语言模型-NLP_神经概率语言模型(NPLM)
推荐 原创NPLM的起源
在NPLM之前,传统的语言模型主要依赖于最基本的N-Gram技术,通过统计词汇的共现频率来计算词汇组合的概率。然而,这种方法在处理稀疏数据和长距离依剌时遇到了困难。
NPLM 是一种将词汇映射到连续向量空间的方法,其核心思想是利用神经网络学习词汇的概率分布。和N-Gram一样,NPLM 通过利用前N-1个词来预测第N个词,但是NPLM 构建了一个基于神经网络的语言模型。与传统的N-Gram 语言模型相比 NPLM 优化参数和预测第N个词的方法更加复杂。
得益于神经网络的强大表达能力,NPLM能够更有效地处理稀疏数据和长距离依赖问题。这意味着,NPLM在面对罕见词汇和捕捉距离较远的词之间的依赖关系时表现得更加出色,相较于传统的N-Gram语言模型有着显著的优势。
如下图所示,NPLM的结构包括3个主要部分:输入层、隐藏层和输出层。输入层将词汇映射到连续的词向量空间,隐藏层通过非线性激活函数学习词与词之间的复杂关系,输出层通过softmax函数产生下一个单词的概率分布。
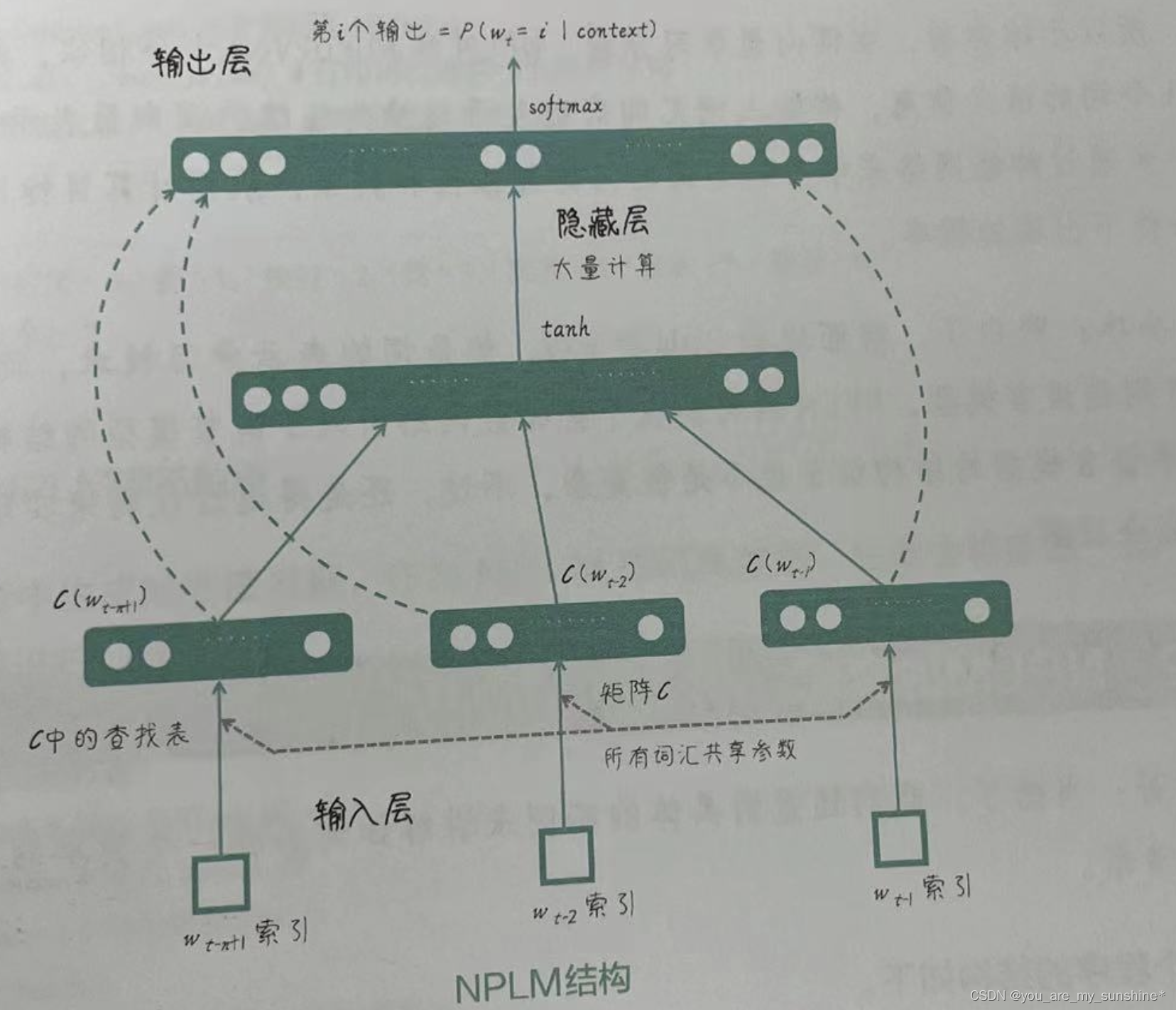
NPLM的实现
流程如下:
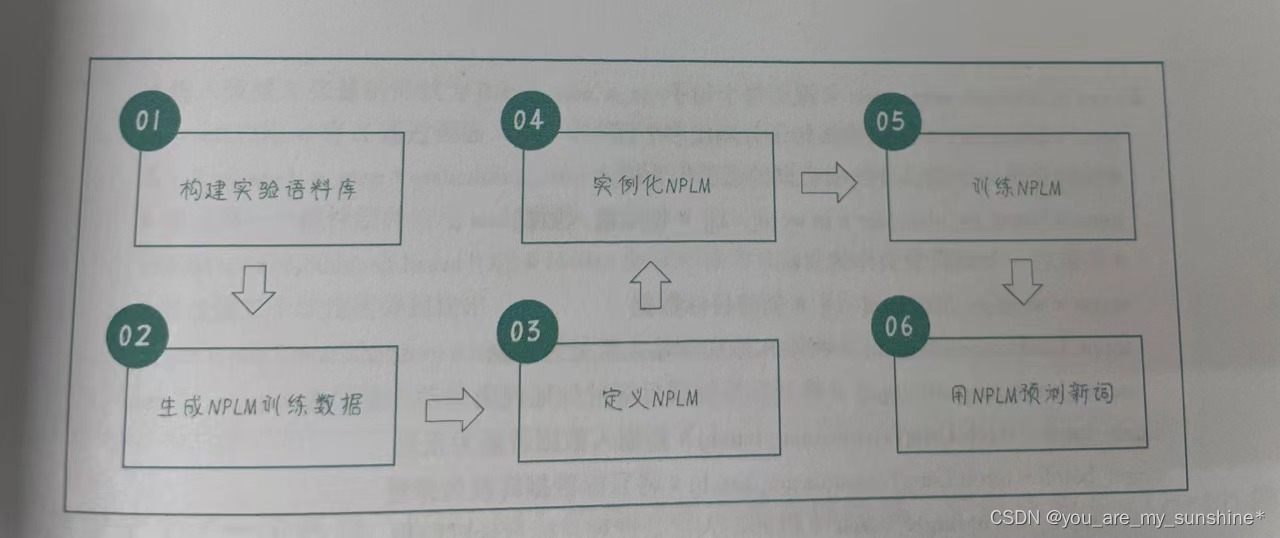
1.构建实验语料库
# 构建一个非常简单的数据集
sentences = ["我 喜欢 玩具", "我 爱 爸爸", "我 讨厌 挨打"]
# 将所有句子连接在一起,用空格分隔成多个词,再将重复的词去除,构建词汇表
word_list = list(set(" ".join(sentences).split()))
# 创建一个字典,将每个词映射到一个唯一的索引
word_to_idx = {
word: idx for idx, word in enumerate(word_list)}
# 创建一个字典,将每个索引映射到对应的词
idx_to_word = {
idx: word for idx, word in enumerate(word_list)}
voc_size = len(word_list) # 计算词汇表的大小
print(' 词汇表:', word_to_idx) # 打印词汇到索引的映射字典
print(' 词汇表大小:', voc_size) # 打印词汇表大小

2.生成NPLM训练数据
# 构建批处理数据
import torch # 导入 PyTorch 库
import random # 导入 random 库
batch_size = 2 # 每批数据的大小
def make_batch():
input_batch = [] # 定义输入批处理列表
target_batch = [] # 定义目标批处理列表
selected_sentences = random.sample(sentences, batch_size) # 随机选择句子
for sen in selected_sentences: # 遍历每个句子
word = sen.split() # 用空格将句子分隔成多个词
# 将除最后一个词以外的所有词的索引作为输入
input = [word_to_idx[n] for n in word[:-1]] # 创建输入数据
# 将最后一个词的索引作为目标
target = word_to_idx[word[-1]] # 创建目标数据
input_batch.append(input) # 将输入添加到输入批处理列表
