. 二叉树的直径 - 其他
- 机器学习-IBM Qiskit量子机器学习速成(一) - 其他
- 编程技术-3D模型格式转换工具HOOPS Exchange如何获取模型的特征树? - 其他
- 编程技术-电脑出现“此驱动器存在问题请立即扫描”该怎么办? - 其他
- metersphere-社区分享|杭银消费金融基于MeterSphere开展接口自动化测试 - 其他
- uni-app-【uniapp】签名组件,兼容vue2vue3 - 其他
- 编程技术-【自然语言处理】基于python的问答系统实现 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- 华为-漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案
- 架构-LoRaWAN物联网架构
- clickhouse-【总结卡】clickhouse数据库常用高级函数
- java-深入理解ClickHouse跳数索引
- 小程序-小程序发成绩
- 运维-墨者学院 Ruby On Rails漏洞复现第一题(CVE-2018-3760)
- 企业安全-2023数字安全产业大会丨华云安应邀参加“数说安全”中原论坛
- fpga开发-「Verilog学习笔记」多功能数据处理器
- 前端-TypeScript深度剖析:TypeScript 中枚举类型应用场景?
- java-Failure to find org.apache.maven.plugins:maven-resources- plugin:jar:3.8.1