golang-线程池详解并使用Go语言实现 Pool
推荐 原创写在前面
在线程池中存在几个概念:
核心线程数、最大线程数、任务队列。
- 核心线程数指的是线程池的基本大小;也就是指worker的数量
- 最大线程数指的是,同一时刻线程池中线程的数量最大不能超过该值;实际上就是指task任务的数量。
- 任务队列是当任务较多时,线程池中线程的数量已经达到了核心线程数,这时候就是用任务队列来存储我们提交的任务。相当于缓冲作用。
与其他池化技术不同的是,线程池是基于生产者-消费者模式来实现的,任务的提交方是生产者,线程池是消费者 。当我们需要执行某个任务时,只需要把任务扔到线程池中即可。
池化技术:这里的池化和卷积的池化不一样,这里的池化技术简单点来说,就是提前保存大量的资源,以备不时之需
线程池中执行任务的流程如下图如下。
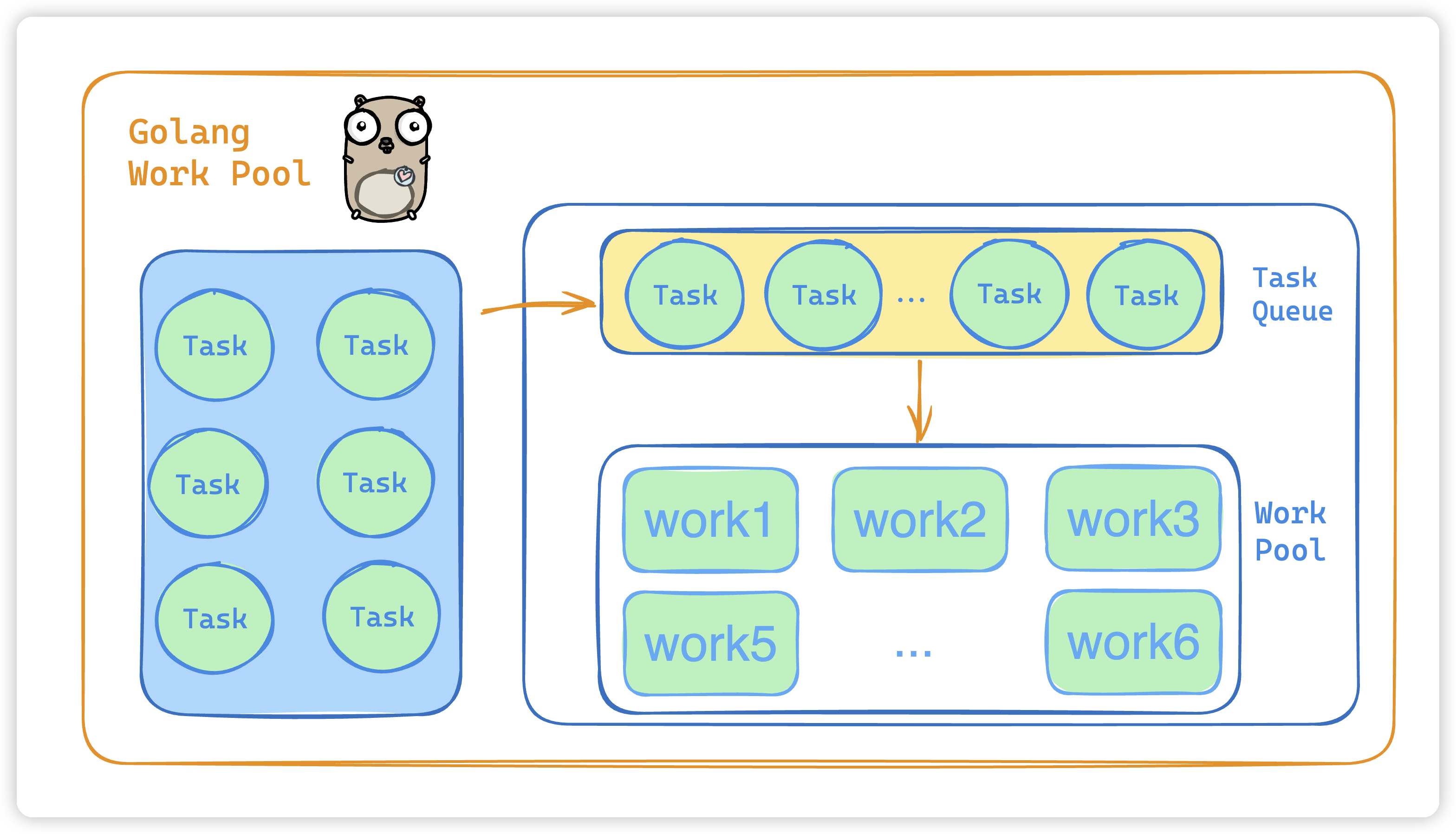
那么使用线程池可以带来一系列好处:
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可
立即执行。 - 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。
任务调度
首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
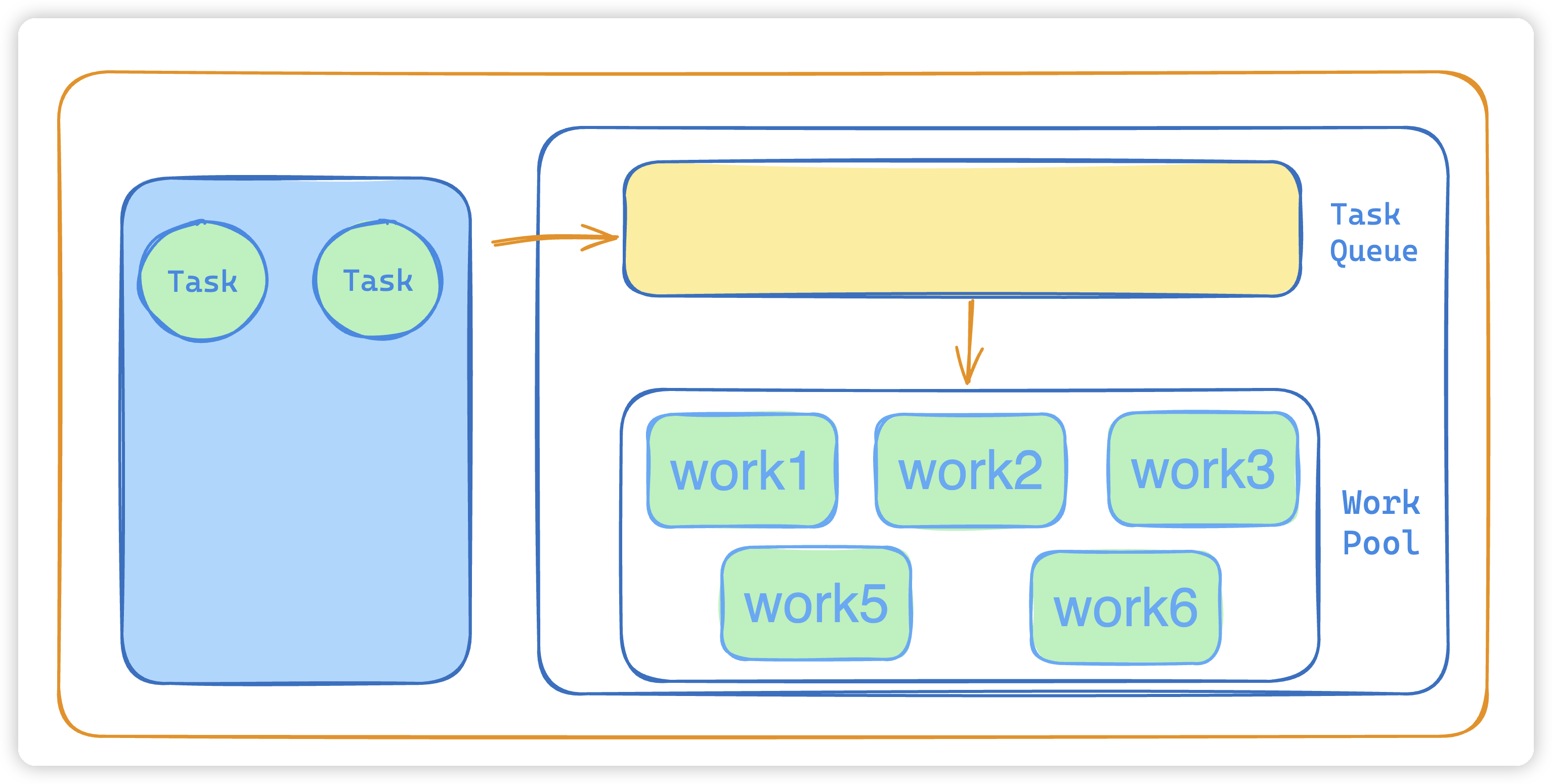
- 如果 taskCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
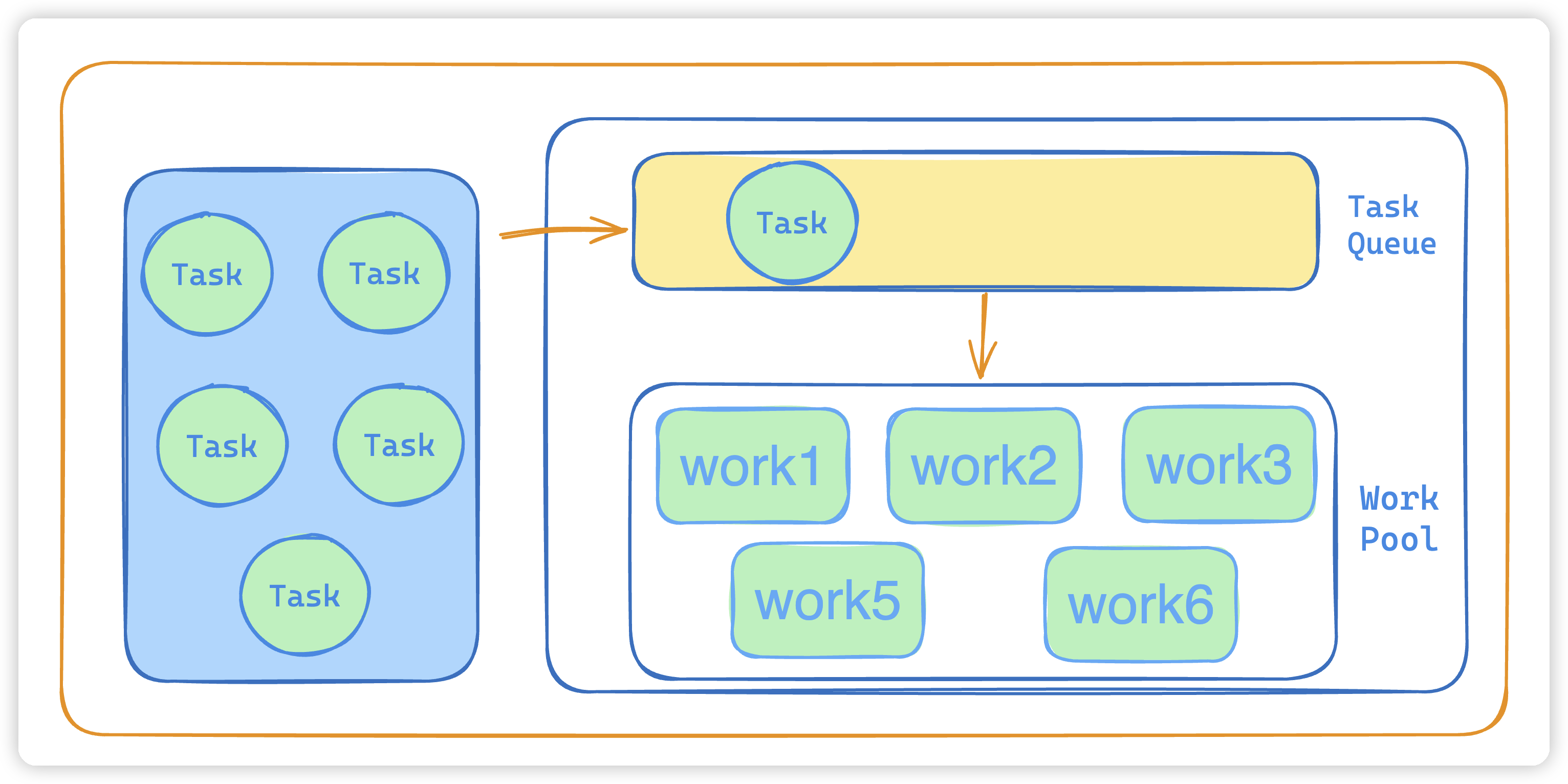
- 如果 taskCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
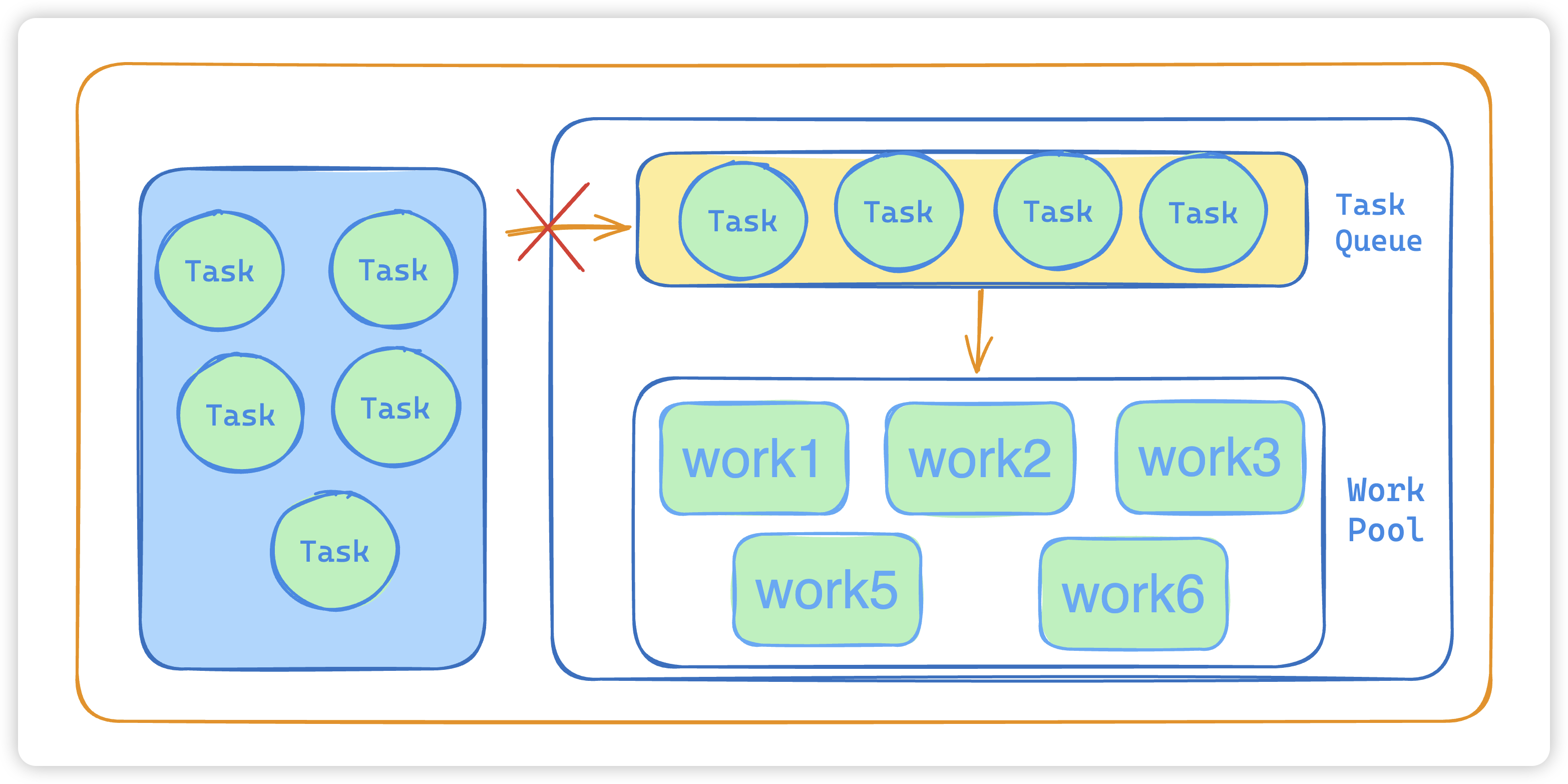