target_batch.append(target) # 将目标添加到目标批处理列表
input_batch = torch.LongTensor(input_batch) # 将输入数据转换为张量
target_batch = torch.LongTensor(target_batch) # 将目标数据转换为张量
return input_batch, target_batch # 返回输入批处理和目标批处理数据
input_batch, target_batch = make_batch() # 生成批处理数据
print(" 输入批处理数据:",input_batch) # 打印输入批处理数据
# 将输入批处理数据中的每个索引值转换为对应的原始词
input_words = []
for input_idx in input_batch:
input_words.append([idx_to_word[idx.item()] for idx in input_idx])
print(" 输入批处理数据对应的原始词:",input_words)
print(" 目标批处理数据:",target_batch) # 打印目标批处理数据
# 将目标批处理数据中的每个索引值转换为对应的原始词
target_words = [idx_to_word[idx.item()] for idx in target_batch]
print(" 目标批处理数据对应的原始词:",target_words)

3.定义NPLM
import torch.nn as nn # 导入神经网络模块
# 定义神经概率语言模型(NPLM)
class NPLM(nn.Module):
def __init__(self):
super(NPLM, self).__init__()
self.C = nn.Embedding(voc_size, embedding_size) # 定义一个词嵌入层
# 第一个线性层,其输入大小为 n_step * embedding_size,输出大小为 n_hidden
self.linear1 = nn.Linear(n_step * embedding_size, n_hidden)
# 第二个线性层,其输入大小为 n_hidden,输出大小为 voc_size,即词汇表大小
self.linear2 = nn.Linear(n_hidden, voc_size)
def forward(self, X): # 定义前向传播过程
# 输入数据 X 张量的形状为 [batch_size, n_step]
X = self.C(X) # 将 X 通过词嵌入层,形状变为 [batch_size, n_step, embedding_size]
X = X.view(-1, n_step * embedding_size) # 形状变为 [batch_size, n_step * embedding_size]
# 通过第一个线性层并应用 ReLU 激活函数
hidden = torch.tanh(self.linear1(X)) # hidden 张量形状为 [batch_size, n_hidden]
# 通过第二个线性层得到输出
output = self.linear2(hidden) # output 形状为 [batch_size, voc_size]
return output # 返回输出结果
这里定义了一个名为“NPLM”的神经概率语言模型类,它继承自PyTorch的 nn.Module。在这个类中,我们定义了词嵌入层和线性层,如下所示。
