python-win10 环境下Python 3.8按装fastapi paddlepaddle 进行图片文字识别1
推荐 原创###按装
用conda 创建python 3.8的环境,可参看本人python下的其它文章。
在pycharm开发环境下按装相关的模块:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastapi
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "uvicorn[standard]"
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple
pip install shapely -i https://mirror.baidu.com/pypi/simple
###开发代码:
# 导入requests库,用于发送HTTP请求
import requests
# 导入FastAPI库,用于构建高性能的Web应用程序
from fastapi import FastAPI
# 导入PaddleOCR及其draw_ocr方法,PaddleOCR是一个使用PaddlePaddle深度学习框架的OCR工具
from paddleocr import PaddleOCR, draw_ocr
# 导入BytesIO,用于在内存中处理二进制流
from io import BytesIO
# 导入PIL库中的Image模块,用于处理图像
from PIL import Image
import os
# 初始化PaddleOCR实例,配置使用方向分类器、不使用GPU、识别中文
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, lang="ch")
# 创建一个FastAPI应用实例
app = FastAPI()
# 定义一个异步的GET请求处理函数,路径为"/",接收一个名为url的查询参数
@app.get("/")
async def root(url: str):
try:
# 使用requests库发送GET请求,获取指定URL的图片,stream=True表示以流的形式下载大文件
response = requests.get(url, stream=True)
# 如果HTTP请求返回的状态码不是200,则引发HTTPError异常
response.raise_for_status()
# 检查响应头中的content-type是否包含'image',以确认返回的内容是图片
if 'image' not in response.headers.get('content-type', ''):
# 如果不是图片,返回错误信息,HTTP状态码为400(Bad Request)
return {
"error": "The provided URL does not point to an image."}, 400
# 使用BytesIO将响应内容转换为二进制流
image_bytes = BytesIO(response.content)
# 使用PIL库打开二进制流中的图像
image = Image.open(image_bytes)
# 将图像保存到临时文件中(这里是为了适应PaddleOCR可能需要文件路径的API)
# 注意:这里的代码实际上有一个逻辑错误,因为image.save()应该放在with语句块内以确保文件正确关闭
temp_image_path = "temp_image.jpg"
with open(temp_image_path, "wb") as image_file:
image.save(image_file, format='JPEG')
# 调用PaddleOCR的ocr方法进行OCR处理,cls=True表示使用分类器
result = ocr.ocr(temp_image_path, cls=True)
if os.path.exists(temp_image_path):
os.remove(temp_image_path)
results = []
# 遍历最外层的列表
for item in result:
# 遍历内层的列表
for sub_item in item:
# 提取文本和可能性
text = sub_item[1][0] # 文本位于第二个子列表的第一个位置
probability = sub_item[1][1] # 可能性位于第二个子列表的第二个位置
# 将提取的文本和可能性作为一个元组添加到结果列表中
results.append((text, probability))
# 返回OCR处理结果,封装在message字段中(注意:这里没有删除临时文件,可能会导致磁盘空间被占用)
return {
"message": results}