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据 拒绝策略 来处理该任务, 默认的处理方式是直接抛异常。
常见的拒绝策略有以下几种
- AbortPolicy 中止策略:丢弃任务并
抛出异常。- DiscardPolicy 丢弃策略:丢弃任务,但是
不抛出异常。如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃。- DiscardOldestPolicy 弃老策略:丢弃队列最前面的任务,然后重新提交被拒绝的任务。
简单实现
定义任务Task 并 定义NewTask来新建Task对象
type Task struct {
f func() error
}
func NewTask(f func() error) *Task {
return &Task{f: f}
}
定义 WorkPool 线程池
type WorkPool struct {
TaskQueue chan *Task // Task队列
workNum int // 协程池中最大的worker数量
shop chan struct{} // 停止工作标识
}
创建 WorkPool 的函数
func NewWorkPool(cap int) *WorkPool {
if cap <= 0 {
cap = 10
}
return &WorkPool{
TaskQueue: make(chan *Task),
workNum: cap,
shop: make(chan struct{}),
}
}
具体的协程池中的工作节点
func (p *WorkPool) worker(workId int) {
for task := range p.TaskQueue {
err := task.Execute()
if err != nil {
fmt.Println(err)
continue
}
fmt.Printf(" work id %d finished \n", workId) // 打印出具体是哪个节点进行工作
}
}
协程池启动函数
func (p *WorkPool) run() {
// 根据work num 去创建worker工作
for i := 0; i < p.workNum; i++ {
go p.worker(i)
}
<-p.shop
}
协程池关闭函数
func (p *WorkPool) close() {
p.shop <- struct{}{}
}
测试一下,使用定时器,每2秒进行一次投放,并且投放超过5个之后开始停止。
func TestWorkPool(t *testing.T) {
task := NewTask(func() error {
fmt.Print(time.Now())
return nil
})
taskCount := 0
ticker := time.NewTicker(2 * time.Second)
p := NewWorkPool(3)
go func(c *time.Ticker) {
for {
p.TaskQueue <- task
<-c.C
taskCount++
if taskCount == 5 {
p.close()
break
}
}
return
}(ticker)
p.run()
}
结果:
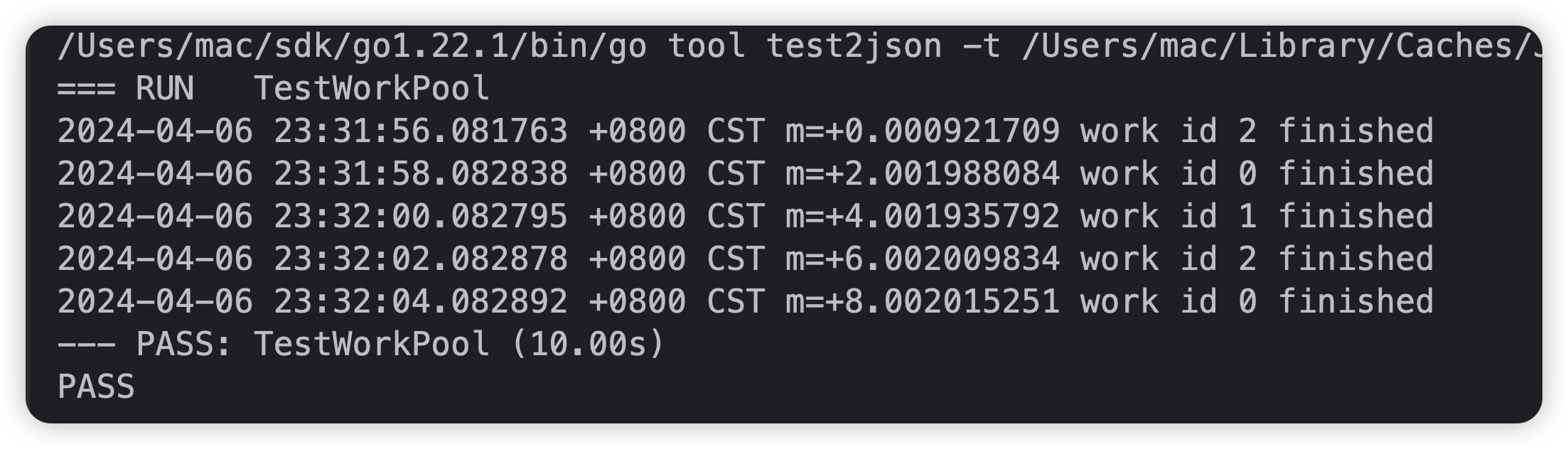
可以看到结果是每两秒进行一次打印,并且worker对象都不一样。
完整代码
package gorountine_pool
import (
"fmt"
"testing"
"time"
)
func TestWorkPool(t *testing.T) {
task := NewTask(func() error {