- self.C:一个词嵌入层,用于将输入数据中的每个词转换为固定大小的向量表 3
示。voc_size 表示词汇表大小,embedding_size 表示词嵌入的维度。 - self.linear1:第一个线性层,不考虑批次的情况下输入大小为n_step * embedding_size,输出大小为n_hidden。n_step表示时间步数,即每个输入序列的长度;embedding_size表示词嵌入的维度;n_hidden 表示隐藏层的大小。
- self.linear2:第二个线性层,不考虑批次的情况下输入大小为n_hidden,输出大小为voc_size。n_hidden表示隐藏层的大小,voc_size 表示词汇表大小。
在NPLM 类中,我们还定义了一个名为forward 的方法,用于实现模型的前向传播过程。在这个方法中,首先将输入数据通过词嵌入层self.C,然后X.view(-1, n_step * embedding_size)的目的是在词嵌入维度上展平张量,也就是把每个输入序列的词嵌入串联起来,形成一个大的向量。接着,将该张量传入第一个线性层 self. linear1并应用tanh函数,得到隐藏层的输出。最后,将隐藏层的输出传入第二个线性层 self.linear2,得到最终的输出结果。
4.实例化NPLM
n_step = 2 # 时间步数,表示每个输入序列的长度,也就是上下文长度
n_hidden = 2 # 隐藏层大小
embedding_size = 2 # 词嵌入大小
model = NPLM() # 创建神经概率语言模型实例
print(' NPLM 模型结构:', model) # 打印模型的结构

5.训练NPLM
import torch.optim as optim # 导入优化器模块
criterion = nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.1) # 定义优化器为 Adam,学习率为 0.1
# 训练模型
for epoch in range(5000): # 设置训练迭代次数
optimizer.zero_grad() # 清除优化器的梯度
input_batch, target_batch = make_batch() # 创建输入和目标批处理数据
output = model(input_batch) # 将输入数据传入模型,得到输出结果
loss = criterion(output, target_batch) # 计算损失值
if (epoch + 1) % 1000 == 0: # 每 1000 次迭代,打印损失值
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
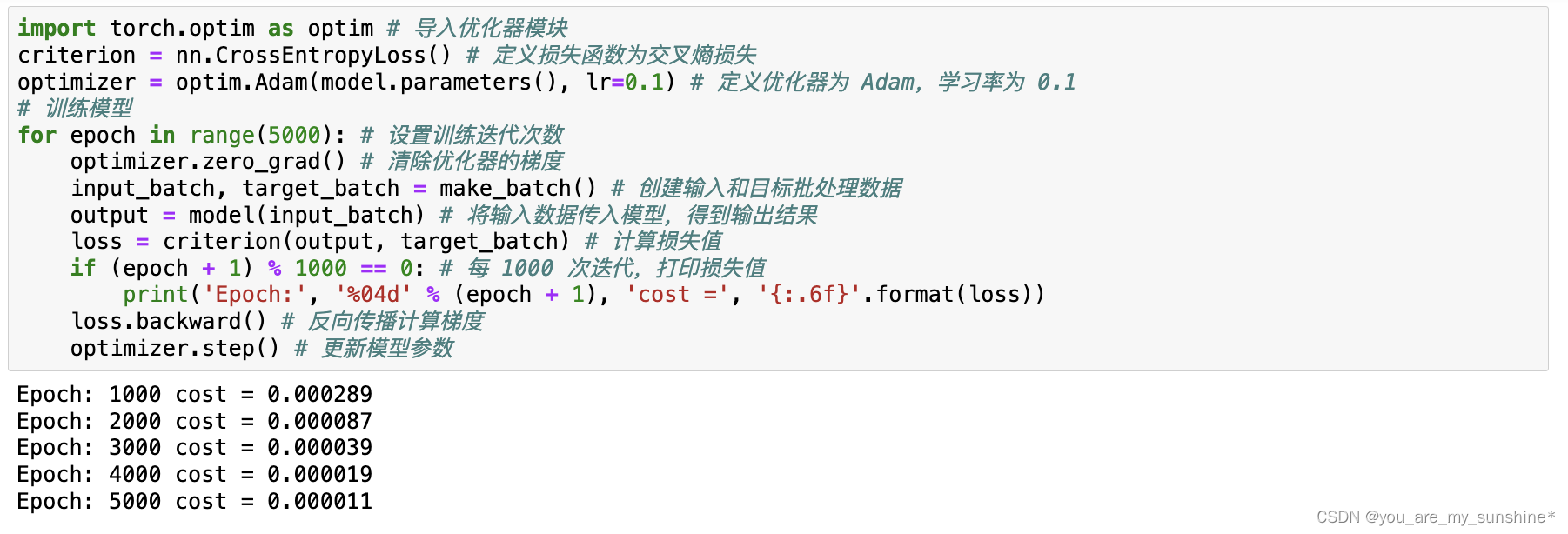
在训练过程中,首先定义损失函数(交叉熵损失函数)和优化器(Adam)。接下来,进行5000次迭代训练,每次迭代中,首先清除优化器的梯度,然后生成输入和目标批处理数据,并将它们转换为张量。接着,将输入数据传入模型,模型进行推理,得到预测值。随后,我们将预测值和目标数据进行比较,计算损失值,执行反向传播和参数更新。每1000 次迭代后,打印当前的损失值——可以看到损失值逐渐减少。
上面这个过程,是非常标准的PyTorch深度学习模型的训练过程。
6.用NPLM预测新词