except requests.exceptions.RequestException as e:
# 如果在发送HTTP请求过程中发生异常,捕获异常并返回错误信息,HTTP状态码为500(Internal Server Error)
return {
"error": f"An error occurred while downloading the image: {
str(e)}"}, 500
except Exception as e:
# 如果在处理过程中发生其他类型的异常,同样捕获异常并返回错误信息,HTTP状态码为500
return {
"error": f"An error occurred during OCR processing: {
str(e)}"}, 500
在网上找一张图片:
https://img-s-msn-com.akamaized.net/tenant/amp/entityid/BB1ifoqa.img?w=768&h=662&m=6
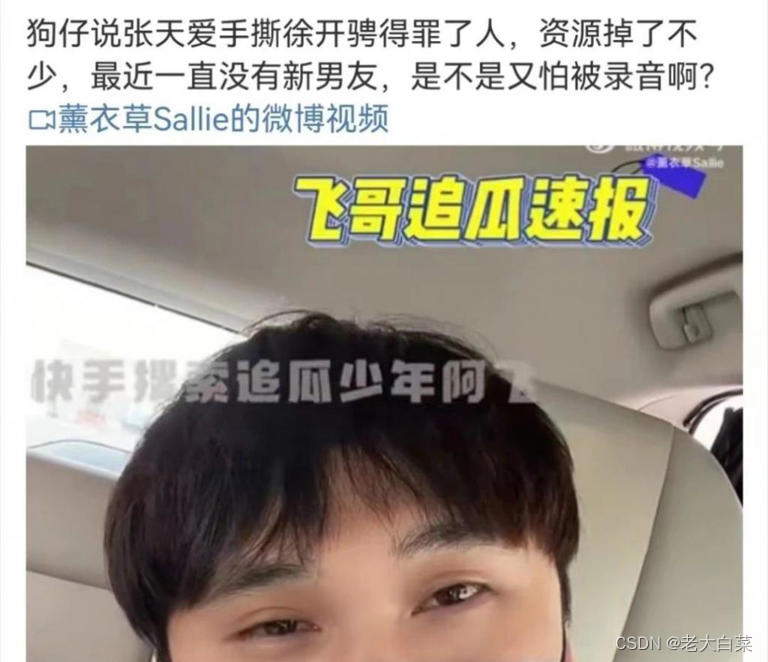
运行代码:
uvicorn main:app --reload
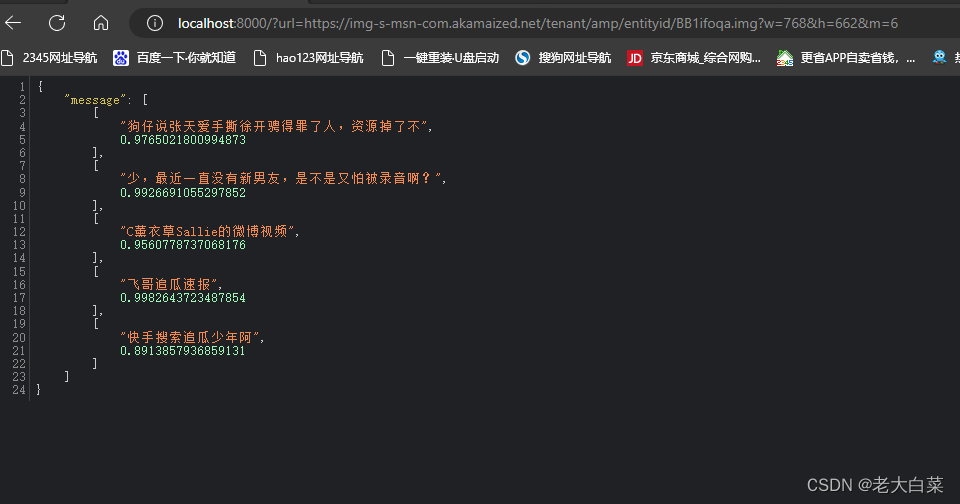
返回结果:
{
"message": [
[
"狗仔说张天爱手撕徐开骋得罪了人,资源掉了不",
0.9765021800994873
],
[
"少,最近一直没有新男友,是不是又怕被录音啊?",
0.9926691055297852
],
[
"C薰衣草Sallie的微博视频",
0.9560778737068176
],
[
"飞哥追瓜速报",
0.9982643723487854
],
[
"快手搜索追瓜少年阿",
0.8913857936859131
]
]
}
更多【python-win10 环境下Python 3.8按装fastapi paddlepaddle 进行图片文字识别1】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-Halcon WPF 开发学习笔记(2):Halcon导出c#脚本 - 其他
- mysql-【MySQL】视图 - 其他
- 编程技术-1994-2021年分行业二氧化碳排放量数据 - 其他
- 编程技术-SFTP远程终端访问 - 其他
- spring-【Spring】SpringBoot配置文件 - 其他
- 算法-“目标值排列匹配“和“背包组合问题“的区别和leetcode例题详解 - 其他
- java-一个轻量级 Java 权限认证框架——Sa-Token - 其他
- 运维-RK3568平台 查看内存的基本命令 - 其他
- 算法-深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明 - 其他
- apache-Apache Doris 是什么 - 其他
- list-Redis数据结构七之listpack和quicklist - 其他
- css-HTML CSS JS 画的效果图 - 其他
- python-Win10系统下torch.cuda.is_available()返回为False的问题解决 - 其他
- python-定义无向加权图,并使用Pytorch_geometric实现图卷积 - 其他
- git-如何使用git-credentials来管理git账号 - 其他
- prompt-Anaconda Powershell Prompt和Anaconda Prompt的区别 - 其他
- python-Dhtmlx Event Calendar 付费版使用 - 其他
- gpt-ChatGPT、GPT-4 Turbo接口调用 - 其他
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- junit-Lua更多语法与使用 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- java-IDEA 函数下边出现红色的波浪线,提示报错
- 算法-算法通关村第八关|白银|二叉树的深度和高度问题【持续更新】
- 算法-C现代方法(第19章)笔记——程序设计
- git-IntelliJ Idea 撤回git已经push的操作
- c#-html导出word
- excel-使用 AIGC ,ChatGPT 快速合并Excel工作薄
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载
- 编程技术-鲁大师电动车智能化测评报告第二十三期:实测续航95km,九号Q90兼顾个性与实用
- 数据库-进阶SQL——数据表中多列按照指定格式拼接,并将多行内容合并为map拼接
- 小程序-社区团购小程序系统源码+各种快递代收+社区便利店 带完整的搭建教程