fmt.Print(time.Now())
return nil
})
taskCount := 0
ticker := time.NewTicker(2 * time.Second)
p := NewWorkPool(3)
go func(c *time.Ticker) {
for {
p.TaskQueue <- task
<-c.C
taskCount++
if taskCount == 5 {
p.close()
break
}
}
return
}(ticker)
p.run()
}
type Task struct {
f func() error
}
func NewTask(f func() error) *Task {
return &Task{f: f}
}
// Execute 执行业务方法
func (t *Task) Execute() error {
return t.f()
}
type WorkPool struct {
TaskQueue chan *Task // task队列
workNum int // 携程池中最大的worker数量
shop chan struct{} // 停止标识
}
// 创建Pool的函数
func NewWorkPool(cap int) *WorkPool {
if cap <= 0 {
cap = 10
}
return &WorkPool{
TaskQueue: make(chan *Task),
workNum: cap,
shop: make(chan struct{}),
}
}
func (p *WorkPool) worker(workId int) {
// 具体的工作
for task := range p.TaskQueue {
err := task.Execute()
if err != nil {
fmt.Println(err)
continue
}
fmt.Printf(" work id %d finished \n", workId)
}
}
// 携程池开始工作
func (p *WorkPool) run() {
// 根据work num 去创建worker工作
for i := 0; i < p.workNum; i++ {
go p.worker(i)
}
<-p.shop
}
func (p *WorkPool) close() {
p.shop <- struct{}{}
}
参考链接
[1] https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
[2] https://blog.csdn.net/weixin_44688301/article/details/123292211
[3] https://www.bilibili.com/video/BV1Nf4y137na
更多【golang-线程池详解并使用Go语言实现 Pool】相关视频教程:www.yxfzedu.com
相关文章推荐
- java-Maven的总结 - 其他
- 学习-【Azure 架构师学习笔记】-Azure Storage Account(5)- Data Lake layers - 其他
- 人工智能-高校为什么需要大数据挖掘平台? - 其他
- 数码相机-立体相机标定 - 其他
- java-java计算 - 其他
- python-前端面试题 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何合并多次的本地提交进行 Push - 其他
- 音视频-中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载 - 其他
- node.js-npm install:sill idealTree buildDeps - 其他