# 进行预测
input_strs = [['我', '讨厌'], ['我', '喜欢']] # 需要预测的输入序列
# 将输入序列转换为对应的索引
input_indices = [[word_to_idx[word] for word in seq] for seq in input_strs]
# 将输入序列的索引转换为张量
input_batch = torch.LongTensor(input_indices)
# 对输入序列进行预测,取输出中概率最大的类别
predict = model(input_batch).data.max(1)[1]
# 将预测结果的索引转换为对应的词
predict_strs = [idx_to_word[n.item()] for n in predict.squeeze()]
for input_seq, pred in zip(input_strs, predict_strs):
print(input_seq, '->', pred) # 打印输入序列和预测结果

至此,一个完整的神经网络语言模型已经搭建完成。这个语言模型的输入是一个句子的前N-1个单词,输出是第N个单词。神经网络包括一个嵌入层,后面跟着一个使用 tanh 激活的线性层。程序使用交叉熵损失函数和Adam 优化器进行训练。最后的线性输出层给出词汇表中所有单词作为下一个单词的概率分布,我们通常选择概率最高的那个单词作为预测的下一个单词。此处在计算交叉熵损失时使用了softmax函数。
NPLM是一种较为简单的神经网络语言模型,它的历史意义在于开创性地把神经网络技术引入了 NLP领域。从此开始,深度学习就登上了 NLP 的舞台。而深度学习在NPLM中的优势主要体现在以下几方面。
- 可以自动学习复杂的特征表示,减少了手工特征工程的需求。
- 可以对大量数据进行高效的处理,使得模型能通过大规模语料库更好地学习词与词之间的语义和语法关系。
- 具有强大的拟合能力,可以捕捉到语言数据中的复杂结构和模式。
具体到 NPLM 本身来说,它也存在一些明显的不足之处。
- 模型结构简单:NPLM 使用了线性层和激活函数进行前向传播,这使得模型的表达能力受到限制。对于复杂的语言模式和长距离依赖关系,NPLM 可能无法捕捉到足够的信息。
- 窗口大小固定:NPLM使用窗口大小固定的输入序列,这限制了模型处理不同长度上下文的能力。在实际应用中,语言模型通常需要处理长度可变的文本数据。
- 缺乏长距离依赖捕捉:由于窗口大小固定,NPLM无法捕捉长距离依赖。在许多 NLP 任务中,捕捉长距离依赖关系对于理解句子结构和语义具有重要意义。
- 训练效率低:NPLM的训练过程中,全连接层的输出大小等于词汇表的大小。当词汇表非常大时,计算量会变得非常大,导致训练效率降低。
- 词汇表固定:NPLM 在训练时使用固定词汇表,这意味着模型无法处理训练集中未出现的词汇(未登录词)。这限制了模型在现实应用中的泛化能力。
- 缺乏位置信息:NPLM不考虑输入序列中单词的顺序,这可能导致模型无法捕捉序列中单词之间的顺序关系。
为了解决这些问题,研究人员提出了一些更先进的神经网络语言模型,如循环神经网络、长短期记忆网络、门控循环单元(GRU)和Transformer等。这些模型能够捕捉长距离依赖,处理变长序列,同时具有更强的表达能力和泛化能力。下面我们就继续讲解 NLP 发展史上的另外一个里程碑——循环神经网络的使用。这里多说一句,其实LSTM和 GRU 都是广义上的循环神经网络。
NPLM小结
NPLM是一种基于神经网络的语言模型,用于估计语言序列的概率分布。它通过学习上下文中的词来预测下一个词,其主要思想是将单词转换为向量形式,并使用这些向量来训练一个神经网络。
优势:
在面对罕见词汇和捕捉距离较远的词之间的依赖关系时表现得更加出色,相较于传统的N-Gram语言模型有着显著的优势。
劣势:
窗口大小固定、缺乏长距离依赖捕捉、在训练时使用固定词汇表
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
更多【语言模型-NLP_神经概率语言模型(NPLM)】相关视频教程:www.yxfzedu.com
相关文章推荐
- 网络-网络安全与TikTok:年轻一代的数字素养 - 其他
- 安全-安全防御——四、防火墙理论知识 - 其他
- 网络-网络安全和隐私保护技术 - 其他
- 安全-webgoat-Security Logging Failures安全日志记录失败 - 其他
- 笔记-【动手学深度学习】课程笔记 05-07 线性代数、矩阵计算和自动求导 - 其他
- 安全-水利部加快推进小型水库除险加固,大坝安全监测是重点 - 其他
- 微服务-Java版分布式微服务云开发架构 Spring Cloud+Spring Boot+Mybatis 电子招标采购系统功能清单 - 其他
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 - 其他
- 安全-iPortal如何灵活设置用户名及密码的安全规则 - 其他
- 集成测试-如何使用 Loadgen 来简化 HTTP API 请求的集成测试 - 其他
- yolo-基于YOLOv8与DeepSORT实现多目标跟踪——算法与源码解析 - 其他
- 编程技术-【机器学习】Kmeans聚类算法 - 其他
- 集成学习-【Python机器学习】零基础掌握RandomForestRegressor集成学习 - 其他
- java-LeetCode //C - 373. Find K Pairs with Smallest Sums - 其他
- 集成学习-【Python机器学习】零基础掌握StackingClassifier集成学习 - 其他
- 编程技术-如何提高企业竞争力?CRM管理系统告诉你 - 其他
- java-Java - Hutool 获取 HttpRequest:Header、Body、ParamMap 等利器 - 其他
- c++-C++特殊类与单例模式 - 其他
- 编辑器-vscode git提交 - 其他
- 前端-WebGL的技术难点分析 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo)
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析
- CTF对抗-Hack-A-Sat 2020预选赛 beckley
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 4 动态链接
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 3 静态链接
- CTF对抗-22年12月某春秋赛题-Random_花指令_Chacha20_RC4
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 2 ELF文件格式
- Pwn-从NCTF 2022 ezshellcode入门CTF PWN中的ptrace代码注入