- 编辑器-vscode 访问本地或者远程docker环境 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何找回被 Drop Commit 的提交记录 - 其他
- 算法-力扣第1035题 不相交的线中等 c++ (最长公共子序列) 动态规划 附Java代码 - 其他
- java-JavaWeb课程复习资料——idea创建JDBC - 其他
- python-Python---列表的循环遍历,嵌套 - 其他
- python-Python的版本如何查询? - 其他
- java-IDEA 函数下边出现红色的波浪线,提示报错 - 其他
- 算法-算法通关村第八关|白银|二叉树的深度和高度问题【持续更新】 - 其他
- 算法-C现代方法(第19章)笔记——程序设计 - 其他
- git-IntelliJ Idea 撤回git已经push的操作 - 其他
- c#-html导出word - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- 安全-赛宁网安入选国家工业信息安全漏洞库(CICSVD)2023年度技术组成员单
- jvm-深入理解JVM虚拟机第二十四篇:详解JVM当中的动态链接和常量池的作用
- 编程技术-ROS 通信机制
- 聚类-无监督学习的集成方法:相似性矩阵的聚类
- layui-layui 表格(table)合计 取整数
- Android安全-肉丝的r0env2022(kali linux)配置xrdp远程桌面,以及Genymotion安卓11的ssh登陆问题和11系统amr64转译问题.
- Android安全-字节某条设备注册算法分析
- 编程技术-SysWhispers3学习
- 软件逆向-x64内核实验7.1补充-句柄表
- 编程技术-rt-hwwb前端面试题